【Keras-VGG】CIFAR-10
系列连载目录
- 请查看博客 《Paper》 4.1 小节 【Keras】Classification in CIFAR-10 系列连载
学习借鉴
- github:BIGBALLON/cifar-10-cnn
- 知乎专栏:写给妹子的深度学习教程
参考
- 【Keras-CNN】CIFAR-10
- 本地远程访问Ubuntu16.04.3服务器上的TensorBoard
代码下载
- 链接:https://pan.baidu.com/s/1JBQJQ9ZbFGSqmoW_4r9BaA
提取码:3tv3
硬件
- TITAN XP
文章目录
- 1 Introduction
- 1.1 CIFAR-10
- 1.2 VGG
- 2 Code
- 3 结果分析
- 4 调试下hyper parameters
- 5 对比下经典的 vgg16、vgg13、vgg11
- 6 探讨下 Weight Initialization
- 7 VGG 显存占用情况
1 Introduction
1.1 CIFAR-10
CIFAR-10 是由Alex Krizhevsky、Vinod Nair 与 Geoffrey Hinton 收集的一个用于图像识别的数据集,60000个32*32的彩色图像,50000个training data,10000个 test data 有10类,飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车,每类6000张图。与MNIST相比,色彩、颜色噪点较多,同一类物体大小不一、角度不同、颜色不同。

