用 TensorRT 进行高性能前向推理
用 TensorRT 进行高性能前向推理
- Tensorflow-TensorRT 优化的三个阶段
- 示例
- 控制 TensorRT 引擎中 Node 的最小个数
- 变量输入形状
- TensorRT 引擎缓存和变量 Batch Sizes
- 使用 INT8 精度进行推理
- Tensorflow-TensorRT 应用的调试和分析(profiling)工具
- 算法是否在使用 Tensor Cores?
- 性能和 Benchmarking 脚本
- 下一步
- 总结
本博客原文地址为:https://medium.com/tensorflow/high-performance-inference-with-tensorrt-integration-c4d78795fbfe
去年英伟达提出了 TensorRT 前向推理框架,用于加速 GPU 端的深度学习前向推理。这篇文章将深入介绍 TensorRT 并分享一些使用技巧,这样您的应用能拥有更佳的性能。通过这篇文章,您能了解到:
- TensorRT 所支持的模型,以及融合的工作流程;
- 一些新的技术,如使用 INT8 精度来量化训练;
- 一些研究分析技术,用于评价模型表现;
- 新的试验特性,以及未来的发展趋势;
Tensorflow-TensorRT 优化的三个阶段
模型一旦训练好,就可以部署,执行前向推理。在 Tensorflow Github 上,你能找到不少预训练好的深度学习模型。这些模型都使用了最新的 Tensorflow APIs,并且不断地更新。尽管你也可以使用 Tensorflow 本身来进行前向推理,但是在GPU上使用 TensorRT 通常能获得更优的表现。用 TensorRT 优化过的 Tensorflow 模型可以部署在 T4 GPUs 上,也可以部署在 Jetson Nano 和 Xavier GPU 上。
那么 TensorRT 到底有何神奇之处呢?英伟达 TensorRT 是一个高效率的推理优化器,在 GPU 上以低精度(FP16 和 INT8)进行前向推理。它和 Tensorflow 的融合使得我们用 TensorRT 来优化 Tensorflow 模型,仅需几行代码。相较于仅使用 Tensorflow,在 Tensorflow 环境中结合 TensorRT 使用,你能至多提升8倍的性能。对于 TensorRT 支持的操作,它可以对之进行优化,而对不支持的操作则不进行改动,仍继续用 Tensorflow 来执行。在 Nvidia NGC Tensorflow container 中,始终有对融合方案版本进行的更新。
融合方案可以应用在目标检测,翻译,推荐系统和增强学习等各种模型 app 中。我们提供了很多模型的准确率,包括 MobileNet, NASNet, Inception 以及 ResNet 等,并且经常更新。
如果你已安装融合方案,并且有一个训练好的 Tensorflow 模型,你可以将它以保存的模型格式转出。融合方案然后在 Tensorflow 所支持的子计算图上使用 TensorRT 来优化。输出仍是一个 Tensorflow 计算图,但是它所支持的子计算图已经被替换为 TensorRT 优化引擎,然后被 Tensorflow 执行。仅在 Tensorflow 中执行前向推理的工作流程如下:
使用 savedmodel 格式,Tensorflow-TensorRT 的工作流程则如下:

其代码则是:
import tensorflow.contrib.tensorrt as trt
trt.create_inference_graph(
input_saved_model_dir = input_saved_model_dir,
output_saved_model_dir = output_saved_model_dir
)
