AI+医疗:基于模型的医疗应用大规模分析 | 腾讯AI Lab学术论坛演讲

来源:腾讯AI实验室
摘要:3月15日,腾讯AI Lab第二届学术论坛在深圳举行,聚焦人工智能在医疗、游戏、多媒体内容、人机交互等四大领域的跨界研究与应用。
3月15日,腾讯AI Lab第二届学术论坛在深圳举行,聚焦人工智能在医疗、游戏、多媒体内容、人机交互等四大领域的跨界研究与应用。全球30位顶级AI专家出席,对多项前沿研究成果进行了深入探讨与交流。腾讯AI Lab还宣布了2018三大核心战略,以及同顶级研究与出版机构自然科研的战略合作。
腾讯AI Lab希望将论坛打造为一个具有国际影响力的顶级学术平台,推动前沿、原创、开放的研究与应用探讨与交流,让企业、行业和学界「共享AI+未来」。
Dimitris Metaxas
美国罗格斯大学计算机科学系杰出教授
计算生物医学影像与建模中心主任

在 16 日的「AI+医疗」论坛上,美国罗格斯大学计算机科学系杰出教授、计算生物医学影像与建模中心(CBIM)主任 Dimitris Metaxas 做了主题为《基于模型的医疗应用大规模分析》的演讲。
Dimitris Metaxas 教授一直致力于形式化方法的开发,以促进医学图像分析、计算机视觉、计算机图形学以及对多模态语言的理解。在计算机生物医学应用领域,他利用MRI、SPAMM和CT扫描数据开发了新的人体内脏器官(如肺)的材料建模和形状识别方法,这是用于心脏运动分析的开拓性框架,也是将人体解剖和生理模型、组织病理学、细胞追踪、细胞类型分析与小鼠行为分析相联系的开拓性架构。