1.2 VGG
VGG是Visual Geometry Group 这个实验室发明的,所以就叫VGG了(给妹纸的深度学习教学(3)——用VGG19开荒)。我们一般说 VGG 指的是 VGG-16。
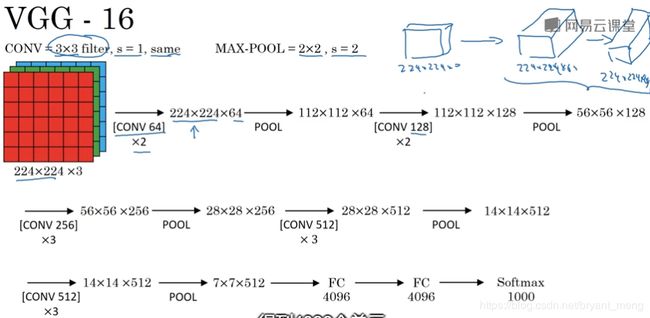
下图最后一列就是 VGG-19的结构,本篇文章就来实现它的 Keras 版本
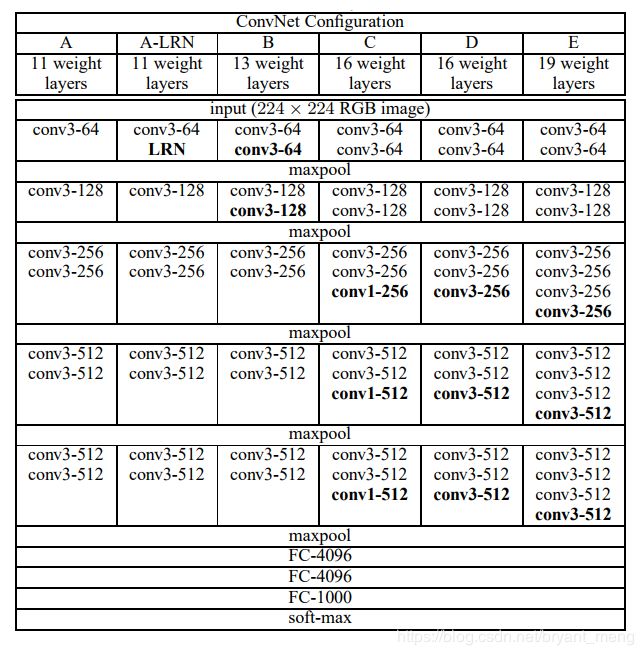
图片来源于 《Very deep convolutional networks for large-scale image recognition》
Total params: 39,002,738
Trainable params: 38,975,326
Non-trainable params: 27,412
Trainable params,Non-trainable params 是 Batch Normalization 的原因,参考 【Keras-NIN】CIFAR-10 的 2.2.1 小节计算。
2 Code
1)导入必要的库,设置好 hyper-parameters
import keras
import numpy as np
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D, AveragePooling2D
from keras.initializers import he_normal
from keras import optimizers
from keras.callbacks import LearningRateScheduler, TensorBoard
from keras.layers.normalization import BatchNormalization
from keras.utils.data_utils import get_file
num_classes = 10
batch_size = 128
epochs = 200
iterations = 391
dropout = 0.5
weight_decay = 0.0001
log_filepath = r'./vgg19_pretrain/'
??? log_filepath 多了一个 r,哈哈,python中的正则表达式中经常会有 r 这个字符,这是因为有时候匹配正则表达式中,有时候会有斜线 \ ,没有 r,就要写2个 \ \ ,有 r ,只要写一个 \ 。(来自 python之r的作用)
2)载入数据集,进行数据预处理(减均值,除以标准差)
# data loading
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# data preprocessing
x_train[:,:,:,0] = (x_train[:,:,:,0]-123.680)
x_train[:,:,:,1] = (x_train[:,:,:,1]-116.779)
x_train[:,:,:,2] = (x_train[:,:,:,2]-103.939)
x_test[:,:,:,0] = (x_test[:,:,:,0]-123.680)
x_test[:,:,:,1] = (x_test[:,:,:,1]-116.779)
x_test[:,:,:,2] = (x_test[:,:,:,2]-103.939)
3)training schedule(learning rate 的设置)
def scheduler(epoch):
if epoch <= 80:
return 0.01
if epoch <= 140:
return 0.005
return 0.001
4)下载 ImageNet 训练模型
# download
WEIGHTS_PATH = 'https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg19_weights_tf_dim_ordering_tf_kernels.h5'
filepath = get_file('vgg19_weights_tf_dim_ordering_tf_kernels.h5', WEIGHTS_PATH, cache_subdir='models')
也可以手动下载咯 https://github.com/fchollet/deep-learning-models/releases , 放在 /your_home/.keras/models/ 目录下,有 500 MB +
5)构建 VGG-19 网络
# build model
model = Sequential()
# Block 1
model.add(Conv2D(64, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block1_conv1', input_shape=x_train.shape[1:]))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block1_conv2'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool'))
# Block 2
model.add(Conv2D(128, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block2_conv1'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(128, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block2_conv2'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool'))
# Block 3
model.add(Conv2D(256, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block3_conv1'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(256, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block3_conv2'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(256, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block3_conv3'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(256, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block3_conv4'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool'))
# Block 4
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block4_conv1'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block4_conv2'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block4_conv3'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block4_conv4'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool'))
# Block 5
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block5_conv1'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block5_conv2'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block5_conv3'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(512, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='block5_conv4'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool'))
# model modification for cifar-10
model.add(Flatten(name='flatten'))
model.add(Dense(4096, use_bias = True, kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='fc_cifa10'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(dropout))
model.add(Dense(4096, kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='fc2'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(dropout))
model.add(Dense(10, kernel_regularizer=keras.regularizers.l2(weight_decay),
kernel_initializer=he_normal(), name='predictions_cifa10'))
model.add(BatchNormalization())
model.add(Activation('softmax'))
# load pretrained weight from VGG19 by name
model.load_weights(filepath, by_name=True)
# 如果是手动下载的话, filepath替换成 “下载的路径+文件名”
# model.load_weights('/root/.keras/models/vgg19_weights_tf_dim_ordering_tf_kernels.h5',by_name=True)
# 如果不要预训练模型的话,注释掉这句话即可
# -------- optimizer setting -------- #
sgd = optimizers.SGD(lr=.1, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
6)开始训练
tb_cb = TensorBoard(log_dir=log_filepath, histogram_freq=0)
change_lr = LearningRateScheduler(scheduler)
cbks = [change_lr,tb_cb]
print('Using real-time data augmentation.')
datagen = ImageDataGenerator(horizontal_flip=True,
width_shift_range=0.125,height_shift_range=0.125,fill_mode='constant',cval=0.)
datagen.fit(x_train)
model.fit_generator(datagen.flow(x_train, y_train,batch_size=batch_size),
steps_per_epoch=iterations,
epochs=epochs,
callbacks=cbks,
validation_data=(x_test, y_test))
7)保存模型
model.save('vgg19_pretrain.h5')
3 结果分析
第二节的 code 是 vgg19_pretrain 的,如下三个模型都在 FC 层处用了 drop out
| 减均值除以方差 | weight decay | he_normal | ImageNet 预训练 | BN | data augmentation | |
|---|---|---|---|---|---|---|
| vgg19_pretrain | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| vgg19 | ✔ | ✔ | ✔ | - | ✔ | ✔ |
| vgg19_no_trick | ✔ | - | ✔ | - | - | - |
kernel_initializer 如果不设置,默认为 'glorot_uniform',本博客实验代码都采用 he_normal
he_normal 官网的解释如下:normal distribution centered on 0 with s t d d e v = s q r t ( 2 / f a n _ i n ) stddev = sqrt(2 / fan\_in) stddev=sqrt(2/fan_in) where f a n _ i n fan\_in fan_in is the number of input units in the weight tensor.
更多关于 keras 的初始化方法可以查看 https://keras-cn.readthedocs.io/en/latest/other/initializations/
training accuracy 和 training loss
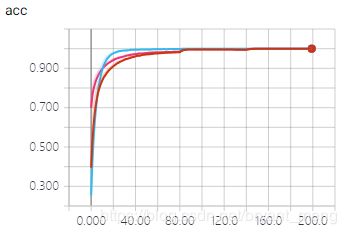


