【十八掌●武功篇】第十掌:Hive之基本语法
这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:![]() 大数据技术●降龙十八掌
大数据技术●降龙十八掌
- 小系列列表
-
【十八掌●武功篇】第十掌:Hive之基本语法
【十八掌●武功篇】第十掌:Hive之原理与优化
【十八掌●武功篇】第十掌:Hive之高级知识
【十八掌●武功篇】第十掌:Hive之安装过程实践
一、前言
我写这篇文章的目的是尽可能全面地对Hive进行入门介绍,这篇文章是基于hive-1.0.0版本介绍的,这个版本的Hive是运行在MapReduce上的,新的版本可以运行在Tez上,会有一些不同。
Hive是对数据仓库进行管理和分析数据的工具。如果你会MYSQL或者MSSQL,就会发现Hive是那么的简单,简单到甚至不用学就可以使用Hive做出业务所需要的东西。
但是Hive和MYSQL毕竟不同,执行原理、优化方法,底层架构都完全不相同。
大数据离线分析使用Hive已经成为主流,基于工作中Hive使用的经验,我整理了这个入门级别的文章,希望能给想入门的同学提供一些帮助。
二、Hive简介
Facebook为了解决海量日志数据的分析而开发了Hive,后来开源给了Apache软件基金会。
官网定义:
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL.
Hive是一种用类SQL语句来协助读写、管理那些存储在分布式存储系统上大数据集的数据仓库软件。
Hive的几个特点
Hive最大的特点是通过类SQL来分析大数据,而避免了写MapReduce程序来分析数据,这样使得分析数据更容易。
数据是存储在HDFS上的,Hive本身并不提供数据的存储功能
Hive是将数据映射成数据库和一张张的表,库和表的元数据信息一般存在关系型数据库上(比如MySQL)。
数据存储方面:它能够存储很大的数据集,并且对数据完整性、格式要求并不严格。
数据处理方面:因为Hive语句最终会生成MapReduce任务去计算,所以不适用于实时计算的场景,它适用于离线分析。
三、基本数据类型
Hive支持关系型数据中大多数基本数据类型,同时Hive中也有特有的三种复杂类型。
下面的表列出了Hive中的常用基本数据类型:
| 数据类型 | 长度 | 备注 |
|---|---|---|
| Tinyint | 1字节的有符号整数 | -128~127 |
| SmallInt | 1个字节的有符号整数 | -32768~32767 |
| Int | 4个字节的有符号整数 | -2147483648 ~ 2147483647 |
| BigInt | 8个字节的有符号整数 | |
| Boolean | 布尔类型,true或者false | true、false |
| Float | 单精度浮点数 | |
| Double | 双精度浮点数 | |
| String | 字符串 | |
| TimeStamp | 整数 | 支持Unix timestamp,可以达到纳秒精度 |
| Binary | 字节数组 | |
| Date | 日期 | 0000-01-01 ~ 9999-12-31,常用String代替 |
四、DDL语法
创建数据库
创建一个数据库会在HDFS上创建一个目录,Hive里数据库的概念类似于程序中的命名空间,用数据库来组织表,在大量Hive的情况下,用数据库来分开可以避免表名冲突。Hive默认的数据库是default。
创建数据库例子:
hive> create database if not exists user_db;查看数据库定义
Describe 命令来查看数据库定义,包括:数据库名称、数据库在HDFS目录、HDFS用户名称。
hive> describe database user_db;
OK
user_db hdfs://bigdata-51cdh.chybinmy.com:8020/user/hive/warehouse/user_db.db hadoop USERuser_db是数据库名称。
hdfs://bigdata-51cdh.chybinmy.com:8020/user/hive/warehouse/user_db.db 是user_db库对应的存储数据的HDFS上的根目录。
查看数据库列表
hive> show databases;
OK
user_db
default删除数据库
删除数据库时,如果库中存在数据表,是不能删除的,要先删除所有表,再删除数据库。添加上cascade后,就可以先自动删除所有表后,再删除数据库。(友情提示:慎用啊!)删除数据库后,HDFS上数据库对应的目录就被删除掉了。
hive> drop database if exists testdb cascade;切换当前数据库
hive> use user_db;创建普通表
hive> create table if not exists userinfo
> (
> userid int,
> username string,
> cityid int,
> createtime date
> )
> row format delimited fields terminated by '\t'
