深度强化学习实战:Tensorflow实现DDPG - PaperWeekly 第48期
作者丨李国豪
学校丨中国科学院大学&上海科技大学
研究方向丨无人驾驶,强化学习
指导老师丨林宝军教授
1. 前言
本文主要讲解 DeepMind 发布在 ICLR 2016 的文章 Continuous control with deep reinforcement learning,时间稍微有点久远,但因为算法经典,还是值得去实现。
2. 环境
这次实验环境是 Openai Gym 的 Pendulum-v0,state 是 3 维连续的表示杆的位置方向信息,action 是 1 维的连续动作,大小是 -2.0 到 2.0,表示对杆施加的力和方向。目标是让杆保持直立,所以 reward 在杆保持直立不动的时候最大。笔者所用的环境为:
Tensorflow (1.2.1)
gym (0.9.2)
请先安装 Tensorflow 和 gym,Tensorflow 和 gym 的安装就不赘述了,下面是网络收敛后的结果。
class="video_iframe" data-vidtype="2" allowfullscreen="" frameborder="0" data-ratio="1" data-w="272" data-src="http://v.qq.com/iframe/player.html?vid=y1325jlix3j&width=650&height=487.5&auto=0" style="display: block; width: 650px !important; height: 487.5px !important;" width="650" height="487.5" data-vh="487.5" data-vw="650" src="http://v.qq.com/iframe/player.html?vid=y1325jlix3j&width=650&height=487.5&auto=0"/>
3. 代码详解
先贴一张 DeepMind 文章中的伪代码,分析一下实现它,我们需要实现哪些东西:

4. 网络结构(model)
首先,我们需要实现一个 critic network 和一个 actor network,然后再实现一个 target critic network 和 target actor network,并且对应初始化为相同的 weights。下面来看看这部分代码怎么实现:
critic network & target critic network

上面是 critic network 的实现,critic network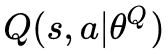 是一个用神经网络去近似的一个函数,输入是 s-state,a-action,输出是 Q 函数,网络参数是
是一个用神经网络去近似的一个函数,输入是 s-state,a-action,输出是 Q 函数,网络参数是 ,在这里我的实现和原文类似,state 经过一个全连接层得到隐藏层特征 h1,action 经过另外一个全连接层得到隐藏层特征 h2,然后特征串联在一起得到 h_concat,之后 h_concat 再经过一层全连接层得到 h3,最后 h3 经过一个没有激活函数的全连接层得到 q_output。这就简单得实现了一个 critic network。
,在这里我的实现和原文类似,state 经过一个全连接层得到隐藏层特征 h1,action 经过另外一个全连接层得到隐藏层特征 h2,然后特征串联在一起得到 h_concat,之后 h_concat 再经过一层全连接层得到 h3,最后 h3 经过一个没有激活函数的全连接层得到 q_output。这就简单得实现了一个 critic network。

上面是target critic network的实现,target critic network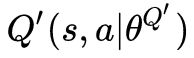 网络结构和 critic network 一样,也参数初始化为一样的权重,思路是先把 critic network 的权重取出来初始化,再调用一遍 self.__create_critic_network() 创建 target network,最后把 critic network 初始化的权重赋值给 target critic network。
网络结构和 critic network 一样,也参数初始化为一样的权重,思路是先把 critic network 的权重取出来初始化,再调用一遍 self.__create_critic_network() 创建 target network,最后把 critic network 初始化的权重赋值给 target critic network。
这样我们就得到了 critic network 和 critic target network。
actor network & actor target network
actor network![]() 和 actor target network
和 actor target network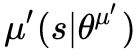 的实现与 critic 几乎一样,区别在于网络结构和激活函数。
的实现与 critic 几乎一样,区别在于网络结构和激活函数。


这里用了 3 层全连接层,最后激活函数是 tanh,把输出限定在 -1 到 1 之间。这样大体的网络结构就实现完了。
5. Replay Buffer & Random Process(Mechanism)
接下来,伪代码提到 replay buffer 和 random process,这部分代码比较简单也很短,主要参考了 openai 的 rllab 的实现,大家可以直接看看源码。
6. 网络更新和损失函数(Model)
用梯度下降更新网络,先需要定义我们的 loss 函数。
critic nework 更新
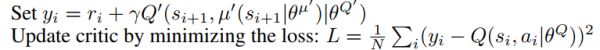

这里 critic 只是很简单的是一个 L2 loss。不过由于 transition 是 s, a, r, s'。要得到 y 需要一步处理,下面是预处理 transition 的代码。

训练模型是,从 Replay buffer 里取出一个 mini-batch,在经过预处理就可以更新我们的网络了,是不是很简单。y 经过下面这行代码处理得到。
![]()
actor nework更新
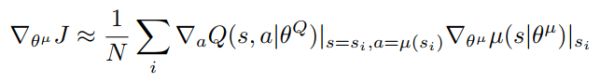
actor network 的更新也很简单,我们需要求的梯度如上图,首先我们需要critic network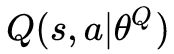 对动作 a 的导数,其中 a 是由 actor network 根据状态 s 估计出来的。代码如下:
对动作 a 的导数,其中 a 是由 actor network 根据状态 s 估计出来的。代码如下:
![]()
![]()
先根据 actor network 估计出 action,再用 critic network 的输出 q 对估计出来的 action 求导。
然后我们把得到的这部分梯度,和 actor network 的输出对 actor network 的权重求导的梯度,相乘就能得到最后的梯度,代码如下:

也就是说我们需要求的 policy gradient 主要由下面这一行代码求得,由于我们需要梯度下降去更新网络,所以需要加个负号:
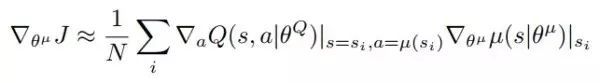
![]()
之后就是更新我们的 target network,target network 采用 soft update 的方式去稳定网络的变化,算法如下:
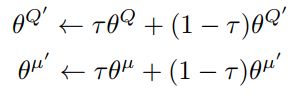

就这样我们的整体网络更新需要的东西都实现了,下面是整体网络更新的代码:

总体的细节都介绍完了,希望大家有所收获。另外,完整代码已放出,大家可以点击“阅读原文”访问我的 Github。
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看完整代码