将 Tensorflow 模型转出用于推理的另一个方法就是,冻结训练好的模型的计算图,用于前向计算。下方的图表和代码片段展示了如何在 Tensorflow 计算图上使用 TensorRT 进行优化。输出仍然是一个 Tensorflow 计算图,TensorRT 优化引擎对它支持的子计算图进行替换,然后再用 Tensorflow 运行。下图分别是仅使用 Tensorflow 进行推理的流程,以及 Tensorflow-TensorRT 使用冻结计算图的流程:
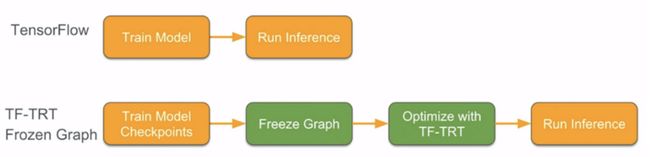
import tensorflow.contrib.tensorrt as trt
converted_graph_def = trt.create_inference_graph(
input_graph_def = frozen_graph,
outputs = ['logits', 'classes']
)
我们列了一组融合方案所支持的运算操作。
在上述流程的优化阶段,需要执行三步操作:
- 计算图分割。TensorRT 扫描整个 Tensorflow 计算图,找寻其中它可以进行优化的子计算图。
- 层转换。将每个子计算图中 TensorRT 支持的 Tensorflow 层转换为 TensorRT 层。
- 引擎优化。最后,将 Tensorflow 子计算图转换为 TensorRT 引擎,并在原 Tensorflow 计算图中将其替换。
下面我们来看一个例子。
示例
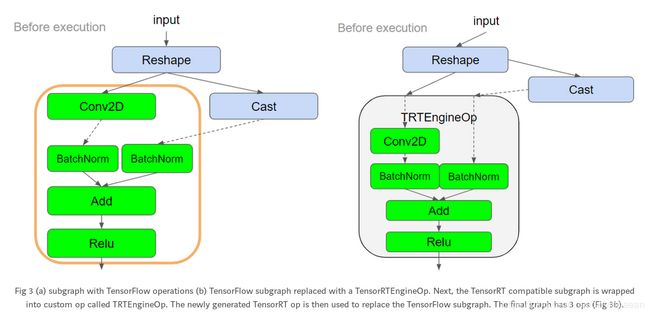
我们以下面的的计算图为例。绿色模块代表 TensorRT 支持的计算操作,灰色模块代表不支持的操作(“Cast”)。
图(a) 中,TensorRT 支持的 nodes 为绿色,图(b) 橙色框内的四个操作是用于优化的子计算图,图© 中只加了一个 Conv2D 操作,还没有添加 loop,图(d) 添加了 Reshape 操作到子计算图中,但是这样就造成了一个 loop,所以图(e) 中创建了两个子计算图来解决 loop 问题。
 优化的第一阶段将 Tensorflow 计算图分割为 TensorRT 兼容的子计算图,和 TensorRT 不兼容的子计算图。我们从后往前遍历整个计算图,以 ReLU 操作开始(a),然后每次增加一个 node,让子计算图尽可能地大。唯一的约束就是,子计算图中应该是个有向非循环图 (direct acyclic graph),没有任何的 loop。图 c 即为我们所能得到的最大子计算图。Cluster 将所有的 nodes 加起来,一直到上面的 Reshape 操作。然后,那里有一个 loop(d),这样不行,就返回去。为了解决 loop 问题,我们就为它加一个新的 cluster,这样最终,我们就有两个与 TensorRT 兼容的子计算图(e)。
优化的第一阶段将 Tensorflow 计算图分割为 TensorRT 兼容的子计算图,和 TensorRT 不兼容的子计算图。我们从后往前遍历整个计算图,以 ReLU 操作开始(a),然后每次增加一个 node,让子计算图尽可能地大。唯一的约束就是,子计算图中应该是个有向非循环图 (direct acyclic graph),没有任何的 loop。图 c 即为我们所能得到的最大子计算图。Cluster 将所有的 nodes 加起来,一直到上面的 Reshape 操作。然后,那里有一个 loop(d),这样不行,就返回去。为了解决 loop 问题,我们就为它加一个新的 cluster,这样最终,我们就有两个与 TensorRT 兼容的子计算图(e)。
控制 TensorRT 引擎中 Node 的最小个数
