SparkRDD函数详解(一)--RDD转换函数
1.什么是RDD
RDD(Resilient Distributed Dataset),弹性分布式数据集,Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。在 Spark 中,对数据的所有操作不外乎创建 RDD、转化已有RDD 以及调用 RDD 操作进行求值。每个 RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含 Python、Java、Scala 中任意类型的对象, 甚至可以包含用户自定义的对象。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD支持两种操作:转化操作和行动操作。RDD 的转化操作是返回一个新的 RDD的操作,比如 map()和 filter(),而行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作。
2.创建RDD的方式
RDD的创建有两种常用方式:
1)sc.parallelize()
2)sc.makeRDD()
3.常用转换函数
1.map(func):返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成
var source = sc.parallelize(1 to 10)
val mapadd = source.map(_ * 2)

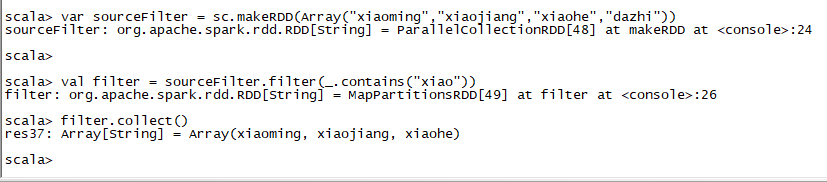
2. filter(func):返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成
var sourceFilter = sc.makeRDD(Array("xiaoming","xiaojiang","xiaohe","dazhi"))
val filter = sourceFilter.filter(_.contains("xiao"))
filter.collect()
 3. flatMap(func):类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素)
3. flatMap(func):类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素)
val sourceFlat = sc.makeRDD(1 to 5)
sourceFlat.collect()
val flatMap = sourceFlat.flatMap(1 to _)
flatMap.collect()
 4.mapPartitions(func):类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U]。假设有N个元素,有M个分区,那么map的函数的将被调用N次,而mapPartitions被调用M次,一个函数一次处理所有分区
4.mapPartitions(func):类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U]。假设有N个元素,有M个分区,那么map的函数的将被调用N次,而mapPartitions被调用M次,一个函数一次处理所有分区
val rdd = sc.makeRDD(List(("kpop","female"),("zorro","male"),("mobin","male"),("lucy","female")))
:paste
// Entering paste mode (ctrl-D to finish)
def partitionsFun(iter : Iterator[(String,String)]) : Iterator[String] = {
var woman = List[String]()
while (iter.hasNext){
val next = iter.next()
next match {
case (_,"female") => woman = next._1 :: woman
case _ =>
}
}
woman.iterator
}
val result = rdd.mapPartitions(partitionsFun)
result.collect()
 5.sample(withReplacement, fraction, seed):以指定的随机种子随机抽样出数量为fraction的数据,withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样,seed用于指定随机数生成器种子。例子从RDD中随机且有放回的抽出50%的数据,随机种子值为3(即可能以1 2 3的其中一个起始值)
5.sample(withReplacement, fraction, seed):以指定的随机种子随机抽样出数量为fraction的数据,withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样,seed用于指定随机数生成器种子。例子从RDD中随机且有放回的抽出50%的数据,随机种子值为3(即可能以1 2 3的其中一个起始值)
val rdd = sc.makeRDD(1 to 10)
rdd.collect()
var sample1 = rdd.sample(true,0.4,2)
sample1.collect()
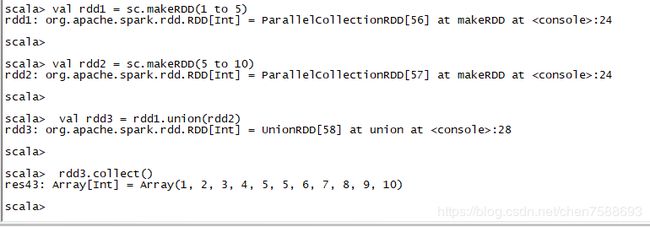
 6.union(otherDataset):对源RDD和参数RDD合并后返回一个新的RDD
6.union(otherDataset):对源RDD和参数RDD合并后返回一个新的RDD
val rdd1 = sc.makeRDD(1 to 5)
val rdd2 = sc.makeRDD(5 to 10)
val rdd3 = rdd1.union(rdd2)
rdd3.collect()
 7.intersection(otherDataset):对源RDD和参数RDD求交集后返回一个新的RDD
7.intersection(otherDataset):对源RDD和参数RDD求交集后返回一个新的RDD
