Spark学习笔记(转)
本文章根据《Spark 快速大数据分析/ Learning Spark: Lightning-fast Data Anakysis》一书整理。这篇文章的主要目标和特点:简要、重点、完成后可用于开发
1、Spark是什么
Spark是一个用来实现快速而通用的集群计算的平台。其一个主要的特点就是能够在内存中进行计算,因此速度更快。原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理,Spark通过在一个统一的框架下支持这些不同的计算,实现有效的整合,减轻了原先对各种平台分别管理的负担。
Spark提供了基于Python,Java,Scala,SQL的简单易用的API,以及内建的丰富的程序库,其还可以与其他大数据工具密切配合使用,如Spark可以运行在Hadoop集群上。
Spark是一个大一统的软件栈,包含多个组件
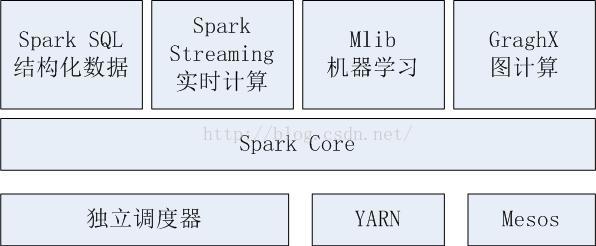
Spark Core :实现Spark的基本功能:任务调度、内存管理、错误恢复、与存储系统交互等。Core 还包含了对弹性分布式数据集RDD(resilient distributed dataset)的API定义。
RDD表示分布在多个计算机节点上可以并行操作的元素集合,是Spark的主要编程抽象。
spark SQL:操作结构化数据的程序包。通过 Spark SQL,可以使用SQL或者HQL来查询数据,Spark SQL支持多种数据源,如Hive表、Parquet、以及JSON等,其还支持将SQL与传统的RDD编程的数据操作方式相结合。
Spark Streaming:对实时数据进行流失计算的组件。流数据的定义:只能以事先规定好的顺序被读取一次的数据的一个序列,特点是以非常高的速率到来的输入数据。
MLib:提供常见的机器学习ML功能的程序库,提供了很多机器学习算法,包括分类,回归、聚类、协同过滤等。
GraphX:用来操作图(数学用语,比如朋友关系图)的程序库,可以进行并行的图计算,提供一些常用的图算法。
Spark设计为可以高效的在一个计算节点到数千个计算节点之间伸缩计算,Spark支持在各种集权管理器cluster manager上运行,包括Hadoop YARN,Apache Mesos,以及Spark自带的简易调度器——独立调度器。
Spark的存储层次:Spark不仅可以将任何Hadoop分布式文件系统上的文件读取为分布式数据集,也可以支持其他支持Hadoop接口的系统,如Hive,HBase,Spark支持任何实现了Hadoop接口的存储系统。
2、Spark开发环境搭建
使用spark,可以通过shell,也可以通过搭建开发环境,因个人开发需要,主要面向java搭建Spark开发环境。暂时略过。
开发Spark程序实际上就是通过调用Spark的API,实现Java程序与Spark环境之间的交互:
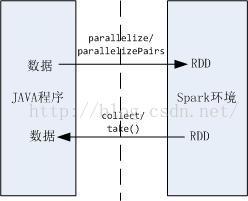
Java驱动程序将需要计算的数据通过parallelize方法,将数据传给Spark环境,转换为RDD;
驱动程序通过调用各种算子Api,实现Spark环境对数据的计算;
最后,Spark环境将计算结果返回给Java驱动程序;
搭建Spark环境后,先创建Spark的环境对象SparkContext,需要传入两个参数:
集群URL:告诉Spark如何连接到集群上,使用”local”可以使spark运行在单机单线程上而无需连接到集群。
应用名
- SparkConf sparkConf = new SparkConf().setMaster(“local”).setAppName(“My App”);
- JavaSparkContext sc = new JavaSparkContext(sparkConf);
3、RDD编程
弹性分布式数据集RDD(Resilient Distributed Dataset)是Spark对数据的核心抽象,在Spark中,对数据的操作不外乎 创建RDD,转化已有的RDD,调用RDD操作进行求值。
Spark中的RDD是一个不可变的分布式对象集合,每个RDD都被分为多个区,这些分区运行在集群中的不同节点上。
创建RDD,可以读取外部数据集,也可以使用驱动器程序的对象集合。
RDD支持两种类型的操作:转化操作transformation和行动操作action。转化操作会由一个RDD生成一个新的RDD。
转化操作和行动操作的区别就在于Spark的计算RDD的方式不同,Spark对RDD是采用惰性计算的方式。只有第一次执行行动操作的时候,才会真正计算。
默认情况下,RDD会在每次对它们进行行动操作的时候重新计算,如果想多个行动操作中重用一个RDD,可使用RDD.persist()让Spark把这个RDD缓存下来。
在实际操作中,经常使用persist()把数据的一部分读取到内存中,并反复查询这部分数据,这样可以避免低效。
- SparkConf sparkConf = new SparkConf().setMaster(“local”).setAppName(“My App”);
- JavaSparkContext sc = new JavaSparkContext(sparkConf);
- //创建RDD,读取外部文件
- String path = ”D://line_event.txt”;
- JavaRDD
input = sc.textFile(path); - //持久化RDD
- input.persist(new StorageLevel());
- System.out.println(input.count());//6357
- //转化操作,filter过滤
- JavaRDD
input_filter = input.filter(new Function - @Override
- public Boolean call(String arg0) throws Exception {
- return arg0.contains(“\”4\”“);
- }
- });
- System.out.println(input_filter.count());//237
- //行动操作
- String first = input_filter.first();
- System.out.println(first);
1. 创建RDD
两种方式:读取外部数据集、在驱动程序中对一个集合进行并行化。创建RDD最简单的方式就是把程序中一个已有的集合传给SparkContext的parallelize()方法,但需要注意,除开发原型和测试时,这种方式用的并不多,因为需要把真个数据集放在一台机器内存中。
- JavaRDD
input_par = sc.parallelize(Arrays.asList( “pandas”,“spark”,“yuchen”)); - System.out.println(input_par.count());//3
2.RDD操作
转化操作