在上面的例子中,我们生成了两个 TensorRT 优化的子计算图:一个针对 Reshape 操作,另一个针对除了 Cast 操作的所有其它操作。如果遇到小的计算图,比如它只有一个 node,我们就需要在 TensorRT 所提供的优化性能和构建及运行 TRT 引擎的代价之间进行权衡。我们可以通过 minimum_segment_size 参数来控制子计算图的大小。如果该值设为3(默认值),则那些 nodes 个数少于3个的子计算图就不会生成 TensorRT 引擎。在上面的例子中,minimum_segment_size 设为3的话,它就会忽略掉 Reshape 操作,尽管 Reshape 操作是可以用 TensorRT 来优化的,那么我们就不得不使用 Tensorflow 来进行 Reshape 操作。
converted_graph_def = create_inference_graph(
input_saved_model_dir = model_dir,
minimum_segment_size = 3,
is_dynamic_op = True,
maximum_cached_engines = 1
)
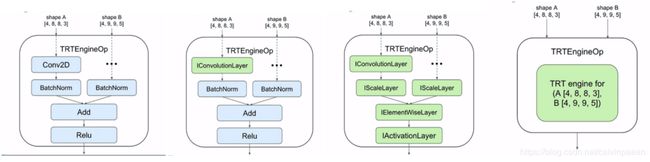
下图(a) 就是为原 Tensorflow 操作的子计算图,图(b) 就是用 TensorRTEngineOp 替换的 Tensorflow 子计算图。然后,TensorRT 兼容的子计算图被封装为一个自定义操作,称作 TRTEngineOp。新生成的 TensorRT 操作然后用于替换 Tensorflow 的子计算图。最终的计算图有3个操作(图(b))。
变量输入形状
TensorRT 通常要求模型中所有的形状都被定义,除了 batch 维度,不能有 − 1 -1 −1 或者 None。这样做是为了选取最优的 CUDA 内核。如果模型中的输入形状都被完全定义了,默认设置 is_dynamic_op=False 就可以用于静态构建 TensorRT 引擎。如果模型中的一些形状是未知的,如 BERT 和 Mask R-CNN 模型,那么你就得推迟 TensorRT 的优化,直到输入形状都被完全定义。将 is_dynamic_op 设为 true 来使用此方法。
converted_graph_def = create_inference_graph(
input_saved_model_dir = model_dir,
minimum_segment_size = 3,
is_dynamic_op = false,
maximum_cached_engines = 1
)
接下来,我们对计算图按拓扑结构的顺序进行遍历,将子计算图中的每个 Tensorflow 操作转换为一个或多个的 TensorRT 层。最终,TensorRT 通过层或 tensor 融合,低精度校准,以及卷积核 auto-tuning 进行优化。这些优化对用户来说是透明的,并且针对要进行模型推理的 GPU 来优化。
下图(a) 是转换为 TensorRT 层之前的 Tensorflow 子计算图,图(b) 中则展示了第一个Tensorflow 操作转换为了 TensorRT 层,图© 中所有的 Tensorflow 操作都转换为了 TensorRT 层,图(d) 则为最终的 TensorRT 引擎。
TensorRT 引擎缓存和变量 Batch Sizes
TRTEngineOp 操作中有一个 LRU 缓存,TensorRT 引擎可以被缓存于此。该缓存所用的 key 是运算操作输入的形状。如果缓存是空的,或者缓存中不存在特定输入形状的引擎,那么一个新的引擎就会被创建。你可以通过 maximum_cached_engines 参数来控制缓存中引擎的个数。
converted_graph_def = create_inference_graph(
input_saved_model_dir = model_dir,
is_dynamic_op = True,
maximum_cached_engines = 1
)
若该值为1,每当一个新的引擎被创建,则会将缓存中已有的缓存清空。
