基于单目摄像头的物体检测 - Baidu Apollo 陈光 - 2D 图像上的 3D 目标检测
基于单目摄像头的物体检测 - Baidu Apollo 陈光 - 2D 图像上的 3D 目标检测
摄像机是无人车系统中最重要的传感器之一,其廉价、帧频高、信息丰富、观测距离远,但易受环境影响、缺乏深度信息。
Apollo 2.5 和 3.0 中广泛使用的单目摄像头物体检测模块。

1. 物体检测模型中的算法选择

autonomous [ɔː'tɒnəməs]:adj. 自治的,自主的,自发的
radar ['reɪdɑː]:n. 雷达,无线电探测器
ultrasonic [ʌltrə'sɒnɪk]:adj. 超声的,超音速的 n. 超声波
obstacle ['ɒbstək(ə)l]:n. 障碍,干扰,妨碍,障碍物
物体检测 (object detection) 是无人车感知的核心问题,要求我们对不同的传感器设计不同的算法,准确检测出障碍物。例如在 Apollo 中,为 3D 点云设计的 CNN-SEG 深度学习算法,为 2D 图像设计的 YOLO-3D 深度学习算法。
https://github.com/ApolloAuto/apollo/tree/r3.0.0/modules/perception/model/cnn_segmentation
https://github.com/ApolloAuto/apollo/tree/r3.0.0/modules/perception/obstacle/lidar/segmentation/cnnseg
https://github.com/ApolloAuto/apollo/tree/r3.0.0/modules/perception/model/yolo_camera_detector
物体检测要求实时准确的完成单帧的障碍物检测,并借助传感器内外参标定转换矩阵,将检测结果映射到统一的车身坐标系或世界坐标系中。准确率、召回率、算法耗时是物体检测的重要指标。Apollo 中基于单目摄像头的物体检测模块。
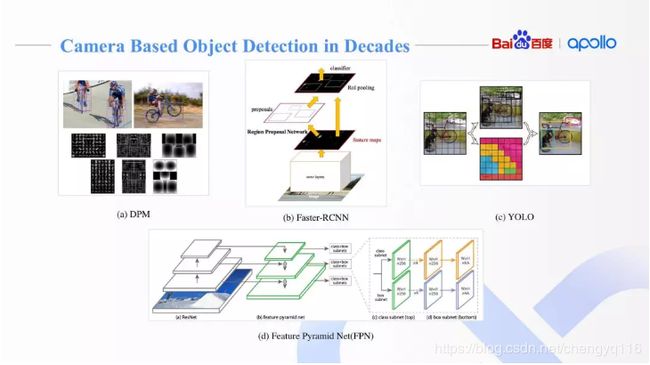
Object Detection with Discriminatively Trained Part-Based Models
Deformable Part Model,DPM:可形变部件模型
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
YOLO9000: Better, Faster, Stronger
You Only Look Once,YOLO
SSD: Single Shot MultiBox Detector
Focal Loss for Dense Object Detection
Feature Pyramid Network,FPN
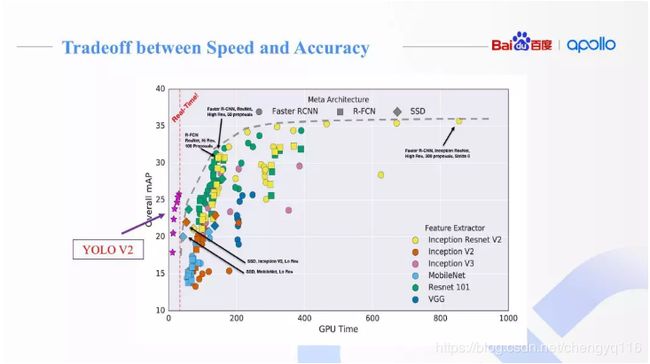
Speed/accuracy trade-offs for modern convolutional object detectors 将物体检测神经网络拆分为主框架 meta-architecture 和特征描述模块 feature extractor。选择不同的组合方式,去验证模型的实效性和准确率。
在 MS COCO 数据集上,YOLO V2 取得了实时速度下良好的检测准确率。百度最终选择了 YOLO 作为主框架,以改进的 Darknet 作为特征描述模块 feature extractor。
2. 单目摄像头下的物体检测神经网络