val rdd1 = sc.makeRDD(1 to 7)
val rdd2 = sc.makeRDD(5 to 10)
val rdd3 = rdd1.intersection(rdd2)
rdd3.collect()
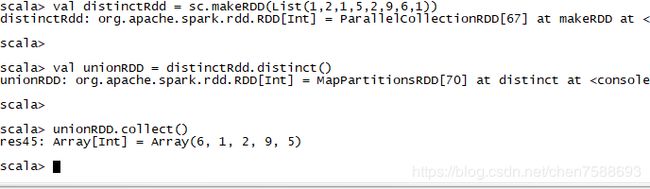
 8.distinct([numTasks])):对源RDD进行去重后返回一个新的RDD. 默认情况下,只有8个并行任务来操作,但是可以传入一个可选的numTasks参数改变它。
8.distinct([numTasks])):对源RDD进行去重后返回一个新的RDD. 默认情况下,只有8个并行任务来操作,但是可以传入一个可选的numTasks参数改变它。
val distinctRdd = sc.makeRDD(List(1,2,1,5,2,9,6,1))
val unionRDD = distinctRdd.distinct()
unionRDD.collect()
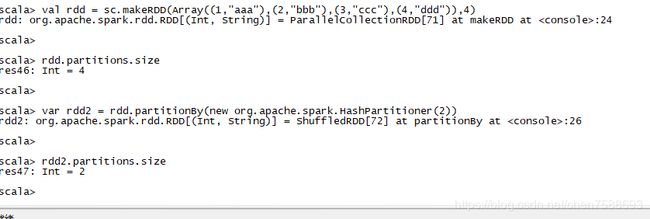
 9.partitionBy:对RDD进行分区操作,如果原有的partionRDD和现有的partionRDD是一致的话就不进行分区,
9.partitionBy:对RDD进行分区操作,如果原有的partionRDD和现有的partionRDD是一致的话就不进行分区,
否则会生成ShuffleRDD.
val rdd = sc.makeRDD(Array((1,"aaa"),(2,"bbb"),(3,"ccc"),(4,"ddd")),4)
rdd.partitions.size
var rdd2 = rdd.partitionBy(new org.apache.spark.HashPartitioner(2))
rdd2.partitions.size
 10.reduceByKey(func, [numTasks]):在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置
10.reduceByKey(func, [numTasks]):在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置
val rdd = sc.makeRDD(List(("female",1),("male",5),("female",5),("male",2)))
val reduce = rdd.reduceByKey((x,y) => x+y)
reduce.collect()
 11.groupByKey:groupByKey也是对每个key进行操作,但只生成一个sequence。
11.groupByKey:groupByKey也是对每个key进行操作,但只生成一个sequence。
val words = Array("one", "two", "two", "three", "three", "three")
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
val group = wordPairsRDD.groupByKey()
group.collect()
 12.sortByKey([ascending], [numTasks]):在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
12.sortByKey([ascending], [numTasks]):在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
val rdd = sc.makeRDD(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
rdd.sortByKey(true).collect()
rdd.sortByKey(false).collect()
 13.cogroup(otherDataset, [numTasks]):在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD
13.cogroup(otherDataset, [numTasks]):在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD
val rdd = sc.makeRDD(Array((1,"a"),(2,"b"),(3,"c")))
val rdd1 = sc.makeRDD(Array((1,4),(2,5),(3,6)))
rdd.cogroup(rdd1).collect()
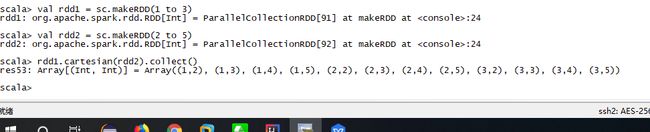
 14.cartesian(otherDataset):笛卡尔积
14.cartesian(otherDataset):笛卡尔积
val rdd1 = sc.makeRDD(1 to 3)
val rdd2 = sc.makeRDD(2 to 5)
rdd1.cartesian(rdd2).collect()
 15:glom:将每一个分区形成一个数组,形成新的RDD类型时RDD[Array[T]]
15:glom:将每一个分区形成一个数组,形成新的RDD类型时RDD[Array[T]]
val rdd = sc.makeRDD(1 to 16,4)
rdd.glom().collect()
 16.mapValues:针对于(K,V)形式的类型只对V进行操作
16.mapValues:针对于(K,V)形式的类型只对V进行操作
val rdd3 = sc.makeRDD(Array((1,"a"),(1,"d"),(2,"b"),(3,"c")))
rdd3.mapValues(_+"|||").collect()
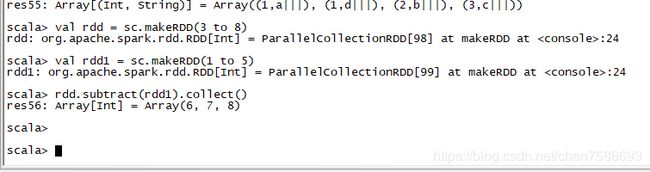
 17.subtract:计算差的一种函数去除两个RDD中相同的元素,不同的RDD将保留下来
17.subtract:计算差的一种函数去除两个RDD中相同的元素,不同的RDD将保留下来
val rdd = sc.makeRDD(3 to 8)
val rdd1 = sc.makeRDD(1 to 5)
rdd.subtract(rdd1).collect()