在人工智能和计算机视觉领域,他在可变形模型、三维人体运动分析、行为、场景理解、机器学习、监督、目标识别、稀疏性以及野外生物识别等方面开发了新的方法。在计算机图形学领域,他为流体动画引入了Navier-Stokes方法,1998年的动画电影《蚁哥正传》(Antz)中的水景基于该法制作而成。
Dimitris Metaxas教授发表了500多篇论文,获得过多项最佳论文奖,拥有7项专利。他是富布赖特奖学金、NSF研究启动奖和职业生涯奖,以及ONR青年研究计划奖的获得者。他是美国医学和生物工程院院士、IEEE会士和MICCAI会士,曾担任IEEE CVPR 2014和ICCV 2011大会主席,ICCV 2007程序主席, FIMH 2011、MICCAI 2008及SCA 2007高级程序主席。
演讲内容
医疗数据分析对于新的医学发现、诊断改进和成本降低来说日益重要。本演讲将介绍一种已持续开发25年的通用可扩展的计算框架,它将计算学习、稀疏方法、混合范数、词典和稀疏性的原理与可变形建模方法结合在一起,应用于医学图像分析和计算机视觉领域中复杂的大规模问题中。
演讲将介绍该系统的多种医学应用,包括心脏病的分割、识别和表征的特征发现、心脏 MRI 图像重建、心脏血流分析、大规模组织病理学图像分析和检索、体脂估计,以及用于酒精研究的啮齿动物行为分析和细胞分析等。
以下为演讲全文(为便于阅读进行过适当编辑整理):

大家好。刚才Pep讲了非常多的内容,小编非常赞同。接下来小编会为大家列举一些例子,小编也会说明我们确实需要谨慎小心地运用这些工具。
机器学习的重点是数据,但它们没法超越它们的数据。人工智能在医疗领域的应用才刚刚开始。小编会给出一些案例说明我们当前的工作和难题。