test accuracy 和 test loss

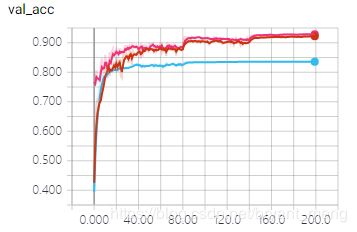

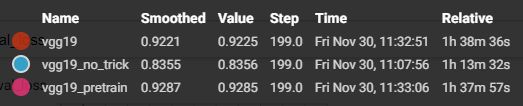
结论:VGG19_pretrain 最猛,可以看出有 ImageNet 预训练模型,测试的时候,一开始就在一个很高的水平
真可谓 “条条道路通罗马,有人出生在罗马” 啊(毒鸡汤)
4 调试下hyper parameters
以 weight decay 为例,也就是 L2 regularization 的系数 λ \lambda λ
vgg19_pretrain 的 weight decay 为 0.0001,其它三个模型的 weight_decay 如模型名字所示
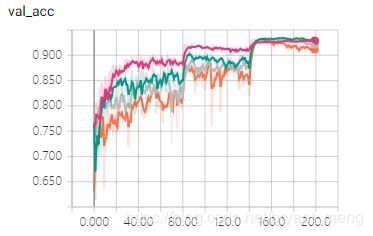

可以发现迭代到 200 个 epoch的时候, vgg19_pretrain 最好,但是看上面的测试集精度图可以发现,vgg19_pretrain_0.0005 有比 vgg19_pretrain 辉煌的时候。峰值大概在 93.4%


5 对比下经典的 vgg16、vgg13、vgg11
来试一下上图中的 A、B、C、D 模型,其他设定和 vgg19 (也就是上图的模型 E)一样,也就是说,也加数据预处理(减均值除以标准差),数据增强(水平翻转,平移),weight decay = 0.0001,he_normal,dropout,BN,hyper parameters 的设定也都一样。不用预训练模型(哈哈,因为懒得去找,而且效果差距不会太大 https://github.com/fchollet/deep-learning-models/releases )。
Total params = Trainable params + Non-trainable params
| Network | Parameters(包含BN) |
|---|---|
| VGG11_A | 28,187,826 = 28,165,918 + 21,908 |
| VGG13_B | 28,373,106 = 28,350,814 + 22,292 |
| VGG16_C | 28,969,330 = 28,944,478 + 24,852 |
| VGG16_D | 33,687,922 = 33,663,070 + 24,852 |
| VGG19(VGG19_E) | 39,002,738 = 38,975,326 + 27,412 |
-
training accuracy 和 training loss