sedan [sɪ'dæn]:n. 轿车,轿子
Apollo 2.5 和 3.0 中,基于 YOLO V2 设计了单目摄像头下的物体检测神经网络 Multi-Task YOLO 3D。它最终输出单目摄像头 3D 障碍物检测和 2D 图像分割所需的全部信息。
(1) 实现多任务输出
- 物体检测包括 2D 框 (以像素为单位),3D 真实物体尺寸 (以米为单位),障碍物类别和障碍物相对偏转角 (Alpha Angle 和 KITTI 数据集定义一致)。
- 物体分割车道线信息,并提供定位模块。
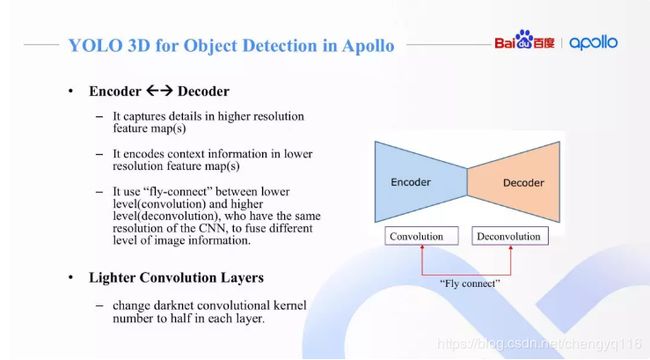
(2) 特征描述模块引入了类似 FPN 的 Encoder 和 Decoder 设计。在原始 Darknet 基础上,加入了更深的卷积层 (feature map size 更小) 同时添加反卷积层,捕捉更丰富图像上下文信息 (context information)。高分辨率多通道特征图,捕捉图像细节 (例如 edge、corner),深层低分辨率多通道特征图,编码更多图像上下文信息。与 FPN 类似的飞线连接,更好的融合了图像的细节和整体信息。
(3) 降低每层卷积核数目,加快运算速度。我们发现卷积核数目减半,实验中准确率基本不变。

物体检测最终输出包括 2D 框 (以像素为单位),3D 真实物体尺寸 (以米为单位),障碍物类别和障碍物相对偏转角 (Alpha Angle 和 KITTI 数据集定义一致) 等信息。
和 YOLO V2 算法一样,我们在标注样本集中通过聚类,产生一定数目的锚模板,去描述不同类别、不同朝向、不同大小的障碍物。例如对小轿车和大货车,我们会定义不同的锚模板,去描述它们的实际物理尺寸。

intrinsic [ɪn'trɪnsɪk]:adj. 本质的,固有的
为什么要去训练、预测这些参数呢?
相机成像的原理,针孔相机 (pinhole camera) 通过投影变换,可以将三维 camera 坐标转换为二维的图像坐标。这个变换矩阵解释相机的内在属性,称为相机内参 (camera intrinsic)。
pinhole ['pɪnhəʊl]:n. 针孔,小孔

对任意一个相机坐标系下的障碍物的 3D 框,我们可以用它的中心点 T = { X , Y , Z } T = \{X, Y, Z\} T={X,Y,Z},长宽高 D = { L , W , H } D = \{L, W, H\} D={L,W,H},以及各个坐标轴方向上的旋转角 R = { ϕ , φ , θ } R = \{ϕ, φ, θ\} R={ϕ,φ,θ} 来描述。这种 9 维的参数描述和 3D 框 8 点的描述是等价的,而且不需要冗余的 8 x 3 个坐标参数来表示。
对一个相机坐标系下 3D 障碍物,通过相机内参,可以投射到 2D 图像上,得到 2D 框 [ c x , c y , h , w ] [c_x, c_y, h, w] [cx,cy,h,w]。从图中可以看到,一个障碍物在相机下总共有 9 维 3D 描述和 4 维 2D 描述,他们之间通过相机内参矩阵联系起来。
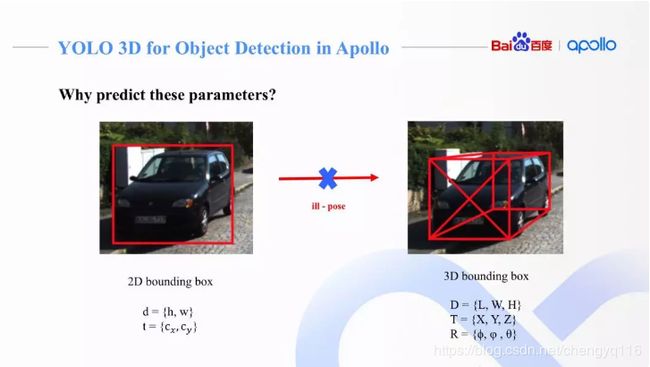
只通过 2D 框 [ c x , c y , h , w ] [c_x, c_y, h, w] [cx,cy,h,w] 是没有办法还原成完整的 3D 障碍物信息的。
3. 训练预测参数的设计
通过神经网络直接预测 3D 障碍物的 9 维参数,比较困难,尤其是预测障碍物 3D 中心点坐标。根据几何学来设计到底要训练预测哪些参数。

