分组数据后取每组的前N条的几种方法
面试java软件开发,今天第二天了,连着面试四家,都不太理想,今下午又栽到sql上了,好久没写sql了。呜呼,以记之。
员工表:员工,部门,工资
要求:查询出各部门工资最高的十个人。
以前经常写这样的sql,时间久不写,完全不会了,忍着回忆到现在,只记得
(1).有group by 的select 必须是聚合函数或是goup by的字段
(2)应该先order by还是先group by,先order by 的话,想不起来了,脑子太混乱了,还有oracle的有个叫什么的专有名词,是用来分组查询的。
既然想不起来,那就开始百度吧。先建起来数据库。点背,竟争很大啊,还是自己水平有重大问题。
首先创建库和表。
DROP DATABASE IF EXISTS company;
CREATE DATABASE company;
USE company;
CREATE TABLE `employee`(
`empno` INT(32) NOT NULL AUTO_INCREMENT,
`department` VARCHAR(64),
`salary` DOUBLE(10,2),
PRIMARY KEY(`empno`)
);INSERT INTO EMPLOYEE(`department`,`salary`) VALUES
('B',16000.00),('B',19000.00),('A',10000.00),('A',11000.00),('A',12000.00),('B',13000.00),('B',14000.00),('D',24000.00),('D',25000.00),('B',18000.00),
('C',7000.00),('A',13000.00),('A',14000.00),('A',16000.00),('C',5000.00),('A',16000.00),('A',17000.00),('A',18000.00),('A',19000.00),('B',17000.00),
('B',10000.00),('B',11000.00),('B',12000.00),('B',15000.00),('D',26000.00),('D',26000.00),('D',27000.00),('B',15500.00),('B',16000.00),
('D',20000.00),('D',21000.00),('D',25500.00),('C',2000.00),('C',3000.00),('C',4000.00),('D',28000.00),('D',29000.00),('D',30000.00),('C',6000.00),
('C',1000.00),('C',1100.00),('D',22000.00),('D',23000.00),('C',5500.00),('C',6000.00),('C',8000.00),('C',9000.00),('A',15000.00),('A',15500.00);
下面先试验分组:我嘞个去,不会写,先回忆回忆这个逻缉是什么,第一步要干什么,第二步要干什么。
无非有三种可能的方法:
1. 先用group by 分组,分组条件不能只是 department,不然每个分组只会出现一条记录,今天就写错了,只用了department作为分组条件,自己已经知道错了,面试官还让我讲,讲一半就把我打发走了。悲剧。到现在才回忆起分组条件应加上empno,这样的话所有记录都会出来;然后对分组结果用order by salary desc排序,用limit 0,10.取每组的前十条数据。
2.先将整个表的数据按order by salary desc排序;然后用group by department,empno 分组。最后用limit 0,10取每组前10条数据。
3.有特定用法,让分组和排序同时进行,不过按道理,事情是一步一步做的,两个步骤同时进行计算机知道怎么做吗?不过隐约记得oracle有特定的用法来分组和排序的。以后再说。在MYSQL中先排除这种情况。
分析以上三种做法,先排除第三种;个人倾向于第二种。理由:感觉第一种打完组之后,再按salary排序,会把分组的结果又打乱了,得到的只是按salary排序的结果。故倾向于第二种做法。
然后优先假设第二种是正确的,开始写sql调试。
SELECT
et.`department` dep,
et.`empno`,
et.`salary`
FROM
(SELECT
e.`department`,
e.`empno`,
e.`salary`
FROM
employee e
ORDER BY e.`salary` DESC) et
GROUP BY et.`department`,
et.`empno` ;结果如下: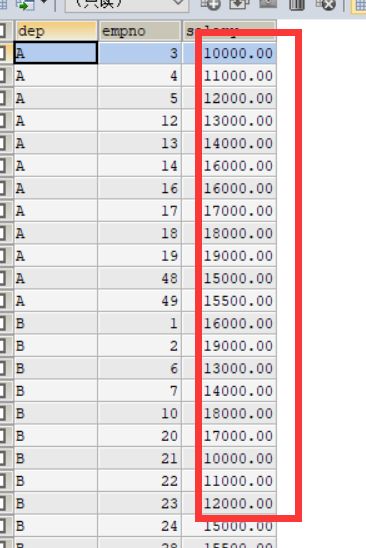
这结果说明现实和理想差距太大了,内层order by salary 排序在最终结果中完全没体现出来,可以说完全没用。怎么办,
先查看一下order by 和group by 同时在下个查询中的执行顺序吧。已经忘了。
插入一句,刚才的查询如果在严格模式下已经报错了,我的之所不报错,是在非严格模式下,现在要改成严格模式,
[mysqld]
character-set-server=utf8
default-storage-engine=INNODB