返回新的RDD,转化操作是惰性求值的,只有行动操作用到这些RDD时才会被计算。另外,转化操作后,旧的RDD还可以继续使用。
目前接触到的转化操作有:
map 返回一个新的分布式数据集,将数据源的每一个元素传递给函数 func 映射组成。
filter 返回一个新的数据集,从数据源中选中一些元素通过函数 func 返回 true。
union 取两个RDD的合集。
- JavaRDD
union = input_filter.union(input_par); - System.out.println(union.count());//240
Spark会使用谱系图来记录这些不同的RDD之间的依赖关系。
虽然转化操作是惰性求值的,可以使用一次行动操作来强制执行转化操作。
行动操作
- JavaRDD
union = input_par.union(input_filter); - System.out.println(union.count());//240
- List
list = union.take(4); - System.out.println(list);
向Spark传递函数
Spark中的大部分转化操作和一部分行动操作,都需要依赖用户传递的函数来进行计算。Java中,函数需要是实现了function包中的任意函数接口的对象,根据不同的返回类型,定义了一些不同的接口:- Function
- Function2
- FlatMapFunction
call(T) 接收一个输入值并返回任意个输出,用于类似flatMap()
可以通过匿名内部类,也可以使用具名类的方式
- // 匿名类
- JavaRDD
input_filter = input.filter(new Function - @Override
- public Boolean call(String arg0) throws Exception {
- return arg0.contains(“\”4\”“);
- }
- });
- System.out.println(input_filter.count());//237
- //具名类
- class Contains implements Function
- String filterStr;
- public Contains(String str){
- filterStr = str;
- }
- @Override
- public Boolean call(String arg0) throws Exception {
- return arg0.contains(filterStr);
- }
- }
- JavaRDD
filters = input.filter(new Contains(“\”9\”“)); - System.out.println(filters.count());//637
- RDD
str = lines.filter(s -> s.contains( “error”));
常见的转化操作和行动操作
先讲受任意数据类型的RDD支持的转化操作和行动操作转化操作
针对各个元素的转化操作
- //map
- JavaRDD
nums = sc.parallelize(Arrays.asList(1,3,4)); - JavaRDD
nums_2 = nums.map(new Function - @Override
- public Integer call(Integer x) {
- return x*x;
- }
- });
- System.out.println(nums_2.collect());//[1, 9, 16]
- //注意flatMap与map的区别
- //flatMap 根据空格拆分
- JavaRDD
str = sc.parallelize(Arrays.asList(”hello yuchen”,“hi”,“nice to meet you”)); - JavaRDD
str_split = str.flatMap(new FlatMapFunction - //注意使用FlatMapFunction时,call返回的是Iterator类型
- @Override
- public Iterator
call(String arg0) throws Exception { - return Arrays.asList(arg0.split(“ ”)).iterator();
- }
- });
- System.out.println(str_split.collect());//[hello, yuchen, hi, nice, to, meet, you]
- //map 根据空格拆分
- JavaRDD
- @Override
- public List
call(String arg0) throws Exception { - return Arrays.asList(arg0.split(“\\s+”));
- }
- });
- System.out.println(str_map.collect());//[[hello, yuchen], [hi], [nice, to, meet, you]]
伪集合操作
RDD支持很多集合操作,比如合并,相交等,下边讲四种操作。- JavaRDD
nums = sc.parallelize(Arrays.asList( 1,3,3,4)); - //distinct
- JavaRDD
nums_dis = nums.distinct(); - System.out.println(nums_dis.collect());//[4, 1, 3]
- //sample
- JavaRDD
nums_sam = nums.sample(false, 0.5); - System.out.println(nums_sam.collect());//[3, 4]不确定,随机取值
- JavaRDD
nums2 = sc.parallelize(Arrays.asList(1,4, 6, 8)); - //union
- JavaRDD
nums_union = nums.union(nums2); - System.out.println(nums_union.collect());//[1, 3, 3, 4, 1, 4, 6, 8]
- //intersection
- JavaRDD
num_inter = nums.intersection(nums2); - System.out.println(num_inter.collect());//[4, 1]
- //subtract
- JavaRDD
num_sub = nums.subtract(nums2); - System.out.println(num_sub.collect());//[3, 3]
- //cartesian笛卡尔积
- JavaPairRDD
- System.out.println(num_carte.collect());