> stored as textfile;
OK
Time taken: 2.133 seconds以上例子是创建表的一种方式,如果表不存在,就创建表userinfo。row format delimited fields terminated by ‘\t’ 是指定列之间的分隔符;stored as textfile是指定文件存储格式为textfile。
创建表一般有几种方式:
create table 方式:以上例子中的方式。
create table as select 方式:根据查询的结果自动创建表,并将查询结果数据插入新建的表中。
create table like tablename1 方式:是克隆表,只复制tablename1表的结构。复制表和克隆表会在下面的Hive数据管理部分详细讲解。
创建外部表
外部表是没有被hive完全控制的表,当表删除后,数据不会被删除。
hive> create external table iislog_ext (
> ip string,
> logtime string
> )
> ;创建分区表
Hive查询一般是扫描整个目录,但是有时候我们关心的数据只是集中在某一部分数据上,比如我们一个Hive查询,往往是只是查询某一天的数据,这样的情况下,可以使用分区表来优化,一天是一个分区,查询时候,Hive只扫描指定天分区的数据。
普通表和分区表的区别在于:一个Hive表在HDFS上是有一个对应的目录来存储数据,普通表的数据直接存储在这个目录下,而分区表数据存储时,是再划分子目录来存储的。一个分区一个子目录。主要作用是来优化查询性能。
--创建经销商操作日志表
create table user_action_log
(
companyId INT comment '公司ID',
userid INT comment '销售ID',
originalstring STRING comment 'url',
host STRING comment 'host',
absolutepath STRING comment '绝对路径',
query STRING comment '参数串',
refurl STRING comment '来源url',
clientip STRING comment '客户端Ip',
cookiemd5 STRING comment 'cookiemd5',
timestamp STRING comment '访问时间戳'
)
partitioned by (dt string)
row format delimited fields terminated by ','
stored as textfile;这个例子中,这个日志表以dt字段分区,dt是个虚拟的字段,dt下并不存储数据,而是用来分区的,实际数据存储时,dt字段值相同的数据存入同一个子目录中,插入数据或者导入数据时,同一天的数据dt字段赋值一样,这样就实现了数据按dt日期分区存储。
当Hive查询数据时,如果指定了dt筛选条件,那么只需要到对应的分区下去检索数据即可,大大提高了效率。所以对于分区表查询时,尽量添加上分区字段的筛选条件。
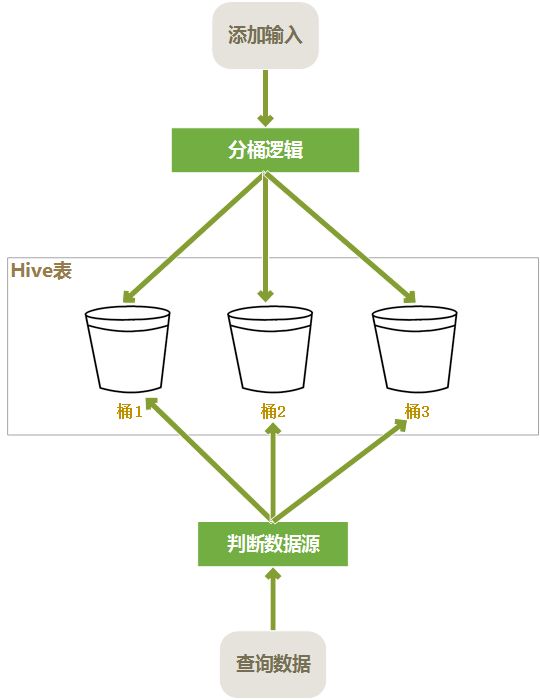
创建桶表
桶表也是一种用于优化查询而设计的表类型。创建通表时,指定桶的个数、分桶的依据字段,hive就可以自动将数据分桶存储。查询时只需要遍历一个桶里的数据,或者遍历部分桶,这样就提高了查询效率。举例:
------创建订单表
create table user_leads
(
leads_id string,
user_id string,
user_id string,
user_phone string,
user_name string,
create_time string
)
clustered by (user_id) sorted by(leads_id) into 10 buckets
row format delimited fields terminated by '\t'
stored as textfile;对这个例子的说明:
clustered by是指根据user_id的值进行哈希后模除分桶个数,根据得到的结果,确定这行数据分入哪个桶中,这样的分法,可以确保相同user_id的数据放入同一个桶中。而经销商的订单数据,大部分是根据user_id进行查询的。这样大部分情况下是只需要查询一个桶中的数据就可以了。
sorted by 是指定桶中的数据以哪个字段进行排序,排序的好处是,在join操作时能获得很高的效率。
into 10 buckets是指定一共分10个桶。
在HDFS上存储时,一个桶存入一个文件中,这样根据user_id进行查询时,可以快速确定数据存在于哪个桶中,而只遍历一个桶可以提供查询效率。
分桶表读写过程
查看有哪些表
--查询库中表
show tables;
Show TABLES '*info'; --可以用正则表达式筛选要列出的表查看表定义
查看简单定义:
describe userinfo;查看表详细信息:
describe formatted userinfo;执行结果如下所示:
| 备注 | col_name | data_type | comment |
|---|---|---|---|