首先小编先简单介绍一下我们的计算生物医学影像与建模中心(CBIM)。CBIM 成立于 2002 年,那时候计算机的运行非常慢,数据非常少,训练神经网络是非常困难的。现在 CBIM 有 133 位教职成员,65 位博士生。

计算生物医学影像与建模是一项多学科的研究任务,不仅涉及计算技术,还涉及到生物学、医学、神经科学、语言学等等。我们需要医生和生物学家来帮我们查看和验证数据,如果我们不做这件事,我们就永远无法成功。我们与罗格斯大学的很多部门都有合作,而且因为罗格斯大学与纽约等地的距离很近,我们和周边的一些医院也有合作关系。
我们希望解决的问题的领域包括使用计算机视觉技术处理生物医学数据、成像、识别以及人类行为和语言的多模态方面。
我们希望为医学影像信息学开发稳健的和可扩展的方法,以用于临床和临床前的应用。
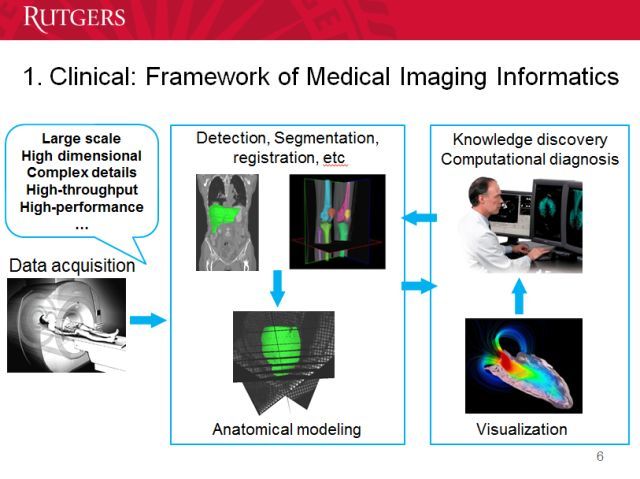
先说临床的。人们已经在临床方向开发了很多框架,涵盖很多流程,从数据获取到检测和分割到诊断等等。这些技术的目的并不是取代医生,而是帮助医生更快更好地完成日常工作。当然这个过程可能会减少对医生的需求,虽然医生不喜欢这一点,但试点测试是必不可少的。
可以看到,首先是数据获取。我们可以通过扫描仪了解病人病灶的情况,这些图像需要进行分割。我们希望能在扫描的时候就分割,而不必之后再做。这方面我们有些自动化的选择和机会。小编会展示神经网络在这方面的优良表现——不管是实时处理还是之后处理。有了分割后的图像后,你需要建模,识别图像中的正常和异常。机器学习只是这个过程的一部分,你还需要向医生解释为什么这个地方是异常的。医生需要知道模型是根据什么特征得出结论的,如果不对,我们还要对神经网络进行修改。
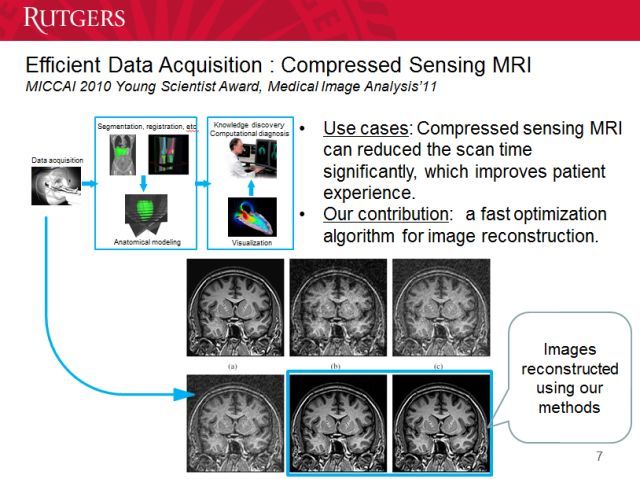