sql-mode="ONLY_FULL_GROUP_BY,NO_AUTO_VALUE_ON_ZERO,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION,PIPES_AS_CONCAT,ANSI_QUOTES"
max_connections=100
explicit_defaults_for_timestamp=true
黑色字体就是设置严格模式,重启mysql后,运行上面的句子就报错了,要尽量在严格模式下运行sql。
当一个查询语句同时出现了where,group by,having,order by的时候,执行顺序和编写顺序
使用count(列名)当某列出现null值的时候,count(*)仍然会计算,但是count(列名)不会。
二、数据分组(group by ):
select 列a,聚合函数(聚合函数规范) from 表名 where 过滤条件 group by 列a
group by 字句也和where条件语句结合在一起使用。当结合在一起时,where在前,group by 在后。即先对select xx from xx的记录集合用where进行筛选,然后再使用group by 对筛选后的结果进行分组。
三、使用having字句对分组后的结果进行筛选,语法和where差不多:having 条件表达式
需要注意having和where的用法区别:
1.having只能用在group by之后,对分组后的结果进行筛选(即使用having的前提条件是分组)。
2.where肯定在group by 之前,即也在having之前。
3.where后的条件表达式里不允许使用聚合函数,而having可以。
四、当一个查询语句同时出现了where,group by,having,order by的时候,执行顺序和编写顺序是:
1.执行where xx对全表数据做筛选,返回第1个结果集。 2.针对第1个结果集使用group by分组,返回第2个结果集。
3.针对第2个结果集中的每1组数据执行select xx,有几组就执行几次,返回第3个结果集。
4.针对第3个结集执行having xx进行筛选,返回第4个结果集。 5.针对第4个结果集排序。
———————————————————————————————————————————————-
Group By 和 Having, Where ,Order by这些关键字是按照如下顺序进行执行的:Where, Group By, Having, Order by。
啊,实在不会,难道是第三种办法才是正确的,我真是笨极了,算了,百度去,不浪费时间了。
网上这样的例子真是一抓一大把。粗看来,一种是用相关子查询实现,另一种是连接(联表、联结、 多表联合 都是一个意思)查询(用join 和group by 实现)。
又牵连到相关子查询和非相关子查询了,上学的时候这一点都没搞通透,现在又栽在这上面了。
值得说明的是网上有多种说法,其实 相关子查询=关联子查询,说的是同一个东西
何为相关子查询?这里引用《Oracle Database 10g SQL开发指南》中的解释:
- 关联子查询会引用外部查询中的一列或多列。这种子查询之所以被称为关联子查询,是因为子查询的确与外部查询有关。当问题的答案需要依赖于外部查询中包含的每一行中的值时,通常就需要使用关联子查询。
一位网友的理解:相关子查询的意思是子查询的结果集会受到主查询的影响.非相关子查询不受影响.
比如
相关子查询
select * from a where exists (select 1 from b where a.col1=b.col1)
非相关子查询
select * from a where a.col1 in (select b.col1 from b)
另一网友:
不相关子查询是指子查询独立于外层语句(主查询),他不依赖于其外层语句的操作结果,他们执行时可分为两个独立的步骤,即先执行子查询,在执行外层查询。例如:
SELECT 姓名 FROM STUDENT WHERE入学成绩>(select avg(入学成绩) FROM STUDENT )
相关子查询时一种其子查询和外层相互交叉的数据检索方法.从概念上讲包含相关子查询的语句在执行时部能分为一先一后两个步骤.【我对这名话补充一下:相关子查询的执行依赖于外部查询的数据,外部查询执行一行,子查询就执行一次。并且是外部先查询一次,然后再执行一次内部查询!(由于他执行查询的次数多,可见他的效率并不高,可以用存储过程来代替他)】
另一位网友总结:非相关子查询和相关子查询区别
- 非相关子查询是独立于外部查询的子查询,子查询总共执行一次,执行完毕后将值传递给外部查询,并且它是优先于外部查询先执行的,他执行了再执行外部。
- 相关子查询的执行依赖于外部查询的数据,外部查询执行一行,子查询就执行一次。并且是外部先查询一次,然后再执行一次内部查询!(由于他执行查询的次数多,可见他的效率并不高,可以用存储过程来代替他)
另:相关子查询:相关子查询的执行依赖于外部查询。多数情况下是子查询的WHERE子句中引用了外部查询表。执行过程:
(1)从外层查询中取出一个元组,将元组相关的列值传给内层查询。
(2)执行内层查询,得到子查询操作的值。
(3)外查询根据子查询返回的结果或结果集得到满足条件的行
(4)然后外层查询取出下一个元组重复做步骤1-3,直到外层的元组全部处理完毕。
另:从语法要求上,EXISTS子句并不要求一定是相关子查询。但想要用EXISTS实现IN的逻辑,通常都是相关子查询。
Exists所在之处不见得都是相关子查询.这要看你的内部查询是否引用到外部的表.