| 列信息 | col_name | data_type | comment |
| NULL | NULL | ||
| userid | int | ||
| username | string | ||
| cityid | int | ||
| createtime | date | ||
| NULL | NULL | ||
| Detailed Table Information | NULL | NULL | |
| 所在库 | Database: | user_db | NULL |
| 所属HUE用户 | Owner: | admin | NULL |
| 表创建时间 | CreateTime: | Tue Aug 16 06:05:14 PDT 2016 | NULL |
| 最后访问时间 | LastAccessTime: | UNKNOWN | NULL |
| Protect Mode: | None | NULL | |
| Retention: | 0 | NULL | |
| 表数据文件在HDFS上路径 | Location: | hdfs://bigdata-51cdh.chybinmy.com:8020/user/hive/warehouse/user_db.db/userinfo | NULL |
| 表类型(内部表或者外部表) | Table Type: | MANAGED_TABLE | NULL |
| 表分区信息 | Table Parameters: | NULL | NULL |
| transient_lastDdlTime | 1471352714 | ||
| NULL | NULL | ||
| Storage Information | NULL | NULL | |
| 序列化反序列化类 | SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| mapreduce中的输入格式 | InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| mapreduce中的输出格式 | OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| 压缩 | Compressed: | No | NULL |
| 总占用数据块个数 | Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL | |
| Sort Columns: | [] | NULL | |
| Storage Desc Params: | NULL | NULL | |
| field.delim | \t | ||
| serialization.format | \t | ||
修改表
对表的修改操作有:修改表名、添加字段、修改字段。
修改表名:
--将表名从userinfo改为user_info
alter table userinfo rename to user_info;添加字段:
---在user_info表添加一个字段provinceid,int 类型
alter table user_info add columns (provinceid int );修改字段:
alter table user_info replace columns (userid int,username string,cityid int,joindate date,provinceid int);修改字段,只是修改了Hive表的元数据信息(元数据信息一般是存储在MySql中),并不对存在于HDFS中的表数据做修改。
并不是所有的Hive表都可以修改字段,只有使用了native SerDe (序列化反序列化类型)的表才能修改字段
删除表
--如果表存在,就删除。
drop table if exists user_info;五、DML语法
向Hive中加载数据
加载到普通表
可以将本地文本文件内容批量加载到Hive表中,要求文本文件中的格式和Hive表的定义一致,包括:字段个数、字段顺序、列分隔符都要一致。
这里的user_info表的表定义是以\t作为列分隔符,所以准备好数据后,将文本文件拷贝到hive客户端机器上后,执行加载命令。
load data local inpath '/home/hadoop/userinfodata.txt' overwrite into table user_info;local关键字表示源数据文件在本地,源文件可以在HDFS上,如果在HDFS上,则去掉local,inpath后面的路径是类似”hdfs://namenode:9000/user/datapath”这样的HDFS上文件的路径。
overwrite关键字表示如果hive表中存在数据,就会覆盖掉原有的数据。如果省略overwrite,则默认是追加数据。
加载完成数据后,在HDFS上就会看到加载的数据文件。
加载到分区表
load data local inpath '/home/hadoop/actionlog.txt' overwrite into table user_action_log
PARTITION (dt='2017-05-26');partition 是指定这批数据放入分区2017-05-26中。