- //[(1,1), (1,4), (1,6), (1,8), (3,1), (3,4), (3,6), (3,8), (3,1), (3,4), (3,6), (3,8), (4,1), (4,4), (4,6), (4,8)]
行动操作
- JavaRDD
nums_1 = jsc.parallelize(Arrays.asList( 1,3,5,6)); - //reduce
- Integer sum =nums_1.reduce(new Function2
- @Override
- public Integer call(Integer arg0, Integer arg1) throws Exception {
- return arg0+arg1;
- }
- });
- /**
- * 1: 1+3;
- * 2: 4+5;
- * 3: 9+6;
- * 结果15
- */
- System.out.println(sum);
- JavaRDD
nums_2 = jsc.parallelize(Arrays.asList(1,5,7,9)); - //fold 与reduce操作类似,可以提供一个计算中使用到的初始值,初始值可以不使用,等同于reduce
- Integer sum2 = nums_2.fold(10, new Function2
- @Override
- public Integer call(Integer arg0, Integer arg1) throws Exception {
- return arg0+arg1;
- }
- });
- /**
- * fold的计算过程:
- * 1: 10+1;
- * 2: 11+5;
- * 3: 16+7;
- * 4: 23+9;
- * 5: 10+32
- * 结果42
- */
- System.out.println(sum2);
- JavaRDD
nums_2 = jsc.parallelize(Arrays.asList( 1,5,7,9)); - Function2
- @Override
- public Double call(Double arg0, Integer arg1) throws Exception {
- return arg0+arg1;
- }
- };
- Function2
- @Override
- public Double call(Double arg0, Double arg1) throws Exception {
- return arg0+arg1;
- }
- };
- double res = nums_2.aggregate(10.0, add, combin);
- System.out.println(res);
- JavaRDD
nums_2 = jsc.parallelize(Arrays.asList( 1,5,7,9)); - class AvgCount implements Serializable{
- public int total;
- public int num;
- public AvgCount(int total,int num){
- this.total = total;
- this.num = num;
- }
- public double avg(){
- return total/(double)num;
- }
- }
- AvgCount initial = new AvgCount(0, 0);
- Function2
- new Function2
- @Override
- public AvgCount call(AvgCount arg0, Integer arg1)
- throws Exception {
- arg0.total+=arg1;
- arg0.num++;
- return arg0;
- }
- };
- Function2
- new Function2
- @Override
- public AvgCount call(AvgCount arg0, AvgCount arg1)
- throws Exception {
- arg0.total+=arg1.total;
- arg0.num+=arg1.num;
- return arg0;
- }
- };
- AvgCount result = nums_2.aggregate(initial, addAndCount, combine);
- /**
- * 1. initial 在addAndCount中与 RDD的元素进行计算,返回初始值类型的结果res1
- * 所以Function2
- * 2. initial 与在addAndCount中返回的结果res1进行计算,返回初始值类型的结果res2
- * 所以Function2
- * 可以看出aggregate的返回结果可以与RDD元素的类型不同
- */
- System.out.println(result.avg());
- JavaRDD
nums_1 = jsc.parallelize(Arrays.asList( 2,1,3,5,6,4,10,1,-2)); - //take
- List
list_take = nums_1.take(3); - System.out.println(list_take);//[2, 1, 3]集群下,原则是尝试只访问尽量少的分区
- //top 默认
- List
list_top_def = nums_1.top(3); - System.out.println(list_top_def);//[10, 6, 5]默认是按照降序
- //top 指定比较函数
- class SortASC implements Comparator
, Serializable{ //java.util.Comparator - @Override
- public int compare(Integer o1, Integer o2) {
- return o1
- }
- }
- List
list_top_asc = nums_1.top(3, new SortASC()); - System.out.println(list_top_asc);//[-2, 1, 1]
- //foreach
- nums_1.foreach(new VoidFunction
() { - @Override
- public void call(Integer arg0) throws Exception {
- System.out.println(arg0);
- }
- });
- System.out.println(nums_1.count());
- System.out.println(nums_1.countByValue());//返回Map 值:计数
- //{5=1, 10=1, 1=2, 6=1, 2=1, 3=1, 4=1, -2=1}
- jsc.stop();