基于hadoop2.6.0搭建5个节点的分布式集群
1、前言
我们使用hadoop2.6.0版本配置Hadoop集群,同时配置NameNode+HA、ResourceManager+HA,并使用zookeeper来管理Hadoop集群
2、规划
1、主机规划
| hadoop1/ 192.168.56.131 |
hadoop2/ 192.168.56.132 |
hadoop3/ 192.168.56.133 |
hadoop4/ 192.168.56.134 |
hadoop5/ 192.168.56.135 |
|
| namenode |
是 |
是 |
否 |
否 |
否 |
| datanode |
否 |
否 |
是 |
是 |
是 |
| resourcemanager |
是 |
是 |
否 |
否 |
否 |
| journalnode |
是 |
是 |
是 |
是 |
是 |
| zookeeper |
是 |
是 |
是 |
是 |
是 |
Journalnode和ZooKeeper保持奇数个,最少不少于3个节点
2、软件规划
| 软件 |
版本 |
位数 |
说明 |
| centos |
6.5 |
64 |
|
| jdk |
1.7 |
64 |
稳定版本 |
| zookeeper |
3.4.6 |
稳定版本 |
|
| hadoop |
2.6.0 |
稳定版本 |
3、用户规划
| 节点名称 |
用户组 |
用户 |
密码 |
| hadoop1 |
hadoop |
hadoop |
123456 |
| hadoop2 |
hadoop |
hadoop |
123456 |
| hadoop3 |
hadoop |
hadoop |
123456 |
| hadoop4 |
hadoop |
hadoop |
123456 |
| hadoop5 |
hadoop |
hadoop |
123456 |
4、目录规划
| 名称 |
路径 |
| 所有软件目录 |
/usr/hadoop/app/ |
| 所有数据和日志目录 |
/usr/hadoop/data/ |
3、集群安装前的环境检查
1、修改主机名
将5个节点分别修改为hadoop1、hadoop2、hadoop3、hadoop4、hadoop5
修改主机名,请参考“修改主机名”
2、hosts文件检查
所有节点(hadoop1、hadoop2、hadoop3、hadoop4、hadoop5)的hosts文件都要配置静态ip与hostname之间的对应关系
192.168.56.131 hadoop1
192.168.56.132 hadoop2
192.168.56.133 hadoop3
192.168.56.134 hadoop4
192.168.56.135 hadoop5
具体请参考,“配置hosts文件”
3、禁用防火墙
永久关闭hadoop1、hadoop2、hadoop3、hadoop4、hadoop5这5个节点的防火墙
具体请参考,“防火墙”
4、配置SSH免密码通信
下面对hadoop1节点上的root用户配置ssh
1、输入“ssh-keygen -t rsa”,生成秘钥

2、使用“cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys”命令,把公钥复制到认证文件(authorized_keys)中,如下所示

3、确保.ssh目录的权限是700(使用chmod 700 .ssh命令修改),确保.ssh目录下所有文件(authorized_key、id_rsa、id_rsa.pub)的权限是600(使用chmod 600 .ssh/*命令修改),如下所示

4、输入“ssh hadoop1”登录,第一次登录需要输入yes,以后就不需要输入啦

对hadoop2、hadoop3、hadoop4、hadoop5这4个节点上的root用户也配置ssh,配置过程和上述在hadoop1上为root用户配置ssh的过程是一样
5、在hadoop2、hadoop3、hadoop4、hadoop5这4个节点上都执行一次“cat ~/.ssh/id_rsa.pub | ssh root@hadoop1 'cat >> ~/.ssh/authorized_keys'”命令,将这4个节点上的共钥id_ras.pub拷贝到hadoop1中的authorized_keys文件中,如下




拷贝完成后,hadoop1中的authorized_keys文件内容如下

6、将hadoop1中的authorized_keys文件分发到其他节点(hadoop2、hadoop3、hadoop4、hadoop5)上,在hadoop1上,使用scp -r ~/.ssh/authorized_keys root@主机名:~/.ssh/ 命令分发,效果如下
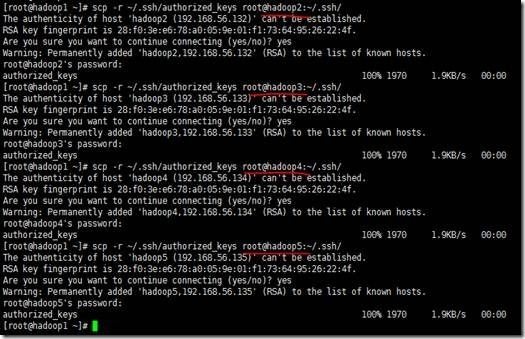
7、然后测测看看,出现如下信息,表示配置成功