加载到分桶表
------先创建普通临时表
create table user_leads_tmp
(
leads_id string,
user_id string,
user_id string,
user_phone string,
user_name string,
create_time string
)
row format delimited fields terminated by ','
stored as textfile;
------数据载入临时表
load data local inpath '/home/hadoop/lead.txt' overwrite into table user_leads_tmp;
------导入分桶表
set hive.enforce.bucketing = true;
insert overwrite table user_leads select * from user_leads_tmp;set hive.enforce.bucketing = true; 这个配置非常关键,为true就是设置为启用分桶。
导出数据
--导出数据,是将hive表中的数据导出到本地文件中。
insert overwrite local directory '/home/hadoop/user_info.bak2016-08-22 '
select * from user_info;去掉local关键字,也可以导出到HDFS上。
插入数据
insert select 语句
上一节分桶表数据导入,用到从user_leads_tmp表向user_leads表中导入数据,用到了insert数据。
insert overwrite table user_leads select * from user_leads_tmp;这里是将查询结果导入到表中,overwrite关键字是覆盖目标表中的原来数据。如果缺省,就是追加数据。
如果是插入数据的表是分区表,那么就如下所示:
insert overwrite table user_leads PARTITION (dt='2017-05-26')
select * from user_leads_tmp;一次遍历多次插入
from user_action_log
insert overwrite table log1 select companyid,originalstring where companyid='100006'
insert overwrite table log2 select companyid,originalstring where companyid='10002'每次hive查询,都会将数据集整个遍历一遍。当查询结果会插入多个表中时,可以采用以上语法,将一次遍历写入多个表,以达到提高效率的目的。
复制表
复制表是将源表的结构和数据复制并创建为一个新表,复制过程中,可以对数据进行筛选,列可以进行删减。
create table user_leads_bak
row format delimited fields terminated by '\t'
stored as textfile
as
select leads_id,user_id,'2016-08-22' as bakdate
from user_leads
where create_time<'2016-08-22';上面这个例子是对user_leads表进行复制备份,复制时筛选了2016-08-22以前的数据,减少几个列,并添加了一个bakdate列。
克隆表
克隆表时会克隆源表的所有元数据信息,但是不会复制源表的数据。
--克隆表user_leads,创建新表user_leads_like
create table user_leads_like like user_leads;备份表
备份是将表的元数据和数据都导出到HDFS上。
export table user_action_log partition (dt='2016-08-19')
to '/user/hive/action_log.export'这个例子是将user_action_log表中的一个分区,备份到HDFS上,to后面的路径是HDFS上的路径。
还原表
将备份在HDFS上的文件,还原到user_action_log_like表中。
import table user_action_log_like from '/user/hive/action_log.export';六、HQL语法
Select 查询
指定列表
select * from user_leads;
select leads_id,user_id,create_time from user_leads;
select e.leads_id from user_leads e;函数列
select companyid,upper(host),UUID(32) from user_action_log;可以使用hive自带的函数,也可以是使用用户自定义函数。
上面这个例子upper()就是hive自带函数,UUID()就是用户自定义函数。
关于函数详细介绍,可以参考后面的章节。
算数运算列
