DCGAN及其TensorFlow源码
上一节我们提到G和D由多层感知机定义。深度学习中对图像处理应用最好的模型是CNN,那么如何把CNN与GAN结合?DCGAN是这方面最好的尝试之一。源码:https://github.com/Newmu/dcgan_code 。DCGAN论文作者用theano实现的,他还放上了其他人实现的版本,本文主要讨论tensorflow版本。
TensorFlow版本的源码:https://github.com/carpedm20/DCGAN-tensorflow
DCGAN把上述的G和D换成了两个卷积神经网络(CNN)。但不是直接换就可以了,DCGAN对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度,这些改变有:
- 取消所有pooling层。G网络中使用转置卷积(transposed convolutional layer)进行上采样,D网络中用加入strided的卷积代替pooling。
- 在D和G中均使用batch normalization
- 去掉FC层,使网络变为全卷积网络
- G网络中使用ReLU作为激活函数,最后一层使用tanh
- D网络中使用LeakyReLU作为激活函数
这些改变在代码中都可以看到。DCGAN论文中提到对CNN结构有三点重要的改变:
- Allconvolutional net (Springenberg et al., 2014) 全卷积网络
判别模型D:使用带步长的卷积(strided convolutions)取代了的空间池化(spatial pooling),容许网络学习自己的空间下采样(spatial downsampling)。
Ÿ 生成模型G:使用微步幅卷积(fractional strided),容许它学习自己的空间上采样(spatial upsampling) - 在卷积特征之上消除全连接层。
Ÿ (Mordvintsev et al.)提出的全局平均池化有助于模型的稳定性,但损害收敛速度。
GAN的第一层输入:服从均匀分布的噪声向量Z,因为只有矩阵乘法,因此可以被叫做全连接层,但结果会被reshape成4维张量,作为卷积栈的开始。
对于D,最后的卷积层被flatten(把矩阵变成向量),然后使用sigmoid函数处理输出。
生成模型:输出层用Tanh函数,其它层用ReLU激活函数。
判别模型:所有层使用LeakyReLU - Batch Normalization 批标准化。
解决因糟糕的初始化引起的训练问题,使得梯度能传播更深层次。稳定学习,通过归一化输入的单元,使它们平均值为0,具有单位方差。
批标准化证明了生成模型初始化的重要性,避免生成模型崩溃:生成的所有样本都在一个点上(样本相同),这是训练GANs经常遇到的失败现象。
generator:100维的均匀分布Z投影到小的空间范围卷积表示,产生许多特征图。一系列四步卷积将这个表示转换为64x64像素的图像。不用到完全连接或者池化层。
配置
Python
TensorFlow
SciPy
pillow
(可选)moviepy (https://github.com/Zulko/moviepy):用于可视化
(可选)Align&Cropped Images.zip (http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html):人脸数据集
main.py
入口程序,事先定义所需参数的值。
执行程序:
训练一个模型:
$ python main.py --dataset mnist --is_trainTrue
$ python main.py --dataset celebA --is_trainTrue --is_crop True
测试一个已存在模型:
$ python main.py --dataset mnist
$ python main.py --dataset celebA --is_crop True
你也可以使用自己的dataset:
$ mkdir data/DATASET_NAME
添加图片到data/DATASET_NAME …
$ python main.py --dataset DATASET_NAME--is_train True
$ python main.py --dataset DATASET_NAME
训练出多张以假乱真的图片
源码分析
flags配置network的参数,在命令行中可以修改,比如
$python main.py --image_size 96 --output_size 48 --dataset anime --is_crop True--is_train True --epoch 300
该套代码参数主要以mnist数据集为模板,如果要训练别的数据集,可以适当修改一些参数。mnist数据集可以通过download.py下载。
首先初始化model.py中的DCGAN,然后看是否需要训练(is_train)。
FLAGS参数
epoch :训练回合,默认为25
learning_rate : Adam 的学习率,默认为0.0002
beta1 :Adam的动量项(Momentum term of Adam),默认为0.5
train_size :训练图像的个数,默认为np.inf
batch_size :批图像的个数,默认为64。 后面生成的图片拼在一张图,因此batch_size最好取平方,比如64,36等
input_height :所使用的图像的图像高度(将会被 center cropped ),默认为108
input_width :所使用的图像的图像宽度(将会被 center cropped ),如果没有特别指定默认和input_height一样
output_height :所产生的图像的图像高度(将会被 center cropped ),默认为64
output_width :所产生的图像的图像宽度(将会被 center cropped ),如果没有特别指定默认和output_height一样
dataset :所用数据集的名称,在文件夹data里面,可以选择celebA,mnist,lsun。也可以自己下载图片,把文件夹放到data文件夹里面。
input_fname_pattern :输入的图片类型,默认为*.jpg
checkpoint_dir :存放checkpoint的目录名,默认为 checkpoint