说明:第一次可能会出现如下信息,输入yes就可以了,以后就不会再出现啦

5、脚本工具的使用
shell脚本如下,如果安装目录有所变动,请根据需要修改
deploy.conf
#### NOTES
# There is crontab job using this config file which would compact log files and remove old log file.
# please be carefully while modifying this file until you know what crontab exactly do
#hdp
hadoop1,all,namenode,zookeeper,resourcemanager,
hadoop2,all,slave,namenode,zookeeper,resourcemanager,
hadoop3,all,slave,datanode,zookeeper,
hadoop4,all,slave,datanode,zookeeper,
hadoop5,all,slave,datanode,zookeeper,#!/bin/bash
#set -x
if [ $# -lt 3 ]
then
echo "Usage: ./deply.sh srcFile(or Dir) descFile(or Dir) MachineTag"
echo "Usage: ./deply.sh srcFile(or Dir) descFile(or Dir) MachineTag confFile"
exit
fi
src=$1
dest=$2
tag=$3
if [ 'a'$4'a' == 'aa' ]
then
confFile=/usr/hadoop/tools/deploy.conf
else
confFile=$4
fi
if [ -f $confFile ]
then
if [ -f $src ]
then
for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
do
scp $src $server":"${dest}
done
elif [ -d $src ]
then
for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
do
scp -r $src $server":"${dest}
done
else
echo "Error: No source file exist"
fi
else
echo "Error: Please assign config file or run deploy.sh command with deploy.conf in same directory"
fi
#!/bin/bash
#set -x
if [ $# -lt 2 ]
then
echo "Usage: ./runRemoteCmd.sh Command MachineTag"
echo "Usage: ./runRemoteCmd.sh Command MachineTag confFile"
exit
fi
cmd=$1
tag=$2
if [ 'a'$3'a' == 'aa' ]
then
confFile=/usr/hadoop/tools/deploy.conf
else
confFile=$3
fi
if [ -f $confFile ]
then
for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
do
echo "*******************$server***************************"
ssh $server "source /etc/profile; $cmd"
done
else
echo "Error: Please assign config file or run deploy.sh command with deploy.conf in same directory"
fi
1、在hadoop1节点上,创建/usr/hadoop/tools目录,如下所示
2、将脚本通过rz命令上传到/usr/hadoop/tools目录

具体使用rz命令,请参考“上传下载rz、sz命令”
3、为后缀*.sh的文件增加执行权限

具体使用chmod命令,请参考“权限chmod命令”
4、将/usr/hadoop/tools目录配置到PATH路径中
![]()
![]()
6、集群安装前的环境配置
1、时钟同步
下面通过脚本对所有节点(hadoop1、hadoop2、hadoop3、hadoop4、hadoop5)进行时钟同步
1、输入runRemoteCmd.sh "cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime" all

2、输入runRemoteCmd.sh "ntpdate pool.ntp.org" all

具体请参考,“时钟同步”
2、创建hadoop用户组、hadoop用户以及设置密码
下面通过脚本在hadoop1、hadoop2、hadoop3、hadoop4、hadoop5这5个节点上分别创建hadoop用户组、hadoop用户以及设置密码123456
1、创建hadoop用户组

2、创建hadoop用户,并指定用户的组为hadoop

3、为hadoop用户设置密码123456

具体请参考,“用户相关命令”
3、创建/usr/hadoop/app/、/usr/hadoop/data/目录, 并修改/usr/hadoop目录的所有人,所有组为hadoop
下面通过脚本在hadoop1、hadoop2、hadoop3、hadoop4、hadoop5这5个节点上分别创建/usr/hadoop/app/、/usr/hadoop/data/目录,并修改/usr/hadoop目录的所有人,所有组为hadoop
1、创建/usr/hadoop/app/目录

2、创建/usr/hadoop/data/目录

3、修改/usr/hadoop目录的所有人,所有组为hadoop

具体请参考,“目录相关命令”
4、为每个节点中hadoop用户配置ssh,这里为了省事,直接拷贝相应节点中root用户的配置给对应的hadoop用户,默认hadoop家目录是/home/hadoop
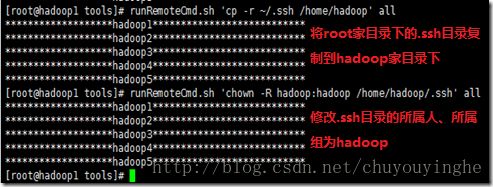
接着随意选择一个节点,这里选择hadoop4节点,以hadoop用户登录,然后进行ssh测试,如果出现如下信息,表示配置成功