(1) 利用地面平行假设,我们可以降低所需要预测的 3D 参数。
- 我们假设 3D 障碍物只沿着垂直地面的坐标轴有旋转,而另外两个方向并未出现旋转,即只有 yaw 偏移角,剩下的 pitch 和 roll 均为 0。
- 障碍物中心高度和相机高度相当,所以可以简化认为障碍物的 Z = 0 Z = 0 Z=0。
翻滚 - roll - 翻滚角
俯仰 - pitch - 俯仰角
绕 Z 轴左右旋转 (偏摆 - yaw - 偏航角)
从右图可以看到,现在只有 6 维 3D 信息需要预测,但没有办法避免预测中心点坐标 X 和 Y 分量。
yaw [jɔː]:n. (火箭、飞机、宇宙飞船等) 偏航 vt. 使...偏航 vi. 偏航
pitch [pɪtʃ]:vi. 倾斜,投掷,搭帐篷,坠落 vt. 投,掷,定位于,用沥青涂,扎营,向前倾跌 n. 沥青,音高,程度,树脂,倾斜,投掷,球场
roll [rəʊl]:vt. 卷,滚动,转动,辗 vi. 卷,滚动,转动,起伏,摇晃 n. 卷,卷形物,名单,摇晃
leverage ['liːv(ə)rɪdʒ; 'lev(ə)rɪdʒ]:n. 手段,影响力,杠杆作用,杠杆效率 v. 利用,举债经营

principle ['prɪnsɪp(ə)l]:n. 原理,原则,主义,道义,本质,本义,根源,源泉
(2) 利用成熟的 2D 障碍物检测算法,准确预测出图像上 2D 障碍物框 (以像素为单位)。
(3) 对 3D 障碍物里的 6 维描述,可以选择训练神经网络来预测方差较小的参数,例如障碍物的真实物理大小,因为一般同一类别的障碍物的物理大小不会出现量级上的偏差 (车辆的高度一般在 2-5 米之间,很少会出现大幅变化)。而 yaw 转角也比较容易预测,跟障碍物在图像中的位置关系不大,适合通用物体检测框架来训练和预测。实验中亦证明此项。
现在唯一没有训练和预测的参数就是障碍物中心点相对相机坐标系的偏移量 X 分量和 Y 分量。需要注意的是障碍物离相机的物理距离 d i s t a n c e = s q r t ( X 2 + Y 2 ) distance = sqrt(X^2 + Y^2) distance=sqrt(X2+Y2)。所以得到 X 和 Y,就可以得到障碍物离相机的真实距离,这是单目测距的最终要求之一。

mature [mə'tʃʊə]:adj. 成熟的,充分考虑的,到期的,成年人的 vi. 成熟,到期 vt. 使...成熟,使...长成
实现单目摄像头的 3D 障碍物检测需要完成以下两部分。
(1) 训练网络,并预测出大部分参数。
- 图像上 2D 障碍物框预测,因为有对应的大量成熟算法文献。
- 障碍物物理尺寸,因为同类别内方差较小。
- 不被障碍物在图像上位置所影响,并且通过图像特征 (appearance feature) 可以很好解释的障碍物 yaw 偏转角。
(2) 通过图像几何学,来计算出障碍物中心点相对相机坐标系的偏移量 X 分量和 Y 分量。
4. 模型训练与距离测算