在数据获取方面,压缩传感核磁共振(Compressed Sensing MRI)是一种高效的数据采集方法,能有效降低扫描时间,极大提升病人的体验。我们可以在里面做分割、注册和重建等。
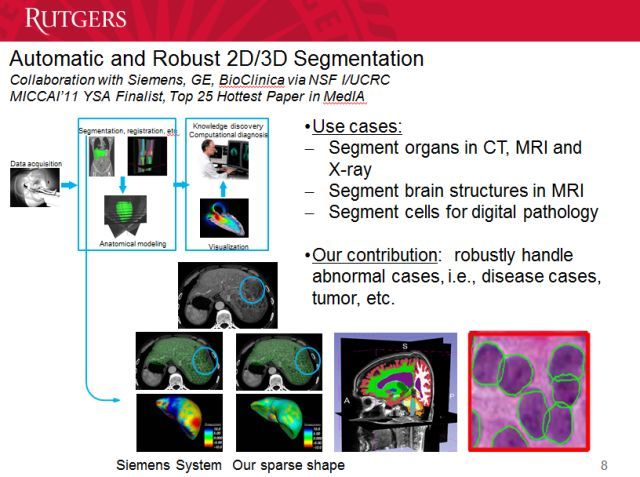
除了分割扫描数据,还有病理学图像分割的研究。但问题是我们如何处理异常,毕竟每个人的异常都不一样。也许神经网络在一些具体病例上表现很好,但却处理不了其他病例。这也是其中的难点。
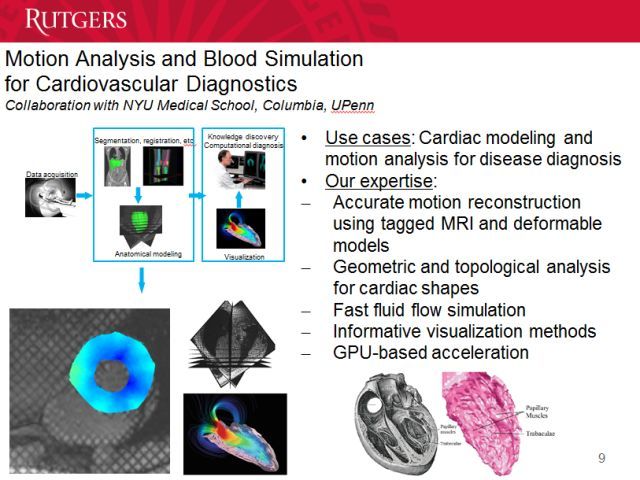
1994年以来我一直在关注心血管诊断领域,我们能用 MRI 重建血流的运动。当然,我们还可以用 CT 重建心脏内部的情况,这比 MRI 更加清晰。
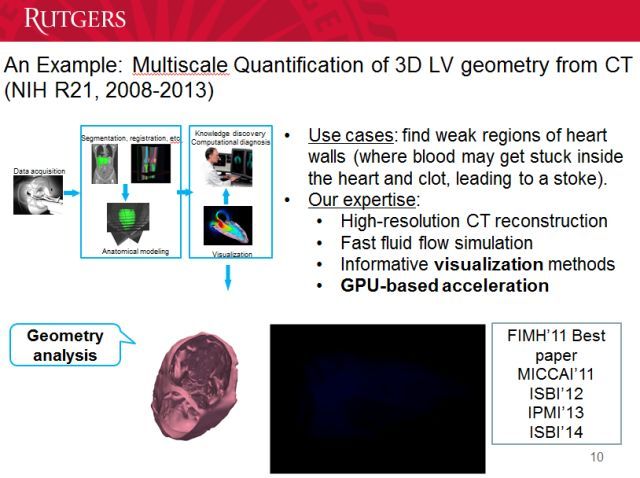
这里可以看到重建出的心脏运动情况。我们能通过这种方式查看心脏里血液留存的位置,预防心脏病发作。
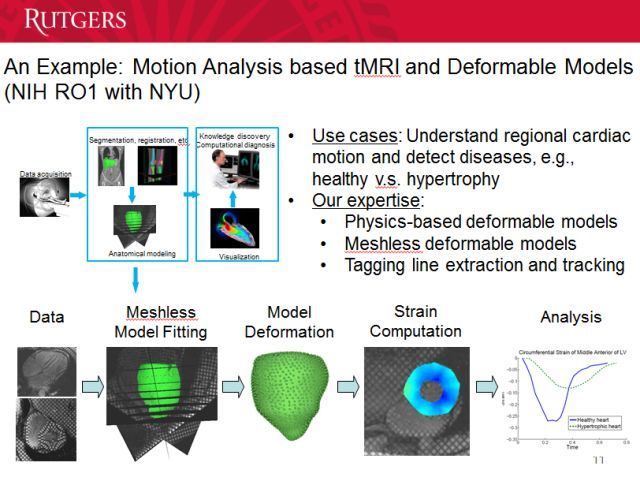
接下来,我们要进行无网格的模型拟合。现在的医生看的是一张张切片,对于 3D 结构他们只能猜测,不能看到。我们可以通过一张张切片重建出 3D 结构,标出其中承受的压力。通过观察心脏中的循环,我们能知道正常和异常的位置。这是非常全面的方法。过去医生通常只看一张片,而心脏是立体的,而且在运动,一张切片的信息很不全面。我们的方法能让医生更好地了解这些信息。
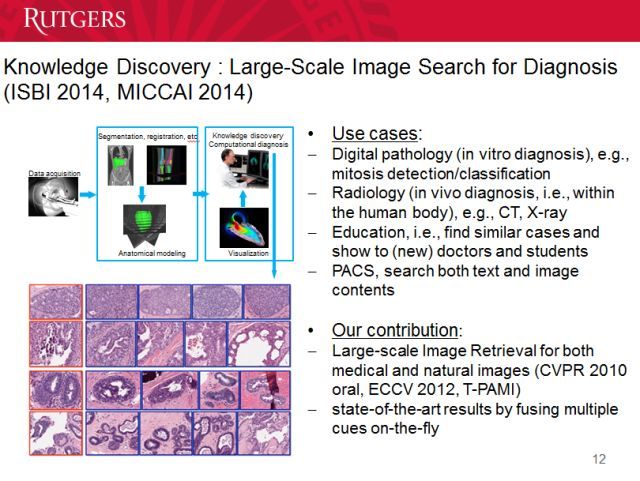