sample_dir :存放生成图片的目录名,默认为samples
train :训练为True,测试为False,默认为False
crop :训练为True,测试为False,默认为False
visualize :可视化为True,不可视化为False,默认为False
model.py
初始化参数
model.py定义了DCGAN类,包括9个函数
__init__()
参数初始化,已讲过的input_height, input_width, crop, batch_size, output_height, output_width, dataset_name, input_fname_pattern, checkpoint_dir, sample_dir就不再说了
sample_num :大小和batch_size一样
y_dim :输出通道。 训练mnist数据集时,y_dim=10 ,我想可能是因为mnist是图片数字,分为10类。如果不是mnist,则默认为none。
z_dim :噪声z的维度,默认为100
gf_dim : G第一个卷积层的过滤器个数 ,默认为64
df_dim : D第一个卷积层的过滤器个数 ,默认为64
gfc_dim : G第一个全连接层的G单元个数 ,默认为1024
dfc_dim : D第一个全连接层的D单元个数 ,默认为1024
c_dim :颜色通道,灰度图像设为1,彩色图像设为3,默认为3
其中self.d_bn1, self.d_bn2, g_bn0, g_bn1, g_bn2是batch标准化,见ops.py的batch_norm(object)。
如果是mnist数据集,d_bn3, g_bn3都要batch_norm。
self.data读取数据集。
然后建立模型(build_model)
build_model()
inputs的形状为[batch_size, input_height, input_width, c_dim]。
如果crop=True,inputs的形状为[batch_size, output_height, output_width, c_dim]。
输入分为样本输入inputs和抽样输入sample_inputs。
噪声z的形状为[None, z_dim],第一个None是batch的大小。
然后取数据:
self.G = self.generator(self.z)#返回[batch_size, output_height, output_width, c_dim]形状的张量,也就是batch_size张图
self.D, self.D_logits = self.discriminator(inputs)#返回的D为是否是真样本的sigmoid概率,D_logits是未经sigmoid处理
self.sampler = self.sampler(self.z)#相当于测试,经过G网络模型,取样,代码和G很像,没有G训练的过程。
self.D_, self.D_logits_ = self.discriminator(self.G, reuse=True)
#D是真实数据,D_是假数据
用交叉熵计算损失,共有:d_loss_real、d_loss_fake、g_loss
self.d_loss_real = tf.reduce_mean(
sigmoid_cross_entropy_with_logits(self.D_logits, tf.ones_like(self.D)))
self.d_loss_fake = tf.reduce_mean(
sigmoid_cross_entropy_with_logits(self.D_logits_, tf.zeros_like(self.D_)))
self.g_loss = tf.reduce_mean(
sigmoid_cross_entropy_with_logits(self.D_logits_, tf.ones_like(self.D_)))
tf.ones_like:新建一个与给定tensor大小一致的tensor,其全部元素为1
d_loss_real是真样本输入的损失,要让D_logits接近于1,也就是D识别出真样本为真的
d_loss_fake是假样本输入的损失,要让D_logits_接近于0,D识别出假样本为假
d_loss = d_loss_real + d_loss_fake是D的目标,要最小化这个损失
g_loss:要让D识别假样本为真样本,G的目标是降低这个损失,D是提高这个损失
summary这几步是关于可视化,就不管了
train()
通过Adam优化器最小化d_loss和g_loss。
sample_z为从-1到1均匀分布的数,大小为[sample_num, z_dim]
从路径中读取原始样本sample,大小为[sample_num, output_height, output_width, c_dim]
接下来进行epoch个训练:
将data总数分为batch_idxs次训练,每次训练batch_size个样本。产生的样本为batch_images。
batch_z为训练的噪声,大小为[batch_num, z_dim]
d_optim = tf.train.AdamOptimizer(config.learning_rate, beta1=config.beta1) \
.minimize(self.d_loss, var_list=self.d_vars)
g_optim = tf.train.AdamOptimizer(config.learning_rate, beta1=config.beta1) \
.minimize(self.g_loss, var_list=self.g_vars)
首先输入噪声z和batch_images,通过优化d_optim更新D网络。
然后输入噪声z,优化g_optim来更新G网络。G网络更新两次,以免d_loss为0。这点不同于paper。
这样的训练,每过100个可以生成图片看看效果。
if np.mod(counter, 100) == 1
discriminator()
代码自定义了一个conv2d,对tf.nn.conv2d稍加修改了。下面贴出 tf.nn.conv2d 解释如下:
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)
