卡内基梅隆大学提出基于学习的动作捕捉模型,用自监督学习实现人类3D动作追踪
原文来源:Cornell University Library
作者:Hsiao-Yu Fish Tung、Hsiao-Wei Tung、Ersin Yumer、 Katerina Fragkiadaki
「雷克世界」编译:我是卡布达、哆啦A亮
目前,从单摄像头中进行动作捕捉(motioncapture)的最好方法是优化驱动的:通过优化3D人体模型的参数从而使二次投影与视频中的测量结果相匹配(例如,人像分割、光流、关键点检测等)。优化模型容易受到局部最小值(local minima)的影响。这成为了限制动作捕捉的瓶颈,致使每次捕捉动作时必须用干净的绿布作为背景,并且要手动初始化或切换成多摄像头作为输入源。在本项研究中,我们提出了一个用于单摄像头输入的基于学习的动作捕捉模型。我们的模型没有直接优化网格和骨骼参数,而是通过优化神经网络权重来预测给定单目RGB视频的3D形状和骨骼构造。我们的的模型是使用来自合成数据的强监督与来自一个端到端框架中(a)骨骼关键点(b)密集型网格运动(c)人物背景分割可微渲染中的自监督进行联合训练的通过检验,我们证实,我们的模型结合了监督学习和测试时间优化二者的优点:监督学习在适时情况下初始化参数,在测试中确保良好的姿态和表面初始化,不需要手动操作。通过可微渲染的反向传播进行的自监督,使得(无监督的)模型适应测试数据,并且相较预训练固定模型而言,可提供更好的拟合性。我们在此表示,此次提出的模型将随着经验的不断积累,以及总结过去的低误差解决方案而不断改进。
从“自然环境下”的单目装置中详细了解人体及其运动将为自动化健身房、舞蹈教师、康复指导、患者监护以及更安全的人机交互的应用开辟道路。这也会影响到电影行业,因为目前,人物动作捕捉(MOCAP)和重定向,仍需要艺术家花费繁重的劳动力,或者使用昂贵的多摄像机设置和绿屏才能达到理想的精度。
当前,大多数动作捕捉系统都是优化驱动,其并不能从经验中获益。单目动作捕捉系统优化3D人体模型的参数以在视频中与测量结果相匹配(如人像分割、光流等)。背景杂乱和优化困难显著影响追踪性能,这导致过去在工作中总使用绿色的背景幕布,并且进行细致的初始化工作。此外,通过这些费力的方法所捕捉到的动作数据,并不能随着时间的推移而改进。这意味着每次处理视频时,都需要从头重复进行优化和手动操作。
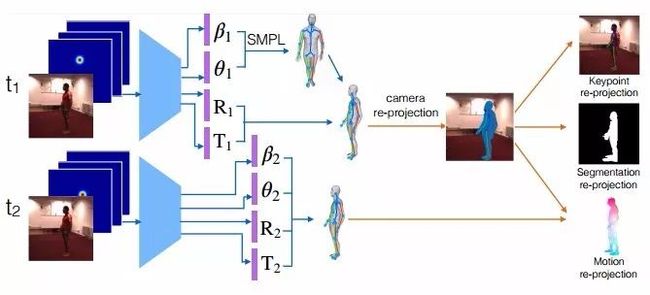
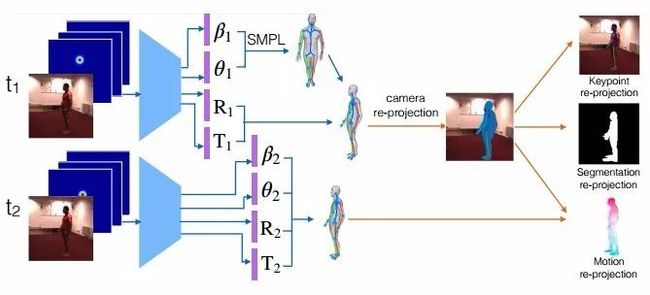
图1 动作捕捉的自监督学习
给定一个视频序列和一组2D肢体关节热图,我们的网络可预测SMPL3D人体网格模型的肢体参数。神经网络权重使用合成数据进行预训练,并使用可微关键点、分割和二次投影误差分别针对检测到的2D关键点、2D分割和2D光流的自监督缺失驱动(self-supervised losses driven)进行微调。通过在测试时运用自监督损失(self-supervised losses)微调其参数,本文提出的模型要比基于模型的纯监督或纯优化具有更高的3D重建精度。其中,基于模型的纯监督或纯优化模型既不能适应也不能从训练数据中受益。
我们提出了一个在单目视频中进行动作捕捉的神经网络模型,学习将一个图像序列映射到一个相应的3D网格序列中。深度学习模型的成功在于从大规模注释数据集中进行监督。然而,详细的3D网格标注是非常繁琐而耗时的,因此在实际生活中,大规模的标注3D人体姿态是不现实的。在真实视频中,我们的工作通过将手动渲染模型的大规模合成数据中的强监督、与3D关键点的3D转2D可微渲染、动作和分割以及真实独目视频中2D相应检测量的匹配中所包含的监督相结合,从而避免了真实视频中缺乏3D网格注释这一问题。我们的自监督利用了2D身体关节检测、2D图底分割和2D光流技术的最新研发成果,分别使用真实或合成数据集(如MPII、COCO和flying chairs)的强大监督进行学习。事实上,注释2D身体关节比注释3D关节或3D网格更容易,而光流被证明可以很容易地从合成数据泛化到真实数据。我们展示了最先进的2D关节、光流和2D人像分割模型是如何用于推理出自认环境下视频中密集的3D人体结构的,而这些工作是难以通过手动操作来完成。与之前基于优化的动作捕捉研究相比,我们现在对光流和分割损耗使用的可微变形(differentiable warping)和可微相机投影技术,使得模型可以通过标准的反向传播进行端对端的训练。
我们使用SMPL作为我们的密集人体3D网格模型。它由一定数量的固定拓扑结构顶点和三角形拓扑结构组成,其中,全局姿势由身体各部分之间的角度θ控制,局部姿势由网格表面参数β控制。对于给定姿势和表面参数,密集网格可以以一种分析法(可微分)形式生成,然后将其全局旋转并转换到期望的位置。我们模型的任务是对渲染过程进行逆向工程,并且预测SMPL模型(θ和β)的参数以及每个输入帧中的焦距、3D旋转和3D翻译,在检测到的人身周围提供图像分割。