select companyid,userid, (companyid + userid) as sumint from user_action_log;
可以进行各种算数运算,运算结果做为结果列。
| 运算符 | 描述 | 运算符 | 描述 |
|---|---|---|---|
| A+B | 数字相加 | A-B | 数字相减 |
| A*B | 相乘 | A/B | 相除 |
| A%B | 模除 |
限制返回条数
类似于sql server里的top N,或者mysql里的limit。
select * from user_action_log limit 100;Case When Then语句
---case when 两种写法
select case companyid when 0 then '未登录' else companyid end from user_action_log;
select case when companyid=0 then '未登录' else companyid end from user_action_log;这个例子,判断companyid值,如果为0则显示为未登录,如果不为0,则返回companyid的值。
Where筛选
| 操作符 | 说明 | 操作符 | 说明 |
|---|---|---|---|
| A=B | A等于B就返回true,适用于各种基本类型 | A<=>B | 都为Null则返回True,其他和=一样 |
| A<>B | 不等于 | A!=B | 不等于 |
A| 小于 |
A<=B |
小于等于 |
|
| A>B | 大于 | A>=B | 大于等于 |
| A Between B And C | 筛选A的值处于B和C之间 | A Not Between B And C | 筛选A的值不处于B和C之间 |
| A Is NULL | 筛选A是NULL的 | A Is Not NULL | 筛选A值不是NULL的 |
| A Link B | %一个或者多个字符_一个字符 | A Not Like B | %一个或者多个字符_一个字符 |
| A RLike B | 正则匹配 | ||
Group By 分组
Hive不支持having语句,有对group by 后的结果进行筛选的需求,可以先将筛选条件放入group by的结果中,然后在包一层,在外边对条件进行筛选。
如果需要进行如下查询:
SELECT col1 FROM t1 GROUP BY col1 HAVING SUM(col2) > 10
可以用下面这种方式实现:
SELECT col1 FROM
(SELECT col1, SUM(col2) AS col2sum
FROM t1 GROUP BY col1
) t2
WHERE t2.col2sum > 10子查询
Hive对子查询的支持有限,只允许在 select from 后面出现。比如:
---只支持如下形式的子查询
select * from (
select userid,username from user_info i where i.userid='10595'
) a;
---不支持如下的子查询
select
(select username from user_info i where i.userid=d.user_id)
from user_leads d where d.user_id='10595';七、JOIN
Hive Join的限制
只支持等值连接
Hive支持类似SQL Server的大部分Join操作,但是注意只支持等值连接,并不支持不等连接。原因是Hive语句最终是要转换为MapReduce程序来执行的,但是MapReduce程序很难实现这种不等判断的连接方式。
----等值连接
select lead.* from user_leads lead
left join user_info info
on lead.user_id=info.userid;
---不等连接(不支持)
select lead.* from user_leads lead
left join user_info info
on lead.user_id!=info.userid;连接谓词中不支持or
---on 后面的表达式不支持or
select lead.* from user_leads lead
left join user_info info
on lead.user_id=info.userid or lead.leads_id=0;Inner join
内连接同SQL Sever中的一样,连接的两个表中,只有同时满足连接条件的记录才会放入结果表中。
Left join
同SQL Server中一样,两个表左连接时,符合Where条件的左侧表的记录都会被保留下来,而符合On条件的右侧的表的记录才会被保留下来。
Right join
同Left Join相反,两个表左连接时,符合Where条件的右侧表的记录都会被保留下来,而符合On条件的左侧的表的记录才会被保留下来。
Full join
Full Join会将连接的两个表中的记录都保留下来。
Left Semi-Join ( exists 语句)
SQL Server中有exists语句,类似下面的语句,但是Hive中不支持 Exists语句。