TensorRT 使用输入 batch size 作为选取 CUDA 核的参数之一。Batch size 是输入的第一个维度数。当 is_dynamic_op 设为 true 时,输入的形状决定 batch size,而当 is_dynamic_op 设为 false 时,max_batch_size 参数决定 batch size。对于新的输入,引擎可以被复用,如果以下条件成立:
- 引擎的 batch size 不小于新输入的 batch size,而且
- 除了 batch size,其它的维度数与新的输入相匹配;
所以在下图(a) 中,我们并不需要创建一个新的引擎,因为新的 batch size 是2,小于缓存里面的引擎 batch size 4,而其它的维度 [ 8 , 8 , 3 ] , [ 9 , 9 , 5 ] [8,8,3], [9,9,5] [8,8,3],[9,9,5]是一样的。在图(b) 中,除了 batch size,其它的维度不一样,那么我们就要创建一个新的引擎。最终,引擎的缓存结构就如图© 所示。
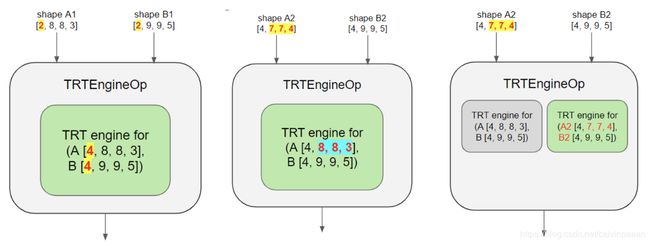
增加 maximum_cached_engines 变量来尽可能地防止重复创建引擎。缓存的引擎越多,所消耗的资源就越多,但是对于常用模型来说,一般没问题。
使用 INT8 精度进行推理
Tesla T4 GPU 引入了 Turing Tensor Core 技术,涵盖所有的精度范围,从 FP32 到 FP16 到 INT8。在 Tesla T4 GPU 上,Tensor Cores 可以进行30万亿次浮点计算(TOPS)。使用 INT8 和混合精度可以降低内存消耗,这样就跑的模型就可以更大,用于推理的 mini-batch size 可以更大。
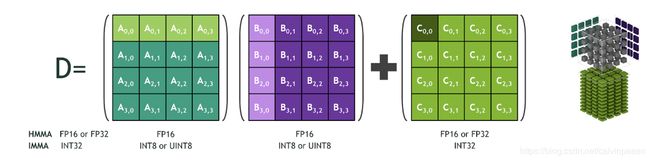
你可能会好奇,到底它是怎么将 32 bit 浮点精度降低到用 8 bit 整形表示的,32 bit 浮点精度可以表示数十亿个值,而 8 bit 整形只能表示256个值。通常在神经网络中,权重和激活函数的值都存在于一些较小的范围内。如果我们将我们珍贵的 8 bits 只关注那个范围,我们虽然会有一些舍入误差,但是也可以获得不错的精度。
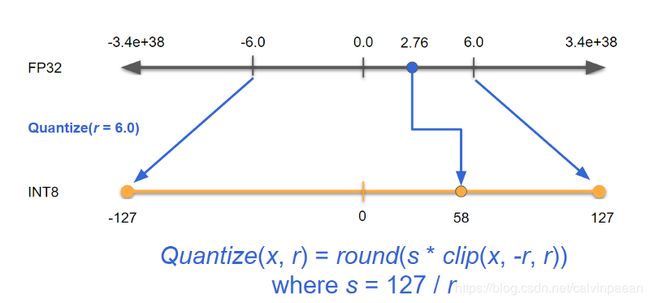
TensorRT 使用 “对称线性量化”(symmetric linear quantization) 来进行量化,该操作是一种缩放(scaling)操作,从 FP32 范围(下图 [ − 6 , 6 ] [-6, 6] [−6,6])缩放到 INT8 范围(下图 [ − 127 , 127 ] [-127, 127] [−127,127] 来保留对称关系)之内。如果我们可以找到一个范围,网络中 tensor 的绝大多数的值都存在于这个范围内,我们就可以利用这个范围来对 tensor 进行量化,而不会降低多少准确率。
Quantize(x, r) = round(s * clip(x, -r, r)) where s = 127 / r
下图中, x x x 是输入, r r r 是 tensor 的浮点范围, s s s 是 INT8 中值个数的缩放因子。下面的等式表示,对于输入 x x x,返回一个量化后的 INT8 值。
通常有两种方法来决定网络中每一个 tensor 的激活值范围:校准(calibration),量化训练(quantization aware training)。
校准是我们推荐的方法,对于大多数的模型,它造成的准确率损失都很小( < 1 % <1\% <1%)。首先我们在一个校准数据集上进行前向推理。在这一步中会记录下激活值的直方图。然后选择 INT8 量化范围来降低信息损失。在整个过程中,量化算是比较后面的步骤,它也就变成训练中新的错误原因。下方代码所执行的就是校准操作:
import tensorflow.contrib.tensorrt as trt
calib_graph = trt.create_inference_graph(...