给定两个连续帧中的3D网络预测,我们可以对网格顶点的3D动作向量进行差分投影,并将它们与已评估的2D可见光流向量进行有针对性的匹配(图1)。可微动作渲染和匹配需要对顶点可见性进行评估,对于这一点,我们使用光线投射(ray casting),以及用来执行代码加速的我们神经模型实现。类似地,在每一帧中,3D关键点都会被投影,并且他们与相应被检测到的2D关键点之间的距离将会被惩罚。最后,重要的是,可微分割匹配使用倒角距离(Chamferdistances)针对人类前景2D分割的投影顶点的欠拟合和过度拟合进行惩罚。请注意,由于3D网格是无纹理的,因此我们的预测中,二次投影的误差只存在于形态上而非设计的纹理上。
我们提供了在SURREAL和H3.6M数据集上进行的3D密集型人体形态追踪的定量和定性分析结果。我们将其与相应的优化版本进行比较,在这些版本中,网格参数通过最小化我们的自监督损失而优化,并且在测试时不使用自监督,进而达到屏蔽监督模型的效果。优化基线很容易陷入局部极小值,而且它对初始化非常敏感。相比之下,我们的基于学习的MOCAP模型通过预训练(合成数据)可在测试时提供良好的姿态初始化。此外,自监督适应模型比预训练的非适应模型的3D重建误差低。最后,我们的ablation研究突出了三种自监督损失的互补性。
相关研究
3D动作捕捉
使用多台摄像机进行3D动作捕捉(四个或四个以上)是一个已被详细研究的问题,其中现有的方法取得了令人印象深刻的结果。然而,即使对于仅有骨架的捕捉/追踪,单个单目照相机的动作捕捉仍是一个尚待解决的问题。由于单目动作捕捉中的模糊和遮挡可能是严重的,大多数方法依赖于先前的姿势和动作模型。早期的研究考虑线性动作模型。诸如高斯过程动力学模型、以及双高斯过程这样的非线性先验,都已经被提出,并且被证明优于其线性对应结构。最近,Bogo等人提出了一种静态图像姿势和3D密集形状预测模型,其工作分为两个阶段:首先,从图像中预测一个三维人体骨架,然后使用优化过程将参数3D形状拟合到预测骨架,在此过程中骨架保持不变。相反,我们的研究通过测试时间适应,将3D骨架和3D网格估计结合到一个端到端的可微框架中。
3D人体姿态评估
早期的3D姿态评估研究考虑了优化方法和硬编码的拟人约束(anthropomorphic constraints)(例如肢体对称),以消除2D-to-3D提升期间的模糊性,。许多最近研究使用深度神经网络和大型监督训练集,对于给定给定RGB图像,学习直接复归为3D人体姿势。一些研究已经探索使用2D身体姿态作为中间表征,或者作为多任务设置中的辅助任务,其中丰富的被标注的2D姿势训练实例有助于特征学习,并补充有限的3D人体姿势监督,这需要一个Vicon系统,因此被限制只能在实验室仪器化的环境中进行。Rogez和Schmid通过将合成的3D人体模型与逼真的背景相结合,获得了大规模的RGB到3D的合成注释,也在这项研究中使用的数据集。
深度几何学习
我们的可微渲染器遵循最近将深度学习和几何推理相结合的研究。可微变形和可后置摄像头投影已经被用于学习3D摄像机动作,以及学习一个以端到端的自监督的方式进行的3D摄像机和3D物体联合动作,从而使光度损失最小化。Garg等人学习单目深度预测器,由光度误差监督,给定一个立体图像且已知基线作为输入。《gvnn:几何计算机视觉的神经网络库》中贡献了一个深度学习库,有许多几何操作,包括一个可后置的摄像头投影层,类似于Yan等人和吴等人所使用的摄像头。
结论
我们已经提出了一个基于学习的用于密集人体3D动作追踪的模型,用合成数据进行监督,并并通过动网格、关键点和分割的可微渲染进行自监督,并与2D等价量相匹配。我们发现,我们的模型通过使用未标记的视频数据得到了改进,这对于动作捕捉非常有价值,其中,密集3D对照数据难以进行标记。未来研究的一个明确方向是对网格参数的迭代加性反馈,以获得更高的3D重建精度,然后同样以自监督的方式,在参数SMPL模型的顶部学习残差自由形态变形(residual free formdeformation)。 我们的模型在人类3D姿势之外的扩展将使神经智能体以人类的经验学习3D,而其仅由视频动作进行监督。
未来智能实验室致力于研究互联网与人工智能未来发展趋势,观察评估人工智能发展水平,由互联网进化论作者,计算机博士刘锋与中国科学院虚拟经济与数据科学研究中心石勇、刘颖教授创建。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎支持和加入我们。扫描以下二维码或点击本文左下角“阅读原文”