模型训练上,我们需要注意一些细节。
(1) 确保标注质量,尤其是 3D 障碍物框。可以借助激光雷达等来辅助标注障碍物尺寸,偏转角等。
(2) 定义合适的损失函数,可以参考 3D Bounding Box Estimation Using Deep Learning and Geometry。
(3) 做好数据增强,避免过拟合。

metrology [mɪ'trɒlədʒɪ]:n. 度量衡,度量衡学
当我们训练好相应的神经网络,输出我们需要的各个参数之后,我们需要考虑的是如何计算出障碍物离摄像头的距离。通过内参和几何学关系,可以链接起图像中 3D 障碍物大小 (单位为像素) 和真实 3D 坐标系下障碍物大小 (单位为米)。
我们采用单视图度量衡 (Single View Metrology) 来解释这个几何关系:任一物体,已知它的长宽高、朝向和距离,则它在图像上的具体形状大小唯一确定;反之亦然。

房屋的支撑柱,大小高度完全相同,但是处于图像的不同位置,所占用的像素、长宽都有差别。

基于单视图度量衡,我们可以建立一个哈希查询表 (lookup table),去根据物体图像尺寸、物理尺寸和朝向角来查询物体的距离。
对于每种障碍物,我们根据它的平均 (或单位) 尺寸,去建立查询表,覆盖 360 度 yaw 角的变化,来映射不同的距离。(例如 2D 框的 25 像素高,yaw 角为 30 度,则它的距离为 100 米等等)。图中示例了一个小轿车在不同距离下、不同偏转角 yaw angle 情况下,在图像上的显示。

adorable [ə'dɔːrəb(ə)l]:adj. 可爱的,可敬重的,值得崇拜的
wisely ['waɪzli]:adv. 明智地,聪明地,精明地
对于这样一个简单的算法,速度上可以达到 0.07 毫秒 / 每帧图像。而在准确率上,我们分别在 KITTI 数据集和 Apollo 内部数据集上做了评测。在 KITTI 上取得了很好的效果,0-30 米内障碍物误差大概在 1 米左右。随着距离增大,误差会增大,但是最终误差不超过 8%。

在 Apollo 数据集上,这个简单算法也取得了不错的效果。最大误差不超过 6%。

monocular [mə'nɒkjʊlə]:adj. 单眼的,单眼用的
calibration [kælɪ'breɪʃ(ə)n]:n. 校准,刻度,标度
Apollo 中单目摄像头下的障碍物检测流程图:输入单幅图像,预测大部分参数;基于单视图度量衡,我们可以预测出剩余的参数距离和中心点坐标。