precision_mode = 'INT8',
use_calibration = True)
with tf.session() as sess:
tf.import_graph_def(calib_graph)
for i in range(10):
sess.run('output: 0', {'input: 0': my_next_data()})
# data from calibration dataset
converted_graph_def = trt.calib_graph_to_infer_graph(calib_graph)
当使用 INT8 校准时,我们在模型训练完之后进行量化。也就是说,我们没法改变那一时刻模型中的错误率。Quantization-aware training 就是要解决这个问题,尽管这个特性仍然算是试验特性。在训练的微调步骤中,Quantization aware training 对量化错误率建模,这样在训练过程中,它就可以学到量化的范围。这样,我们的模型就可以对错误率进行补偿。和校准相比,在某些情景中这样做带来的准确率更高。
用量化 nodes 来增强计算图,然后训练模型来执行 quantization aware training。量化 nodes 对量化过程中(裁剪,缩放,四舍五入)造成的错误进行建模,使得模型能够适应这些错误。你可以使用固定的量化范围,也可以把它们变成可训练的变量。你可以用 tf.quantization.fake_quant_with_min_max_vars 以及 narrow_range=True 和 max=min 来匹配 TensorRT 的量化流程。
下图中,在 Tensorflow 计算图里插入的橙色框就是量化 nodes。
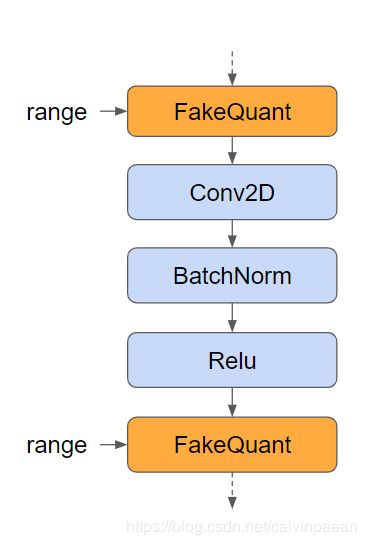
其它的改动包括 precision_mode=‘INT8’ 以及 use_calibration = false:
calib_graph_def = create_inference_graph(
input_saved_model_dir = input_saved_model_dir,
precision_mode = 'INT8',
use_calibration = False
)
这就可以从计算图中提取出量化的范围,并输出用于推理的转换后的模型。通过 fake quantization nodes 来对错误进行建模,然后利用梯度下降策略来学习量化范围。TF-TRT 会自动理解计算图上学到的量化范围,然后创建一个用于部署的,优化后的 INT8 模型。
在训练过程中,对 INT8 推理进行的建模必须要尽可能地精细。也就是说,我们不可以在推理过程中不会量化的地方(因为融合)放置一个 Tensorflow 量化 node。有一些操作如 Conv > Bias > ReLU 或者 Conv > Bias > BatchNorm > ReLU 通常会被 TensorRT 融合起来,因此我们就没法在这些操作中间插入量化 node。想要了解更多的话,可以去Quantization aware training documentation 看看。
Tensorflow-TensorRT 应用的调试和分析(profiling)工具
对于分析 Tensorflow-TensorRT 应用,我们可以找到很多现成的工具,从命令行分析工具到 GUI 工具,包括 nvprof,NVIDIA NSIGHT 系统,Tensorflow Profiler,以及 TensorBoard。最简单的就是 nvprof,它是一个命令行分析工具,可以运行在 Windows, Linux, OS X 上。它是一个轻量级分析工具,可以呈现出 GPU 核和内存的使用情况。我们可以通过以下命令来调用它:
nvprof python <your application name>
NVIDIA NSIGHT Systems 是一个系统级的性能分析工具,用于可视化应用的算法,帮助用户深入了解性能瓶颈,进而优化性能。它也可以针对各种行为以及深度学习框架(如 Tensorflow 和 PyTorch)的负载分析出有价值的信息;允许用户针对模型和参数进行调置,提升单个 GPU 和多个 GPU 使用效率。