--SQL Sever中的exists语句,但是hive中不支持
SELECT i.* FROM userInfo i
WHERE EXISTS (SELECT 1 FROM userScopeRelation s WHERE s.userInfoId=i.userInfoID AND s.CompanyID=i.CompanyID
)对于这种需求,Hive使用Left Semi-Join(左半开连接)来解决。
SELECT i.* from userInfo i left semi-join userScopeRelation s
on i.userInfoId=s.userInfoId and i.CompanyID=s.CompanyID但是这里注意,select 后面的列,不能有left semi-join右边表的字段,只能是左边表的字段。
八、排序
Order By
select * from user_leads order by user_idHive中的Order By达到的效果和SQL Server中是一样的,会对查询结果进行全局排序,但是Hive语句最终要转换为MapReduce程序放到Hadoop分布式集群上去执行,Order By这样的操作,肯定要在Map后汇集到一个Reduce上执行,如果结果数据量大,那就会造成Reduce执行相当漫长。
所以,Hive中尽量不要用Order By,除非非常确定结果集很小。
但是排序的需求总是有的,Hive中使用下面的几种排序来满足需求。
Sort By
select * from user_leads sort by user_id这个例子中,Sort By是在每个reduce中进行排序,是一个局部排序,可以保证每个Reduce中是按照user_id进行排好序的,但是全局上来说,相同的user_id可以被分配到不同的Reduce上,虽然在各个Reduce上是排好序的,但是全局上不一定是排好序的。
Distribute By 和 Sort By
--Distribute By 和Sort By实例
select * from user_leads where user_id!='0'
Distribute By cast(user_id as int) Sort by cast(user_id as int);Distribute By 指定map输出结果怎么样划分后分配到各个Reduce上去,比如Distribute By user_id,就可以保证user_id字段相同的结果被分配到同一个reduce上去执行。然后再指定Sort By user_id,则在Reduce上进行按照user_id进行排序。
但是这种还是不能做到全局排序,只能保证排序字段值相同的放在一起,并且在reduce上局部是排好序的。
需要注意的是Distribute By 必须写在Sort By前面。
Cluster By
如果Distribute By和Sort By的字段是同一个,可以简写为 Cluster By.
select * from user_leads where user_id!='0'
Cluster By cast(user_id as int) ;常见全局排序需求
常见的排序需求有两种:要求最终结果是有序的、按某个字段排序后取出前N条数据。
最终结果是有序的
最终分析结果往往是比较小的,因为客户不太可能最终要的是一个超级大数据集。所以实现方式是先得到一个小结果集,然后在得到最终的小结果集上使用order by 进行排序。
select * from (
select user_id,count(leads_id) cnt from user_leads
where user_id!='0'
group by user_id
) a order by a.cnt;这个语句让程序首先执行group by语句获取到一个小结果集,group by 过程中是不指定排序的,然后再对小结果集进行排序,这样得到的最终结果是全局排序的。
取前N条
select a.leads_id,a.user_name from (
select leads_id,user_name from user_leads
distribute by length(user_name) sort by length(user_name) desc limit 10
) a order by length(a.user_name) desc limit 10;这个语句是查询user_name最长的10条记录,实现是先根据user_name的长度在各个Reduce上进行排序后取各自的前10个,然后再从10*N条的结果集里用order by取前10个。
这个例子一定要结合MapReduce的执行原理和执行过程才能很好的理解,所以这个最能体现:看Hive语句要以MapReduce的角度看。
九、自定义函数
Hive内置函数
Hive中自带了大量的内置函数,详细可参看如下资源:
官方文档:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-Built-inFunctions.
网友整理的中文文档:http://blog.csdn.net/wisgood/article/details/17376393.