另一项研究是在知识发现上。我们如何将这些图像用来诊断疾病呢?比如分析这些组织病理学图像,来诊断癌症。这方面也有不同的维度。另外,我们也可以将这些信息用来培训新的医生。当然这样的工作并不容易,但对这些方面都会有影响。
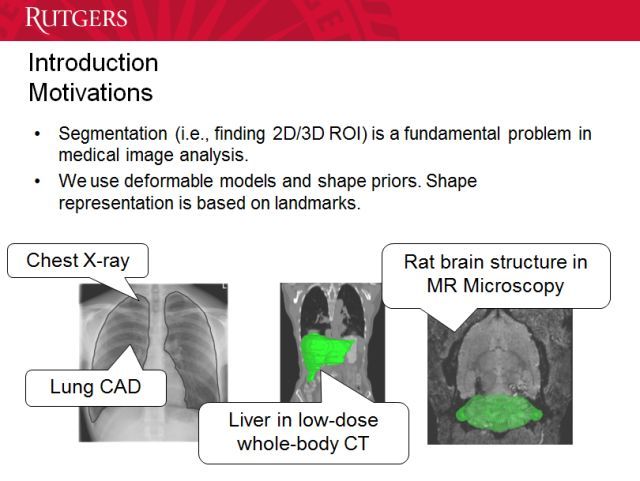
接下来我们谈一个具体的应用。比如说肝脏的 CT。首先我要谈谈为什么这方面的图像分割并不容易。图像中一直都会存在伪影,因为医生往往没有时间去做非常仔细的成像。你不希望将这些伪影分割出来,不然可能会影响医生的诊断。检测肺病的时候,我们需要知道肺在那里。
我们知道左肺和右肺的大小是不一样的,因为一边的肺旁边有心脏,所以会小一点。医生当然知道这一点,但计算机不知道。我们需要填补这其中的差距。此外,大脑等结构拥有很多细节信息,也需要关注。
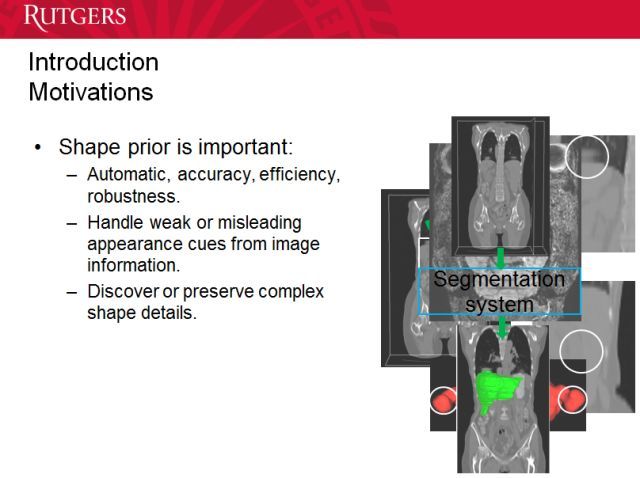
我们可以使用形状先验(shape prior)。我们的自动分割系统需要做到准确、有效和鲁棒。我们不能让医生等待太长时间,还要能处理图像中的伪影等错误信息,以及发现复杂的组织结构(比如大脑)中的细节。
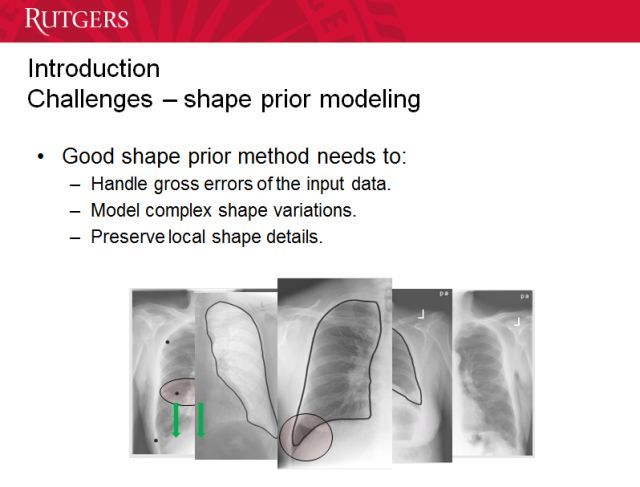
很多时候,由于工作环境的影响,输入的数据可能并不准确,我们需要处理这些问题。另外我们也要保留局部细节,这些细节可能就代表了疾病或创伤的存在,对治疗而言非常重要。

当然,我们有大量数据来做机器学习。这些数据是稀疏的。我们的方法基于两个观察:输入形状可以近似由训练形状的稀疏线性组合表示;给定的形状信息可能包含严重错误,但这种错误通常是稀疏的。我们的做法是首先最小化模型和数据之间的差异,这是我们要执行的变换。然后是稀疏线性组合。

我们也要考虑非高斯误差,这对提升结果很重要。