下面我们来看一个例子,将上述两个工具一起使用,看看我们能从中得到什么样的信息。在命令行输入:
nvprof python run_inference.py
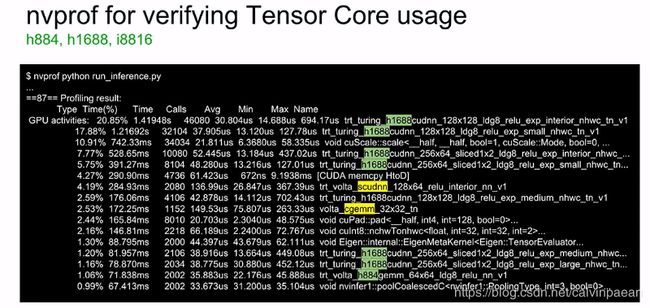
下图展示了一组按照计算时间降序排列的 CUDA 核。最上面前五个核中有四个是 TensorRT 核,即运行在 Tensor Cores 上的 GEMM 操作(下一节中介绍如何使用 Tensor Cores)。我们想要的情形就是,GEMM 操作占据这张表格中上面的位置,因为 GPU 非常擅长加速这些操作。对于非 GEMM 核的操作,我们就需要进一步研究来看看是否需要移除它们,或者优化这些操作。
下图是 NSIGHT 系统,展示了一个程序使用 GPU 的时间线。
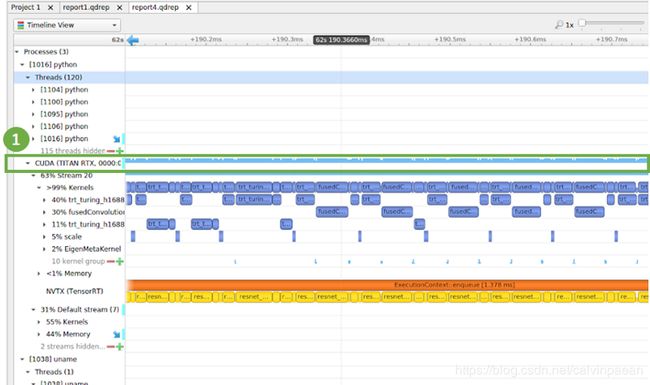
上图标注为(1) 的地方就是 CUDA 核的时间线。我们的目的就是,在这条时间线上找到最大的 gap,gap 代表的就是 GPU 在这个时间点没有进行计算。GPU 在这要么是在等数据,要么是在等某个 CPU 操作完成。因为 ResNet-50 已经优化得足够好了,我们可以看到在上图中,核间的 gap 都很小,都是微秒级的。如果图中的 gap 比较大,这就需要我们进一步研究下,是哪些操作造成了这些 gaps。在上图你也可以看到 CUDA streams 以及它们对应的 CUDA 核。黄色的对应着 TensorRT 层。
在下图中,你可以在计算时间线上发现一个 gap,表示 GPU 没有在计算。我们就需要进一步研究下。
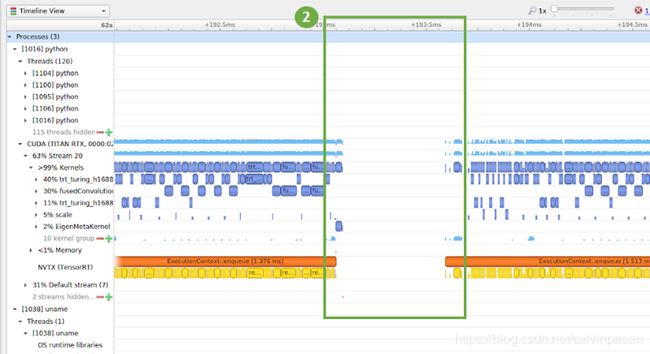
计算机视觉和自然语言处理需要这些工具来处理应用的输入。如果因为数据加载或模型本身的瓶颈束缚,导致这些应用的预处理很慢,使用上述工具可以帮助你找到模型需要优化的地方。我们经常可以看到,在 TF-TRT 上进行推理,瓶颈限制包括从硬盘中加载数据或网络(jpeg 图像或TFRecords),以及在加载到推理引擎之前对数据进行的预处理。如果数据预处理是一个瓶颈,你可以尝试使用 I/O 库来加速,如 nvidia/dali 库,使用多线程 I/O 和图像处理,以及可以在GPU 上进行图像处理。
Tensorflow Profiler 是另一个可用的工具,由 Tensorflow 自带。它将额外的参数放在 Python 脚本中,可视化 kernel 的时间信息(在GPU上跑的函数叫 kernel,核)。例子包括会话中额外的options 以及run_metadata:sess.run(res, options=options, run_metadata=run_metadata)。执行完成后,会生成一个包含分析数据的 json 文件,以 Chrome trace 的格式,可以在 Chrome 浏览器中查看。
你也可以使用 Tensorflow 日志记录功能和 Tensorboard 来查看模型的哪一部分被转换成了 TensorRT。要想使用日志功能,你需要提升 Tensorflow 日志中信息显示的级别,然后从选定的一组 C++ 文件中输出日志信息。在调试工具文档中你可以找到更多关于日志输出的信息。下面就是提升日志信息显示级别的样例代码:
TF_CPP_VMODULE = segment = 2, convert_graph = 2, convert_nodes = 2, trt_engine_op = 2 python run_inference.py
另一个可视化计算图的选项就是 Tensorboard,它是一个 Tensorflow 的可视化工具集合。Tensorboard 可以让你查看 Tensorflow 计算图,里面包含那些 nodes,哪些 Tensorflow nodes 转换为了 TensorRT nodes,哪些 nodes 附加在 TensorRT nodes 上,甚至是计算图中张量的形状。在用 Tensorboard 可视化 TF-TRT 计算图中,你可以了解更多。
算法是否在使用 Tensor Cores?