执行Exists的伪代码:
select * from t1 where exists ( select * from t2 where y = x ) ;
可以理解为:
for x in ( select * from t1 )
loop
if ( exists ( select * from t2 where y = x.x )
then
OUTPUT THE RECORD
end if
end loop(一)下面是使用相关子查询的正确的代码,
SELECT e.`department`,e.`empno`,e.`salary`
FROM employee e
WHERE 10>(SELECT COUNT(1) FROM employee et WHERE et.`department` = e.`department` AND et.`salary` > e.`salary`)
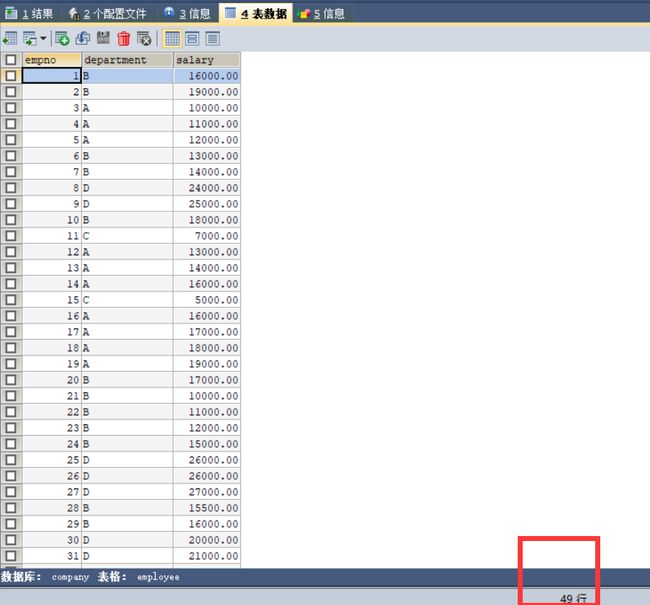
ORDER BY e.`department`,e.`salary` DESC;我们先看一下数据库的原始记录,就是我们刚刚插入的数据。(总共49行,这里从上到下截取部分)
根据现在查询的资料和执行sql的结果,我来猜测一下该sql执行的顺序。
A.e 表查询第一行,取出 empno department salary
1 B 16000.00
这条记录。
B.然后where语句就变为
where 10>(SELECT COUNT(1) FROM employee et WHERE et.`department` = 'B' AND et.`salary` >16000.00)首先执行查询
SELECT COUNT(1) FROM employee et WHERE et.`department` = 'B' AND et.`salary` >16000.00得到结果为3
然后where 语句就变为
where 10>3;而整个语句(先不考虑
ORDER BY e.`department`,e.`salary` DESCSELECT e.`department`,e.`empno`,e.`salary`
FROM employee e
WHERE 10>3;如果sql变成这样,那不是所有记录都会查出来吗,因为10>3是一个永远符合条件的条件。
不知大家有没注意到这条sql还有一个隐含条件,就是 这个sql是在
e 表查询到第一行,取出 empno department salary
1 B 16000.00
这个前提下形成的,也就是说此时,e.department='B',e.empno=1,e.salary=16000.00;所以上面的sql应是这样的:
SELECT e.`department`,e.`empno`,e.`salary`
FROM employee e
WHERE 10>3 and e.`department`='B' and e.`empno`=1 and e.`salary`=16000.00;然后根据这个sql就取出结果1 B 16000.00 这一条记录。
C.然后e表取出第二条记录
empno department salary
2 B 19000.00
以后的以后就剩重复执行A步骤和B步骤,符合条件的结果就取出来,不符合的就抛弃。
我们来观察一下最后的结果,完整执行
SELECT e.`department`,e.`empno`,e.`salary`
FROM employee e
WHERE 10>(SELECT COUNT(1) FROM employee et WHERE et.`department` = e.`department` AND et.`salary` > e.`salary`);之后,我们看结果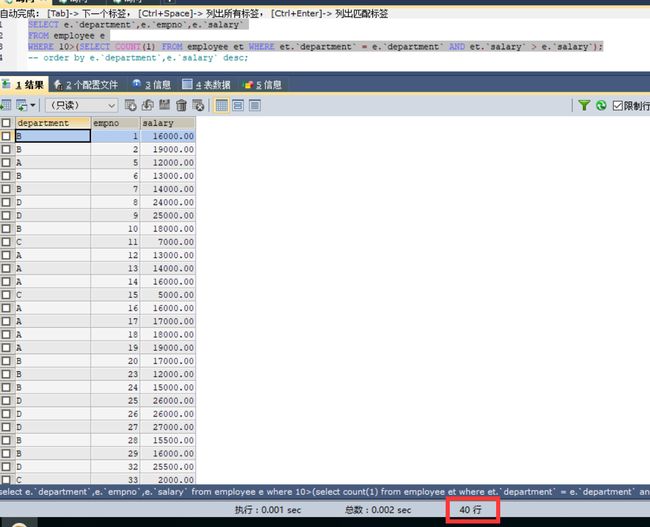
和理论上一致,结果是按原始记录的顺序逐条取舍的。此时并没有排序,我们再把排序第件加上,执行并查看结果
SELECT e.`department`,e.`empno`,e.`salary`
FROM employee e