开发过程中应该尽量使用Hive内置函数,毕竟Hive内置函数经过了大量的测试,性能普遍较好,任何一点性能上的问题在大数据量上跑时候都会被放大。
自定义函数
同SQL Server一样,Hive也允许用户自定义函数,这大大扩展了Hive的功能,Hive是用Java语言写的,所以自定义函数也需要用Java来写。
编写一个Hive的自定义函数,需要新建一个Java类来继承UDF类并实现evaluate()函数,evaluate()函数中编写自定义函数的实现逻辑,返回值给Hive使用,需要注意的是,evaluate()函数的输入输出都必须是Hadoop的数据类型,以便可以被MapReduce程序来进行序列化反序列化。编写完成后将Java程序打成Jar包,在Hive会话中载入Jar包来使用自定义函数。
在执行Hive语句时,遇到一个自定义函数就会实例化一个类,并执行对应的evaluate()函数,每行输入都会调用一次evaluate()函数,所以在编写自定义函数时,一定要注意大数据量时的资源占用问题。
Hive中的自定义函数依据输入输出数据的个数,分为以下几类:
UDF用户自定义函数(一进一出)
这种是最普通最常见的自定义函数,类似内置函数length()、year()等函数,输入为一个值,输出也为一个值。下面是一个获取唯一ID的自定义函数例子:
package com.autohome.ics.bigdata.common.Date;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.ql.udf.UDFType;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import java.util.Date;
/*
生成一个指定长度的随机字符串(最长为36位)
*/
@org.apache.hadoop.hive.ql.exec.Description(name = "UUID",
extended = "示例:select UUID(32) from src;",
value = "_FUNC_(leng)-生成一个指定长度的随机字符串(最长为36位)")
@UDFType(deterministic = false)
public class UUID extends UDF {
public Text evaluate(IntWritable leng) {
String uuid = java.util.UUID.randomUUID().toString();
int le = leng.get();
le = le > uuid.length() ? uuid.length() : le;
return new Text(uuid.substring(0, le));
}
/*
生成一个随机字符串
*/
public Text evaluate() {
String uuid = java.util.UUID.randomUUID().toString();
return new Text(uuid);
}
}这个实例是获取一个指定长度的随机字符串自定义函数,这个自定义函数创建了一个类UUID,继承于UDF父类。
UUID类要实现evaluate函数,获取一个指定长度的随机字符串。
evaluate函数是可以有多个重载的。
Description是自定义函数的描述信息。
这里有一个参数deterministic,是标识这个自定义函数是否是那种输入确定时输出就确定的函数,默认是true,比如length函数就是如果输入同一个值,那么输出肯定是一致的,但是我们这里的UUID就算输入确定,但是输出也是不确定的,所以要将deterministic设置为false。
UDAF用户自定义聚合函数(多进一出)
UDAF是自定义聚合函数,类似于sum()、avg(),这一类函数输入是多个值,输出是一个值。
UDAF是需要hive sql语句和group by联合使用的。
聚合函数常常需要对大量数组进行操作,所以在编写程序时,一定要注意内存溢出问题。
UDAF分为两种:简单UDAF和通用UDAF。简单UDAF写起来比较简单,但是因为使用了JAVA的反射机制导致性能有所损失,另外有些特性不能使用,如可变参数列表,通用UDAF可以使用所有功能,但是写起来比较复杂。
(1) 简单UDAF实例
package com.autohome.ics.bigdata.common.number;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import java.util.regex.Pattern;
/**
* Created by 鸣宇淳 on 2016/8/30.
*对传入的字符串列表,按照数字大小进行排序后,找出最大的值
*/
public class MaxIntWithString extends UDAF {
public static class MaxIntWithStringUDAFEvaluator implements UDAFEvaluator{
//最终结果最大的值
private IntWritable MaxResult;
@Override
public void init() {
MaxResult=null;
}
//每次对一个新值进行聚集计算都会调用iterate方法
//这里将String转换为int后,进行比较大小
public boolean iterate(Text value)
{
if(value==null)
return false;
if(!isInteger(value.toString()))
{
return false;
}
int number=Integer.parseInt(value.toString());
if(MaxResult==null)
MaxResult=new IntWritable(number);
else
MaxResult.set(Math.max(MaxResult.get(), number));
return true;
}
//Hive需要部分聚集结果的时候会调用该方法
//会返回一个封装了聚集计算当前状态的对象
public IntWritable terminatePartial()
{
return MaxResult;
}
//合并两个部分聚集值会调用这个方法
public boolean merge(Text other)
{
return iterate(other);
}
//Hive需要最终聚集结果时候会调用该方法
public IntWritable terminate()
{
return MaxResult;
}
private static boolean isInteger(String str) {
Pattern pattern = Pattern.compile("^[-\\+]?[\\d]*$");
return pattern.matcher(str).matches();
}
}
}UDAF要继承于UDAF父类org.apache.hadoop.hive.ql.exec.UDAF。
内部类要实现org.apache.hadoop.hive.ql.exec.UDAFEvaluator接口。
MaxIntWithStringUDAFEvaluator类里需要实现init、iterate、terminatePartial、merge、terminate这几个函数,是必不可少的.