除去name参数用以指定该操作的name,与方法有关的一共五个参数:
第一个参数input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一
第二个参数filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维
第三个参数strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4
第四个参数padding:string类型的量,只能是”SAME”,”VALID”其中之一,这个值决定了不同的卷积方式(后面会介绍)
第五个参数:use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true
结果返回一个Tensor,这个输出,就是我们常说的feature map
batch_norm(object)
tf.contrib.layers.batch_norm的代码见https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/layers/python/layers/layers.py
batchnormalization来自于http://arxiv.org/abs/1502.03167
加快训练。
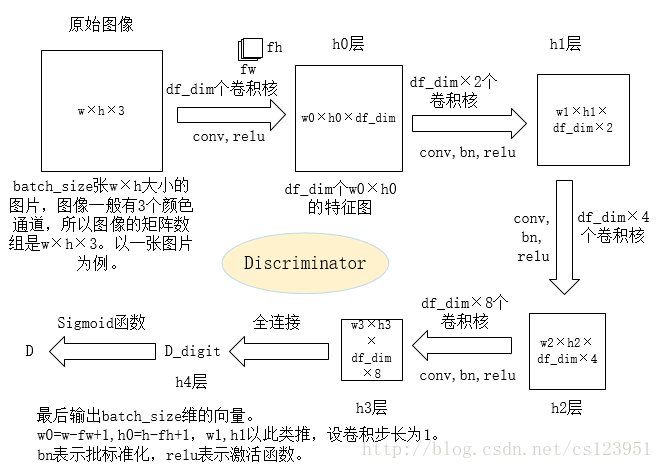
激活函数lrelu见ops.py。四次卷积(其中三次卷积之前先批标准化)和激活之后。然后线性化,返回sigmoid函数处理后的结果。h3到h4的全连接相当于线性化,用一个矩阵将h3和h4连接起来,使h4是一个batch_size维的向量。
generator()
self.h0 = tf.reshape(self.z_, [-1, s_h16, s_w16, self.gf_dim * 8])改变z_的形状。-1代表的含义是不用我们自己指定这一维的大小,函数会自动计算,但列表中只能存在一个-1。(当然如果存在多个-1,就是一个存在多解的方程了)
deconv2d()
引用tf的反卷积函数tf.nn.conv2d_transpose或tf.nn.deconv2d。以tf.nn.conv2d_transpose为例。
defconv2d_transpose(value, filter, output_shape, strides,padding=”SAME”, data_format=”NHWC”, name=None):
- value: 是一个4维的tensor,格式为[batch, height, width, in_channels] 或者 [batch, in_channels,height, width]。
- filter: 是一个4维的tensor,格式为[height, width, output_channels, in_channels],过滤器的in_ channels的维度要和这个匹配。
- output_shape: 一维tensor,表示反卷积操作的输出shapeA
- strides: 针对每个输入的tensor维度,滑动窗口的步长。
- padding: “VALID”或者”SAME”,padding算法
- data_format: “NHWC”或者”NCHW” ,对应value的数据格式。
- name: 可选,返回的tensor名。
deconv= tf.nn.conv2d_transpose(input_, w, output_shape=output_shape,strides=[1,d_h, d_w, 1])
第一个参数是输入,即上一层的结果,
第二个参数是输出输出的特征图维数,是个4维的参数,
第三个参数卷积核的移动步长,[1, d_h, d_w, 1],其中第一个对应一次跳过batch中的多少图片,第二个d_h对应一次跳过图片中多少行,第三个d_w对应一次跳过图片中多少列,第四个对应一次跳过图像的多少个通道。这里直接设置为[1,2,2,1]。即每次反卷积后,图像的滑动步长为2,特征图会扩大缩小为原来2*2=4倍。
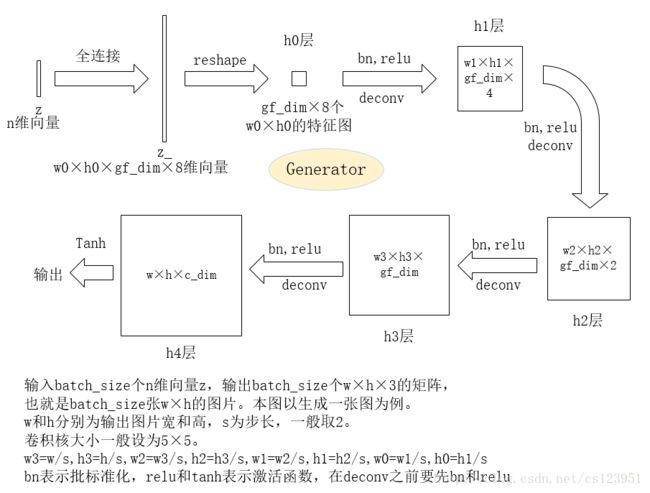
sampler()
和generator结构一样,用的也是它的参数。存在的意义可能在于共享参数?
将self.sampler = self.sampler(self.z, self.y)改为self.sampler = self.generator(self.z, self.y)
报错:

所以sampler的存在还是有意义的。
load_mnist(), save(), load()
这三个加载保存等就不仔细讲了。
download.py和ops.py好像也没什么好讲的。
utils.py包含可视化等函数
参考:
Springenberg, Jost Tobias, Dosovitskiy, Alexey, Brox, Thomas, and Riedmiller, Martin. Striving for simplicity: The all convolutional net. arXiv preprint arXiv:1412.6806, 2014.
Mordvintsev, Alexander, Olah, Christopher, and Tyka, Mike. Inceptionism : Going deeper into neural networks.http://googleresearch.blogspot.com/2015/06/inceptionism-going-deeper-into-neural.html. Accessed: 2015-06-17.
Radford A, Metz L, Chintala S. UnsupervisedRepresentation Learning with Deep Convolutional Generative AdversarialNetworks[J]. Computer Science, 2015.
http://blog.csdn.net/nongfu_spring/article/details/54342861
http://blog.csdn.net/solomon1558/article/details/52573596