为什么我们的方法是有效的?在鲁棒性方面,使用 L0 范数约束明确建模“e”,因此可以检测到显然的(稀疏)误差。在通用性方面,不对参数分布模型做任何假设,因此可以建模复杂的形状信息。在无损性方面,使用了所有的训练形状,因此能够覆盖所有的细节信息,甚至包括训练数据中统计不显著的细节。
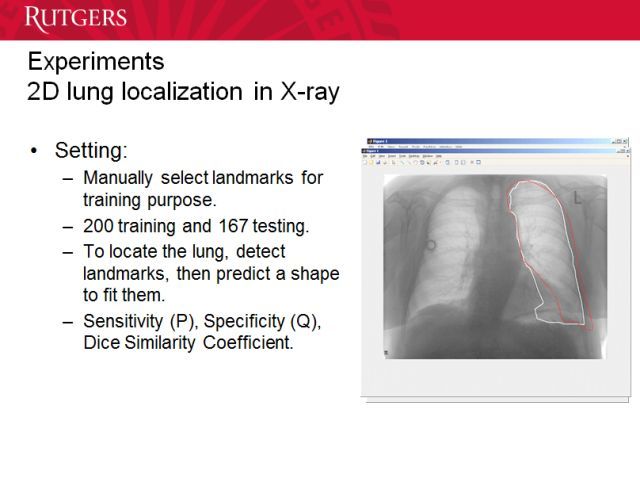
这是我们的实验设置。
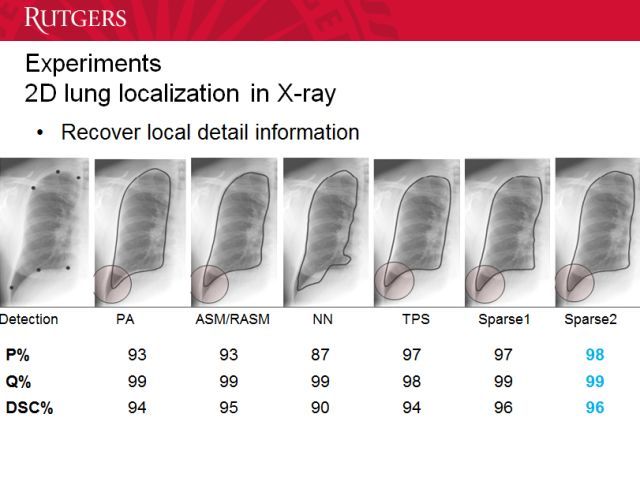
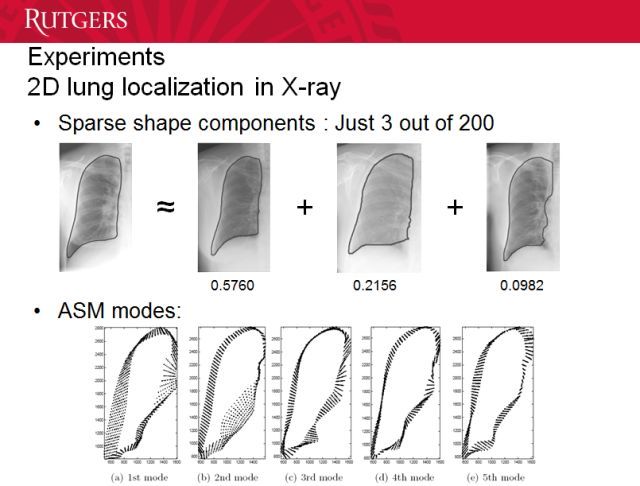
准确度能达到 90% 以上。
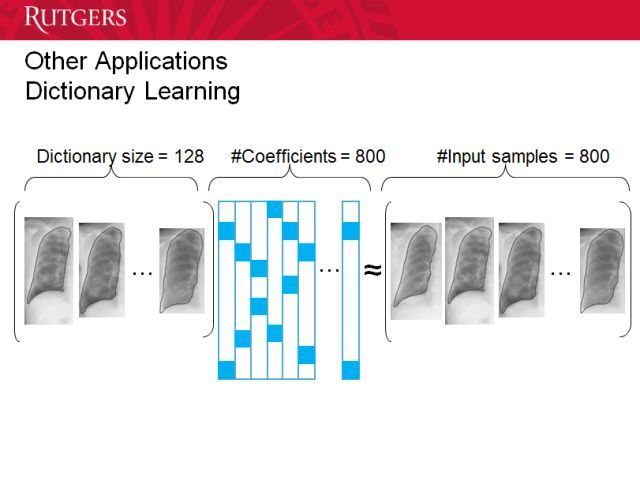
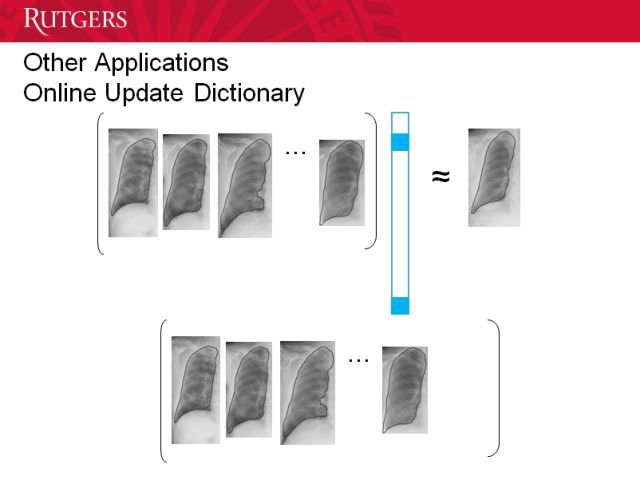
当然你也能进行在线学习,你可以选择哪些数据是重要的。所以小编可以从少量数据开始,然后增加更多数据来提升质量。医生在看过更多图像后会表现得更好,这种方法也是类似。能让模型持续提升的在线学习是很重要的。
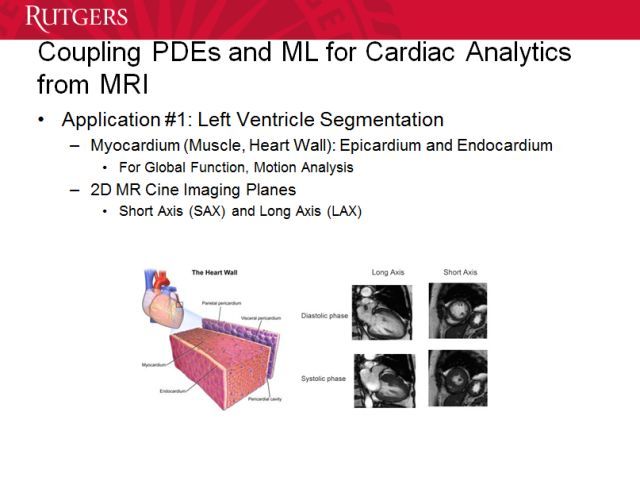
再来看看心脏图像的分割。这方面的进展很慢,但也有一些突破,比如我们刚完成的,能展示出很多复杂细节。
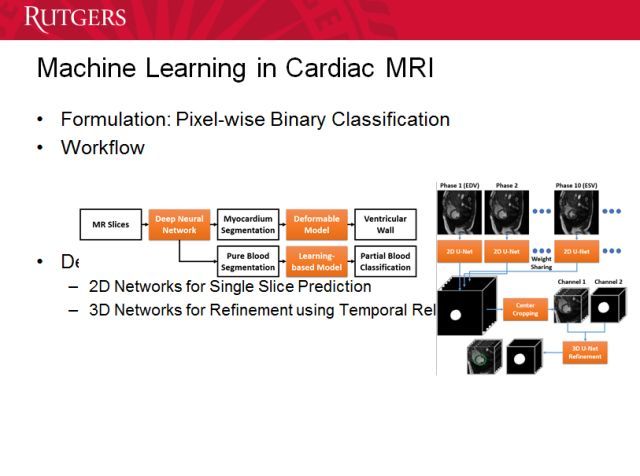
我们能用机器学习在 MRI 上做些什么?这是我们的工作流程。医生需要的不只是一个答案,他们需要知道得出结论的原因,是哪些特征让模型认为存在问题。