Apollo 中单目摄像头下的障碍物检测稳定快速,对繁忙路段和高速场景都可以适配,检测速度在 30Hz 以上。

Apollo 中单目摄像头下的障碍物算法已经成功入库到 Apollo 2.5 和 Apollo 3.0,并在 CIDI 等项目中使用。

Changsha Intelligent Driving Institute,CiDi:长沙智能驾驶研究院有限公司,希迪智驾
High-Dynamic Range,HDR:高动态范围图像
Low-Dynamic Range,LDR:低动态范围图像
在车辆颠簸的情况下,相机内参基本不会发生变化, 而外参可以借助在线标定 (online calibration) 得到的实时外参,提高单目测距的准确性。
单目测距的原理:
(1) 单孔成像原理 (借助内外参矩阵的帮助)。
(2) 单视图度量衡 (Single View Metrology)。
Mobileye 的测距是比较精准的,基本原理类似。
运动物体测距准确,这是考虑了上下帧的关联性 (tracking)。tracking 本身会修正物体的朝向,真实速度等等。这些都会进一步提高单目测距准确率。
IOS 12 AR 测距原理可能是利用 depth from focus/defocus 的方法,拍摄多张不同聚焦深度的图片,然后利用多张图片进行深度估计,有一定的借鉴意义。
NVIDIA®DRIVE™PX2 是开放式人工智能车辆计算平台,它可以让汽车制造商和一级汽车制造供应商加速产品的自主化和无人驾驶车辆的研发。
数据挖掘本身是一个非常重要的问题,数据挖掘一定是机器学习和人工标注的一个很好的平衡。利用一定量的标注数据,去训练一个基础模型,通过基础模型去海量数据中挖掘置信度高的样本,并添加到原始数据中再次训练,拿到新模型。不停的迭代模型,并随机挑选一些图像,进行人工验证,把错检或误检的数据 (hard example) 标注,来进一步更新模型。这个方式要注意的就是平衡人工标注和自动挖掘的数量。在合理成本下得到最多最优质的标注数据 (来自机器或人工标注)。
无人车感知是一个多传感器融合的复杂系统,单目是一个很好的方式,但它有自己明显的问题,例如依赖训练样本。对无法识别的障碍物,我们需要依赖激光雷达和多普勒雷达来进行检测,这些传感器本身测距非常准确。这些传感器与相机的融合,会极大提高单目测距的准确性。
模型的训练依赖于数据的高质量、损失函数的设计、数据增强的实现等等。最初的算法验证可以借助 KITTI 或者 Apollo 开放的一些训练集来实现 (如 ApolloScape)。
算法复杂度和摄像头内置芯片的计算能力、功耗之间的博弈。从原始算法验证的角度,工控机来负责运算更灵活一些,因为摄像头选配等等需要实验。当相机硬件定型,算法定型之后,我们可以考虑更高效的模型加速,算法固化到硬件等等方式,降低功耗,并集成到摄像机模块里,成为 smart camera。
随着距离的增加,测距精度会降低。需要其它传感器帮助,或者借助 tracking 来提高预测精度。传感器融合是感知最重要的核心思想。不同传感器要求挖掘自身优势,并认知自身劣势,达到相互弥补。摄像头测距的精度是远不如激光雷达,多普勒雷达的,这是传感器物理属性所致。
图像预处理 gain control 和 tone mapping 有效避免阳光直射造成摄像头的眩光。
3D BBOX 会稳定显示在图像中,但我们目的主要是问题的测距、测角度、测障碍物大小和速度。
如果物体有遮挡,我们要求神经网络能预测出遮挡程度 (百分比),并根据遮挡的情况,去给出更准确的距离判断。
可以依据传统视觉进行帧与帧之间匹配,建立合适的物体跟踪模型,找到障碍物的位移,进而推断出障碍物的速度和加速度。单帧图像无法预测速度和加速度。
算法输入为 RGB,对像素大小没有特别偏好。1080P、720P 或者类似的大小都可以。
通过相机到激光雷达的标定矩阵,可以在 2D 和 3D 点云中进行点到点的坐标转换。通过标注激光点云,我们可以便利的得到物体尺寸和偏角。
测量精度随距离增大而降低,这是 camera 本身的问题。可以借助长焦相机,或者通过和多普勒雷达融合,得到精准的距离估算。
目前算法基本依赖内参标定,一般不会出现标定很差的情况。
YOLO 3D 目前识别大概七大类,包括车、人、自行车、交通锥桶等常见的路面上障碍物。路灯,树木测距不在涵盖范围内。
查询表,可以定义单位标尺 (例如在图像某个 2d 位置上,高 1 米的障碍物在图像上有多高)。通过单位标尺对应的像素数目,可以快速查到车的真实高度等。
标定的参数和车辆已经和传感器相关联,可以使用 Apollo 标定服务,快速标定。
车灯有检测,但准确率不能做到极高,不是强前提。
毫米波雷达只给了较为粗略的类别识别,在融合时基本不占权重,不会影响最终结果。
可以使用大规模开源的 Apollo Scope 做一些研发。
锚都是通过非监督学习的聚类方式生成,不是手工设计或者直接 CNN 学出。
颠簸的影响可以通过在线标定来解决。平面假设只是为了物体的测距,这种情况下,其它传感器的融合辅助测距是必不可少的步骤。
左右的对称翻转是有意义的,而上下是不会翻转的。
预测这些参数是为了测距服务,测距的误差大概在 6% ~ 8%,在之后的融合中,借助 radar 的准确测距,可以弥补这些误差。。
室内低速,建议使用双目测距。不受障碍物类别等限制,而且不需要大量训练数据。
在地面有较大坡度不平的场景,单目 camera 的检测结果在传感器融合处理时,参考会相应的降低。但是融合时是做 graph-graph 间的匹配。不需要过分担心融合时摄像头的准确率问题。
在公开数据集上区分度最好的模型,在真实业务场景下表现不好,甚至很差,可能需要采集一些新的数据,做模型的再训练,微调。
车道线来校准,两条平行线无穷远处相交。通过车道线等信息,可以帮助我们在线调整传感器标定。
摄像头高度和障碍物不一致时,只要能在摄像头中观测到障碍物,测距都不受影响。