init()方法用来进行全局初始化的。
iterate()中实现比较逻辑。
terminatePartial是Hive部分聚集时调用的,类似于MapReduce里的Combiner,这里能保证能得到各个部分的最大值。
merge是多个部分合并时调用的,得到了参与合并的最大值。
terminate是最终Reduce合并时调用的,得到最大值。
这里参考了:
http://computerdragon.blog.51cto.com/6235984/1288567
http://blog.csdn.net/xch_w/article/details/16886179
(2) 通用UDAF实例
开发通用UDAF有两个步骤,第一个是编写resolver类,第二个是编写evaluator类。resolver负责类型检查,操作符重载。evaluator真正实现UDAF的逻辑。通常来说,顶层UDAF类继承org.apache.hadoop.hive.ql.udf.GenericUDAFResolver2,里面编写嵌套类evaluator 实现UDAF的逻辑。
通用UDAF使用场景较少,详情可以参看内置函数的源码,或者官方文档。
UDTF自定义表生成函数(一进多出)
UDTF是将一个输入值转变为一个数组。
下面这个例子是从nginx日志中的agent信息中提取浏览器名称和版本号的自定义函数,输入参数类似于:
”Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML like Gecko) Chrome/31.0.1650.63 Safari/537.36”,输出为:Chrome 31.0.1650.63。
package com.autohome.ics.bigdata.common.String;
import cz.mallat.uasparser.OnlineUpdater;
import cz.mallat.uasparser.UASparser;
import cz.mallat.uasparser.UserAgentInfo;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.*;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* 解析浏览器信息UDTF
*
* 将日志中的http_user_agent,得到 browser_name,browser_version两个字段
* Created by ad on 2016/7/29.
*/
public class ParseUserAgentUDTF extends GenericUDTF{
private static UASparser uaSparser;
static{
try {
uaSparser = new UASparser(OnlineUpdater.getVendoredInputStream());
} catch (IOException e) {
e.printStackTrace();
}
}
private final ListObjectInspector listIO = null;
private final Object[] forwardObj = new Object[2];
/**
* 声明解析出来的字段名称和类型
* @param argOIs
* @return
* @throws UDFArgumentException
*/
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
if(argOIs.getAllStructFieldRefs().size() != 1){
throw new UDFArgumentException("args error!");
}
ArrayList fieldNames = new ArrayList();
ArrayList fieldOIs = new ArrayList<>();
fieldNames.add("browser_name");
fieldNames.add("browser_version");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
// 真正解析的地方
/*
输入字符串:"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36"
解析为:
*/
String userAgent = args[0].toString();
try {
UserAgentInfo userAgentInfo = uaSparser.parse(userAgent);
List bws = new ArrayList<>();
bws.add(userAgentInfo.getUaFamily());
bws.add(userAgentInfo.getBrowserVersionInfo());
super.forward(bws.toArray(new String[0]));
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void close() throws HiveException {
}
} 自定义函数使用方式:
打包为jar包(例如包名为:common.jar),因为这个程序引用了依赖uasparser,所以打包时注意应该将依赖uasparser打进去。
hive中添加jar包
add jar lib/common.jar;
声明函数
create temporary function ParseUserAgent as ‘com.autohome.ics.bigdata.common.String.
ParseUserAgentUDTF’;查询
select ParseUserAgent(agent) from user_action_log_like;结果
Chrome 31.0.1650.63
Chrome 31.0.1650.63
Chrome 31.0.1650.63
Chrome 31.0.1650.63
Chrome 31.0.1650.63
参考:cwiki.apache.org
这一篇博文是【大数据技术●降龙十八掌】系列文章的其中一篇,点击查看目录:![]() 大数据技术●降龙十八掌
大数据技术●降龙十八掌