我们的方法可以非常准确地说明哪些区域与特定疾病的诊断有关。与心脏相关的疾病有 400 种左右,这些疾病都有一些模式,因此非常适合用机器学习来处理——如果有大量数据的话。所以我们和很多医院和学校合作来获得理解这一问题的数据。实际上,50% 罹患心脏血管疾病的风险都是可以早期预测的,通过测量,我们能发现一些连医生也不知道的事情。所以我们也实际上推进到了下一步。
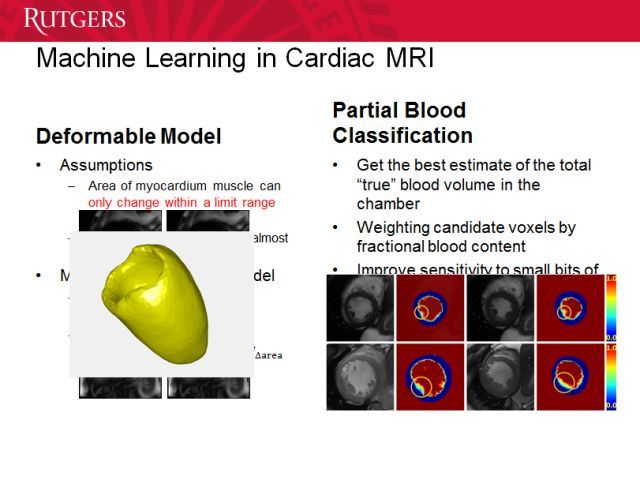
得到了切片后我们可以建模,得到 3D 模型,实现更好的可视化。这样医生就不容易错过或忽略对一些疾病的诊断。
这里的红色和黄色展示了血液和肌肉的比例。我们在研究这个比例与疾病的关联。
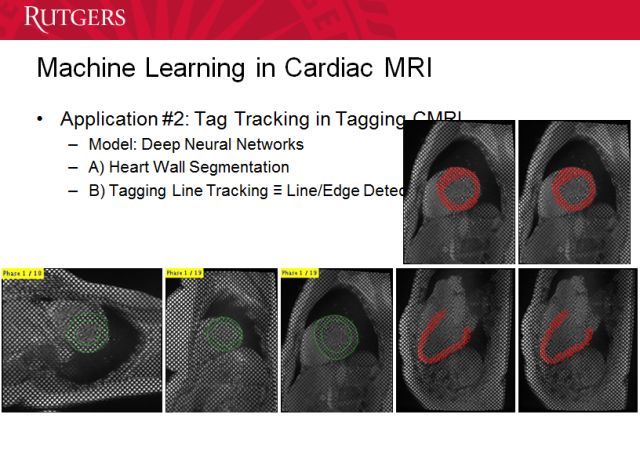
还有标志跟踪(tag tracking),这是一种了解血液如何影响对心室的压力的常用手段。

这里是一些关于流速场的讨论。患病瓣膜会有更小的孔洞,会导致更高的流速,产生的高压力可能导致患病。
基于哈希的图像检索(Towards Large-Scale Histopathological Image Analysis: Hashing-Based Image Retrieval)是我们的又一项研究。
疾病的严重程度千差万别,就像在这个病例里面,这是一种恶性肿瘤。
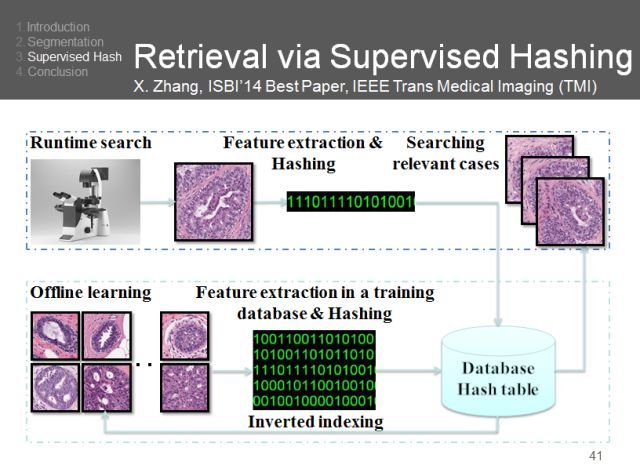
哈希可以检测相似性信息,让模型表现更好。
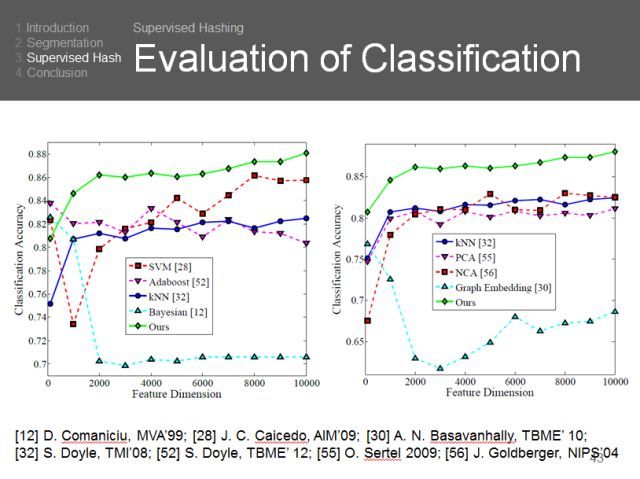
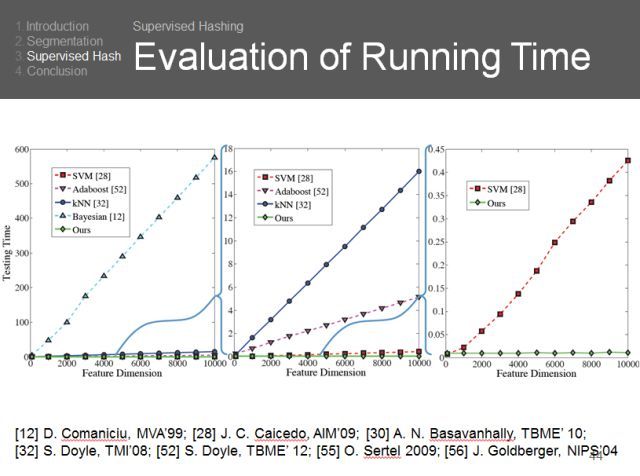
可以看到,我们不仅做得更好,而且更加稳定,不管特征维度有多大。算法的高效性是非常重要的。