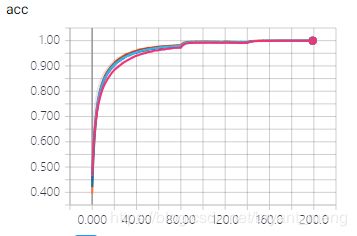
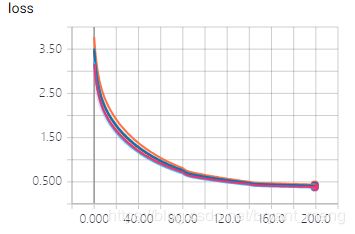
-
test accuracy 和 test loss
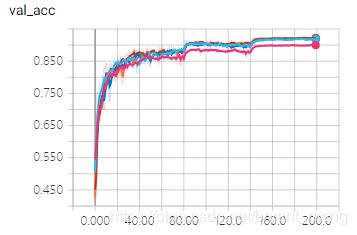

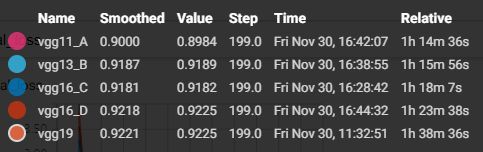
可以看到,在 CIFAR-10 数据集上,vgg19表现要略胜一筹,BCD模型也不甘示弱,相对来说,vgg11_A 稍逊风骚。
模型的大小

留下一个疑问?
Q1:如果训练网络的时候用了预训练模型,那么在搭建网络的时候,还需要初始化设计吗?
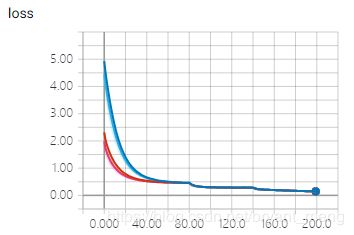
6 探讨下 Weight Initialization
keras 自带的权重初始化方法如下 https://keras-cn.readthedocs.io/en/latest/other/initializations/#initializer
我们来实验一下
- vgg19_pretrain_0.0005:
he_normal - vgg19_pretrain_0.0005_no_wi:替换
he_normal,用Conv2D 默认的初始化方法'glorot_uniform' - vgg19_pretrain_0.0005_normal_wi:替换
he_normal,用keras.initializers.RandomNormal(),默认的均值和方差是多少占时还不知道,留一个疑问 - vgg19_pretrain_0.0005_normal_wi_parameters:替换
he_normal,用keras.initializers.RandomNormal(mean=0.0, stddev=0.01)
以上四种方法都采用了预训练模型

- training accuracy 和 training loss

- test accuracy 和 test loss
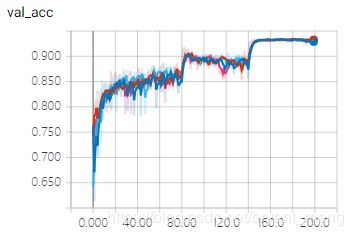
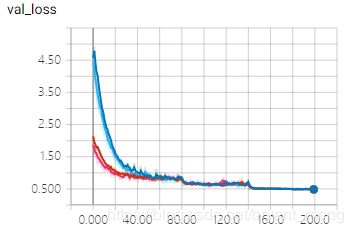
最终都差不多,伯仲之间


哈哈,其实是这一节纯粹是无聊滴,因为如果加载预训练模型的话,会覆盖原来的初始化!
7 VGG 显存占用情况
转载:https://zhuanlan.zhihu.com/p/35186462
1)GPU memory = parameters memory + layer outputs memory
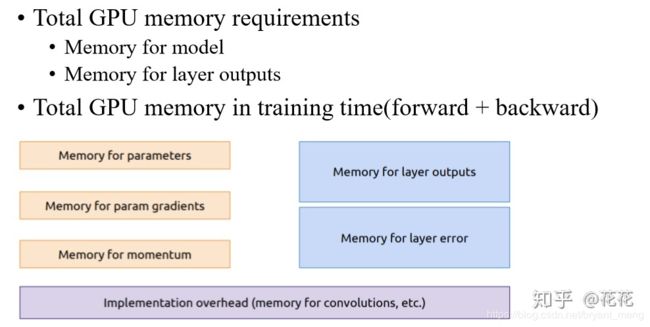
2)parameters memory 和 layer outputs memory 的计算
3)GPU memory = parameters memory × 3 + layer outputs memory × batch size × 2
- 3 表示 params、SGD、momentum
- 2 表示 forward 和 backward