你可以通过 nvprof 来检查你的算法是否在使用 Tensor Cores。上图就有一个例子,用 nvprof 来衡量性能。推理用的 Python 脚本为:nvprof python run_inference.py。当我们使用 FP16 的 Tensor Cores 时,字符串 ‘h884’ 会出现在核的名字中。在 Turing Tensor Cores 上,核的名字中就会出现 ‘s1688’ 以及 ‘h688’,分别对应 FP32 和 FP16。
如果算法没有使用 Tensor Cores,你可以通过调试来查看原因。要想检查网络中是否有使用 Tensor Cores,有以下几步要做:
- 在命令行上使用 nvidia-smi 来确认当前的硬件架构是 Volta 或 Turing GPUs。
- 诸如全连接,MatMul, Conv 等运算操作符都可以使用 Tensor Cores。你要确定这些操作的所有维度都是 8 的倍数,这样才会激发 Tensor Core 的使用。对于矩阵乘:M, N, K 的大小必须是 8 的倍数。而全连接层所有的维度都应是 8 的倍数。如果可能,将输入/输出字典填充为 8 的倍数。
注意在某些情况下,TensorRT 有可能选择不是基于 Tensor Cores 的替代算法,如果它们在选取的数据和操作上执行的速度更快。你可以通过 TensorRT Forum 来报告 bugs,和 Tensorflow-TensorRT 社区交流学习。
性能和 Benchmarking 脚本
TensorRT 可以最优化前向推理的性能,对推理进行加速,并降低各任务下的网络的延迟,如图像分类,目标检测,和分割等。比如 ResNet-50,在 GPU 上 Tensorflow 环境中使用 TensorRT,性能能取得至少 8 倍的提升。由于支持 INT8 量化,我们可以同时获得高准确率和高吞吐量。我们可以在深度学习产品性能 中找到 NVIDIA GPU 平台上最新的性能结果。
下表展示了我们所验证的每个模型的准确率。该验证是在整个 ImageNet 验证集上做的前向推理,我们提供了 top-1 准确率。在 Tensorflow-TensorRT 文档中的验证模型部分 可以找到基准模型和准确率数字。
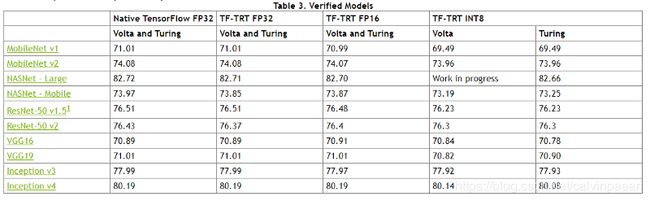
你可以通过我们的脚本 tensorflow/tensorrt_github repo 来下载并测试这些模型,它们用的都是 TF slim 和 TF official公开的模型(ResNet, MobileNet, Inception, VGG, NASNet, L/M, SSD Mobilenet V1)。
下一步
Tensorflow 2.0 在 2019 年 4 月份的 Tensorflow 开发者大会上发布。TensorRT 已从 contrib 位置移到核心编译器库中。APIs 上有些许的改动,但是它仍然支持老的 API。下方的代码片段就是在 Tensorflow 2.0 中使用 TensorRT 优化 Tensorflow 计算图:
from tensorflow.python.compiler.tensorrt import trt_convert as trt
params = trt.DEFAULT_TRT_CONVERSION_PARAMS.replace(
precision_mode = 'FP16')
converter = trt.TrtGraphConverterV2(
input_saved_model_dir = input_saved_model_dir,
conversion_params = params)
converter.convert()
converter.save(output_saved_model_dir)
很快就会发布的 Tensorflow 1.14 可能使用 TrtGraphConverter 函数,其余的代码仍然一样。
总结
我们希望当你使用 NVIDIA GPUs 时, Tensorflow-TensorRT 的融合能确保性能的最优化,而同时保留 Tensorflow 的易用性和灵活性。TensorRT 将支持越来越多的网络,开发者们也将从中受益,而无需改动任何现有代码。
这篇文章主要基于 2019 年在旧金山举办的一场 GPU 技术会议上的演讲而来。如果你想了解全部内容,可以点击用 TensorFlow 来进行 TensorRT 推理。
在 NVIDIA GPU Cloud TensorFlow 中也有二者融合的内容。我们相信,当你使用 GPU 进行推理时,将 TensorRT 和 TensorFlow 融合起来使用,你会受益匪浅。TensorRT 页面 中包含更多的 TensorRT 信息,以及技术文档等。