7、JDK安装
1、将本地下载好的jdk1.7,上传至hadoop1节点下的/home/hadoop/app目录中

可以使用rz上传,请参考“上传下载rz、sz命令”
2、解压jdk

删除安装包
![]()
3、配置环境变量


使配置文件生效
![]()
4、查看jdk是否安装成功

出现以上信息,说明配置成功
5、通过脚本,将hadoop1中的jdk安装包分发到其他节点上
切换到hadoop用户
![]()
![]()
在hadoop2, hadoop3, hadoop4, hadoop5节点上,重复步骤3、4,完成jdk配置
8、Zookeeper安装
1、上传zookeeper到hadoop1节点
1、将本地下载好的zookeeper-3.4.6.tar.gz安装包,上传至hadoop1节点下的/home/hadoop/app目录下

可以使用rz上传,请参考“上传下载rz、sz命令”
2、解压

3、删除zookeeper-3.4.6.tar.gz安装包
4、重命名

2、修改Zookeeper中的配置文件
1、复制一个zoo.cfg文件

2、编辑zoo.cfg文件
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#数据文件目录
dataDir=/usr/hadoop/data/zookeeper/zkdata
#日志目录
dataLogDir=/usr/hadoop/data/zookeeper/zkdatalog
# the port at which the clients will connect
#默认端口号
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
server.4=hadoop4:2888:3888
server.5=hadoop5:2888:38883、通过脚本deploy.sh将Zookeeper安装目录拷贝到其他节点上面,输入deploy.sh zookeeer/ /usr/hadoop/app slave,如下所示
4、通过脚本runRemoteCmd.sh在所有节点上面创建数据目录、日志目录
1、创建数据目录(runRemoteCmd.sh "mkdir -p /usr/hadoop/data/zookeeper/zkdata" all)

2、创建日志目录(runRemoteCmd.sh "mkdir -p /usr/hadoop/data/zookeeper/zkdatalog" all)

5、分别在hadoop1、hadoop2、hadoop3、hadoop4、hadoop5节点上,进入/usr/hadoop/data/zookeeper/zkdata目录下,创建文件myid,里面的内容分别填充为:1、2、3、4、5, 这里我们以hadoop1为例
1、进入/usr/hadoop/data/zookeeper/zkdata目录
2、编辑myid文件

3、按esc,输入“:x”保存退出
6、配置Zookeeper环境变量
1、vi /etc/profile, 输入内容,然后按esc,输入”:x”,保存退出,最后,输入source /etc/profile,使其立马生效



2、其他节点和hadoop1一样的配置
7、查看启动情况
1、查看hadoop1节点上Zookeeper是否配置成功
1、启动Zookeeper

2、出现如下信息,说明配置成功
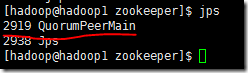
3、关闭Zookeeper

2、查看所有节点上Zookeeper是否配置成功
1、使用runRemoteCmd.sh 脚本,启动所有节点上面的Zookeeper

2、查看所有节点上的QuorumPeerMain进程是否启动

3、查看所有节点上Zookeeper的状态

出现4个follower,一个leader,表示Zookeeper安装成功
9、hadoop安装
1、上传hadoop
1、将下载好的hadoop-2.6.0.tar.gz安装包,上传至hadoop1节点中的/usr/hadoop/app目录下

2、解压hadoop-2.6.0.tar.gz

3、删除hadoop-2.6.0.tar.gz安装包
4、重命名

2、配置hadoop家目录下的.bash_profile

![]()

![]()
3、hdfs
1、切换到/usr/hadoop/app/hadoop/etc/hadoop/目录下
2、配置hdfs
1、配置hadoop-env.sh
![]()
2、配置core-site.
fs.defaultFS
hdfs://cluster1
hadoop.tmp.dir
/usr/hadoop/data/tmp
ha.zookeeper.quorum
hadoop1:2181,hadoop2:2181,hadoop3:2181,hadoop4:2181,hadoop5:2181
3、配置hdfs-site.xml
dfs.replication
3
dfs.permissions
false
dfs.permissions.enabled
false
dfs.nameservices
cluster1
dfs.ha.namenodes.cluster1
nameService1,nameService2
dfs.namenode.rpc-address.cluster1.nameService1
hadoop1:9000
dfs.namenode.http-address.cluster1.nameService1
hadoop1:50070
dfs.namenode.rpc-address.cluster1.nameService2
hadoop2:9000
dfs.namenode.http-address.cluster1.nameService2
hadoop2:50070
dfs.ha.automatic-failover.enabled
true
dfs.namenode.shared.edits.dir
qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485;hadoop4:8485;hadoop5:8485/cluster1
dfs.client.failover.proxy.provider.cluster1
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.journalnode.edits.dir
/usr/hadoop/data/journaldata/jn
dfs.ha.fencing.methods
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
10000
dfs.namenode.handler.count
100
4、配置 slave
hadoop3
hadoop4
hadoop53、向其他节点分发hadoop安装包
4、配置完毕后,启动hdfs
1、启动所有节点上面的Zookeeper进程(runRemoteCmd.sh "/usr/hadoop/app/zookeeper/bin/zkServer.sh start" zookeeper)
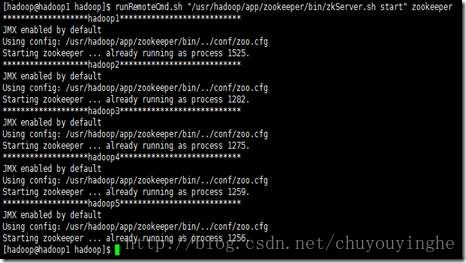
2、启动所有节点上面的journalnode进程(runRemoteCmd.sh "/usr/hadoop/app/hadoop/sbin/hadoop-daemon.sh start journalnode" all)