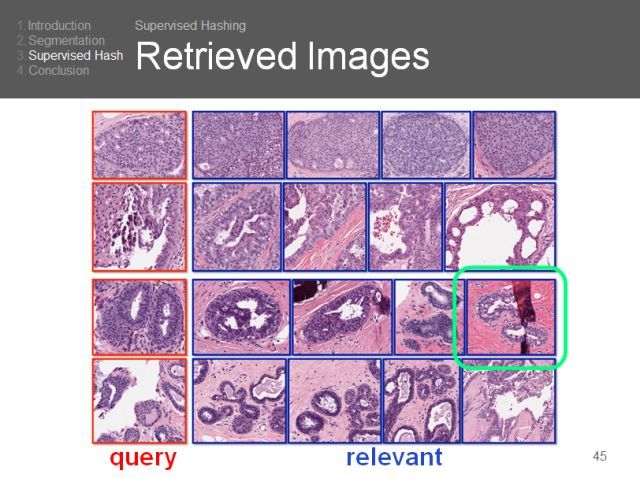
这是检索结果的展示。
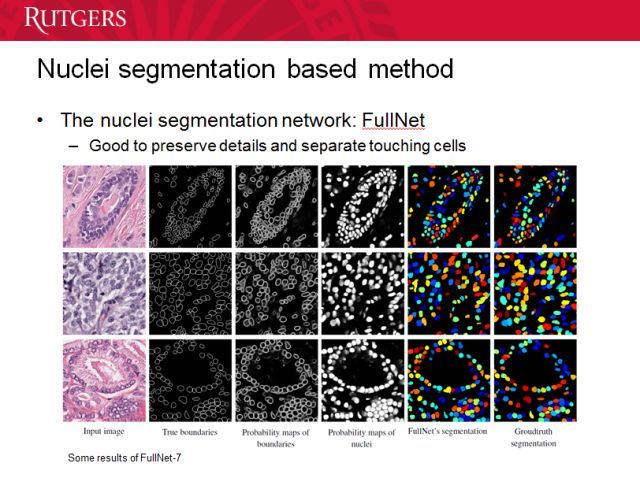
在临床前研究方面,我们也有一些进展。这是我们的一种细胞核的分割方法。这是我们和很多不同医院共同开展的一项研究。那么我们怎么找到细胞核呢?因为细胞核很重要,与 DNA 相关。

我们可以根据形状和大小等特征对细胞核进行分类,看是正常还是异常的。另外密度信息也很重要,肿瘤细胞和正常细胞有不同的密度。

我们可以把它应用到一些临床前应用上,比如研究大量小鼠的行为。因为小鼠在药物和疾病研究上很重要,小鼠的行为能为我们提供一些结果。我们可以划分小鼠不同的部分,监控和统计多只小鼠的活动。

最后,我们的未来研究方向有哪些?首先是高效的信息融合。我们希望不只是检测单模态数据,而能同时使用多个尺度上的多模态数据。另一个方向是从粗略到精细的学习(Coarse-to-fine Learning),不同规模的学习很重要。我们希望将领域专家的知识整合到机器学习中,以提升推理能力和可解释性;我们还希望在使用过程中不断修正神经网络,我称之为「learn how to learn」。
当然,我们也要研究使用可解释的参数进行学习和推理的基本方法。非线性优化方法也是一个研究方向,神经网络的参数太多了,我们如何在减少参数数量的同时又实现更好的表现?有时候需要基于耦合 PDE 和机器学习的方法。
小编的演讲到此为止。我们现在还没有到达顶峰,但是已经处在一个非常令人激动和兴奋的时间节点,我们对机器学习为医疗领域带来变革很有信心。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”