WHERE 10>(SELECT COUNT(1) FROM employee et WHERE et.`department` = e.`department` AND et.`salary` > e.`salary`)
ORDER BY e.`department`,e.`salary` DESC;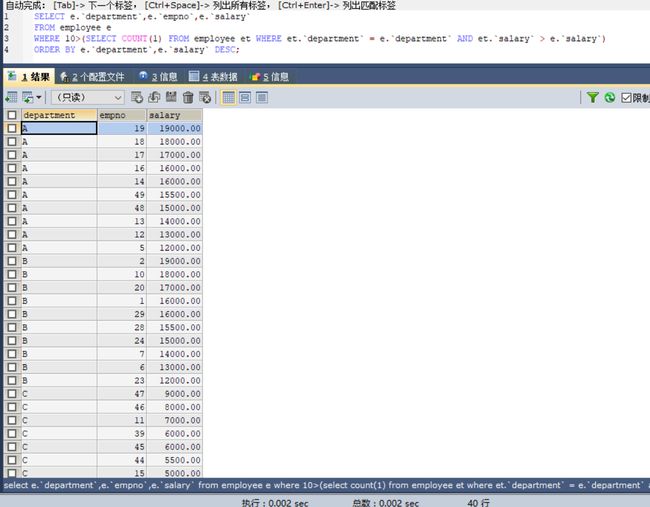
举杯庆祝,得到了最后的正确结果。大二学的数据库一直没有搞透这个相关子查询(距大二已过去七年了,怀念那时的青春时光,现在什么都没有,什么都不随心愿,好孤单,好哀伤,算了算了,人生不就是这样么,有人过的好,有人过的不好,有人春风得意马蹄急,有人江枫渔火对愁眠,待好身边的人,处好身边的事,快快乐乐,少留遗憾地随时光同来同去),现在终于搞明白了,解了一个心结。
(二)下面是用连接查询实现
先自行分析一下要如何实现,用group by怎么搞,貌似也没法搞,多表连接又能怎样?笨啊,百度吧。
看完后又是一个恍然大悟,不多说写sql.额,看着明白了,一写又错了,果然纸上得来终觉浅,绝知此事要躬行。
方法A :用left join
SELECT e.`department`,e.`empno`,e.`salary`
FROM employee e
LEFT JOIN employee et
ON e.`department` = et.`department` AND e.`salary`方法B:用inner join
SELECT e.`department`,e.`empno`,e.`salary`
FROM employee e
INNER JOIN employee et
ON e.`department` = et.`department` AND e.`salary`<=et.`salary`
GROUP BY e.`empno`,e.`department`,e.`salary`
HAVING COUNT(1)<=10
ORDER BY e.`department`,e.`salary` DESC;结果全是正确的,不截图了。left join 和inner join的写法有一点点差别,在这里提一下
left join 里用e.`salary` 在left join里,最大值即使不符合e.`salary` 而inner join 里只有用e.`salary`<=et.`salary`才不会漏掉最大值。 关于ORACLE的,因为本机上没装,所以试验不了,先放下,记一点查到的有关用法算了 项目中用到Oracle分组查询取每组排序后的前N条记录,group by 只能返回每个组的单条统计。所以用OVER(PARTITION BY)函数
生活如此多艰,对事物没有看法,事物对你也没有看法。 3月30号下午续: 今天下午面试官给我说了一个sql题: 有一员工表,按员工工资从高到低给员工排序,第一,第二......工资相同的排名相同 也不让在纸上做,想了好久没做出来。现在复盘,就利用上面的employee表做吧,看着他妈妈的还是挺简单的 这个题稍微一变,就成了令一个题: 按员工工资从高到低,统计出每个部门员工的排行 第一,第二......(部门内工资相同的排名相同)
SELECT b,c,row_number() OVER(PARTITION BY b ORDER BY c desc) e FROM test_abc) t where e <= 3
SELECT empno,salary,(SELECT COUNT(1)+1 FROM employee et WHERE et.salary > e.`salary`) ranking
FROM employee e
ORDER BY ranking;SELECT department,empno,salary,(SELECT COUNT(1)+1 FROM employee et WHERE et.salary > e.`salary` AND et.department = e.`department`) ranking
FROM employee e
ORDER BY department,ranking;