3、在hadoop1(主节点)上执行格式化
1、切换到/usr/hadoop/app/hadoop/
2、namenode格式化(bin/hdfs namenode -format)
3、格式化高可用(bin/hdfs zkfc -formatZK)
![]()
4、启动namenode
4、与此同时,需要在hadoop2(备节点)上执行数据同步(bin/hdfs namenode -bootstrapStandby)
5、hadoop2同步完数据后,紧接着在hadoop1节点上,按下ctrl+c来结束namenode进程。 然后关闭所有节点上面的journalnode进程(runRemoteCmd.sh "/usr/hadoop/app/hadoop/sbin/hadoop-daemon.sh stop journalnode" all)

6、如果上面操作没有问题,我们可以一键启动hdfs所有相关进程

7、验证是否启动成功


出现上面信息,说明启动成功
8、使用bin/hdfs haadmin -failover nameService1 nameService2命令,将hadoop2切换成active, hadoop1切换成standby,其中,nameService1、nameService2是在hdfs-site.xml文件中的dfs.ha.namenodes. clusterl指定的
效果如下:

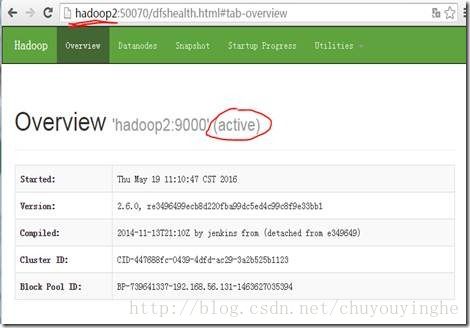
9、上传文件至hdfs

如果以上操作都没有问题说明hdfs配置成功
4、yarn
1、yarn配置
1、配置mapred-site.xml(默认没有mapred-site.xml文件,从mapred-site.xml.template文件复制一份,改名为mapred-site.xml就可以)
mapreduce.framework.name
yarn
2、配置yarn-site.xml
yarn.resourcemanager.connect.retry-interval.ms
2000
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.ha.automatic-failover.enabled
true
yarn.resourcemanager.ha.automatic-failover.embedded
true
yarn.resourcemanager.cluster-id
yarn-rm-cluster
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hadoop1
yarn.resourcemanager.hostname.rm2
hadoop2
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.zk.state-store.address
hadoop1:2181,hadoop2:2181,hadoop3:2181,hadoop4:2181,hadoop5:2181
yarn.resourcemanager.zk-address
hadoop1:2181,hadoop2:2181,hadoop3:2181,hadoop4:2181,hadoop5:2181
yarn.resourcemanager.address.rm1
hadoop1:8032
yarn.resourcemanager.scheduler.address.rm1
hadoop1:8034
yarn.resourcemanager.webapp.address.rm1
hadoop1:8088
yarn.resourcemanager.address.rm2
hadoop2:8032
yarn.resourcemanager.scheduler.address.rm2
hadoop2:8034
yarn.resourcemanager.webapp.address.rm2
hadoop2:8088
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce_shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
2、向其他节点同步yarn配置(deploy.sh etc/ /usr/hadoop/app/hadoop/ all)
3、启动YARN
1、在hadoop1节点上执行(sbin/start-yarn.sh)

2、在hadoop2节点上面执行(sbin/yarn-daemon.sh start resourcemanager)
3、查看web页面
1、访问hadoop1的web页面,如下

2、访问hadoop2的web页面,如下

4、查看ResourceManager状态

resourceManager的名字是yarn.resourcemanager.ha.rm-ids属性指定的
5、Wordcount示例测试
/usr/hadoop/app/hadoop/bin/hadoop jar /usr/hadoop/app/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /buaa/a.txt /buaa/out
如果上面执行没有异常,说明YARN安装成功
至此,基于hadoop2.6搭建5个节点的分布式集群搭建完毕
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
hadoop配置:下载
shell脚本:下载
转自:https://www.cnblogs.com/codeOfLife/p/5512137.html