google的tensor2tensor的学习和使用
前言
- tensor2tensor(t2t)是google基于tensorflow新开源的深度学习库,该库将深度学习所需要的元素(数据集、模型、学习率、超参数等)封装成标准化的统一接口,在使用其做模型训练时可以更加的灵活。
当前环境
- mac 10.13.3
- tensorflow 1.6.0
- tensor2tensor 1.5.5
安装模块
- 源码下载:https://github.com/tensorflow/tensor2tensor
- sudo pip install tensorflow==1.6.0
- sudo pip install tensor2tensor==1.5.5
开启学习之旅
在下载的源码中有自带的一些简单的测试样例。如mnist,,可以参考https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/notebooks/hello_t2t.ipynb
来做初步的了解。
同时t2t支持自定义的样本数据和自定义的参数配置,下面以我自定义了一个训练样本开始介绍。
已将下述的代码上传:https://download.csdn.net/download/csa121/10672326
根据下述的介绍也可以自己搭建一个环境的。
0.目录结构
因为有需要注意的点,先看下我自定义样本的目录结构:
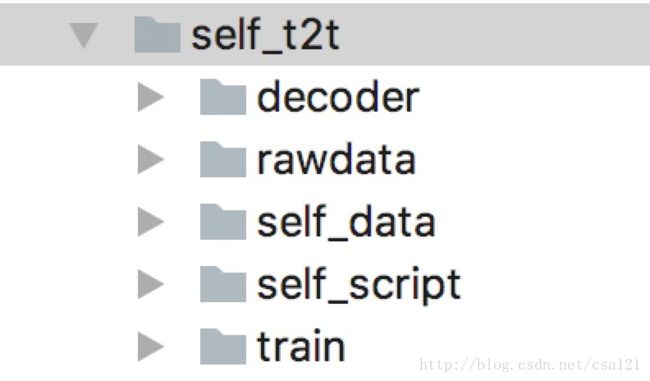
decoder:预测要用到的目录
rawdata:原始样本存放的目录
self_data:原始样本格式化后存放的目录
self_script:自定义problem脚本存放的目录
train:训练出来的模型和导出的模型存放的目录
注:只是为了后续介绍的更清楚才说明的目录结构,不是t2t要求的目录结构。
1.需求
训练一些评论和标签样本,生成一个模型,可以给新的评论打一个标签
2.样本
评论样本 rawdata/q.txt:
内容很多很棒
好老师!有耐心!培养孩子兴趣!赞一个
课程很精彩,老师会结合自身作为案例进行分享
老师很幽默
老师的能力值得肯定
喜欢上老师的数学课
老师上课气氛特别好
每次听完老师的课都觉得让自己又丰富了许多
挺善于沟通的,比较容易接受
观点很新颖,谢谢老师
标签样本 rawdata/a.txt
授课熟练
态度认真负责
授课熟练
幽默风趣
性价比高
幽默风趣
上课气氛活跃
内容新颖有用
性价比高
内容新颖有用
3.编写自定义的problem
self_script/my_problem.py
# coding=utf-8
from tensor2tensor.utils import registry
from tensor2tensor.data_generators import problem, text_problems
#自定义的problem一定要加该装饰器,不然t2t库找不到自定义的problem
@registry.register_problem
class MyProblem(text_problems.Text2TextProblem):
@property
def approx_vocab_size(self):
return 2**11
@property
def is_generate_per_split(self):
return False
@property
def dataset_splits(self):
return [{
"split": problem.DatasetSplit.TRAIN,
"shards": 9,
}, {
"split": problem.DatasetSplit.EVAL,
"shards": 1,
}]
def generate_samples(self, data_dir, tmp_dir, dataset_split):
del data_dir
del tmp_dir
del dataset_split
#读取原始的训练样本数据
q_r = open("./rawdata/q.txt", "r")
a_r = open("./rawdata/a.txt", "r")
comment_list = q_r.readlines()
tag_list = a_r.readlines()
q_r.close()
a_r.close()
for comment, tag in zip(comment_list, tag_list):
comment = comment.strip()
tag = tag.strip()
yield {
"inputs": comment,
"targets": tag
}
self_script/init.py
from . import my_problem
需要注意的点:
(1)一定要在__init__.py文件中引入模块,否则t2t的命令找不到自定义的problem;
(2)自定义的problem文件名一定要和脚本中的class名保持一致,如:文件名是my_problem,类名需要是MyProblem,否则t2t的命令找不到自定义的problem。希望后续的版本不会有这个问题吧。
4.格式化样本
要将原始的样本数据转换成t2t自己的数据集格式(TFRecord),使用t2t-datagen命令执行:
t2t-datagen --t2t_usr_dir=self_script --problem=my_problem --data_dir=./self_data
格式化的数据会在self_data目录下生成一些文件如下:
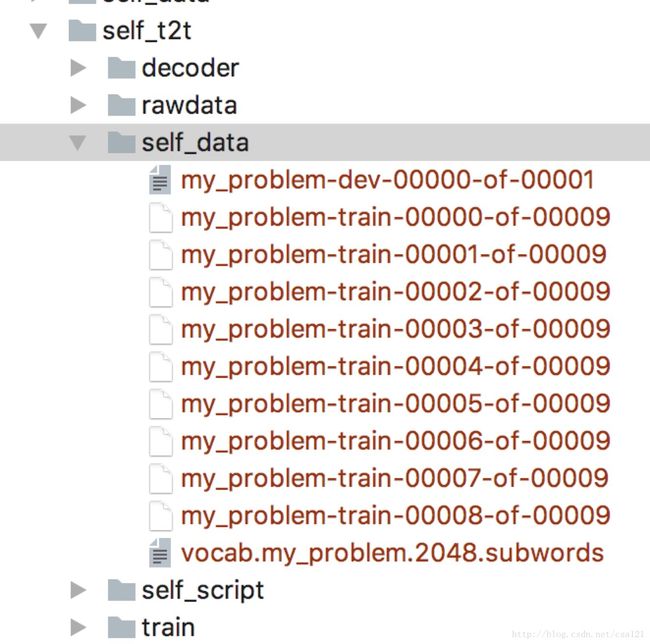
后续我们的训练就是读这些文件。
5.训练
使用t2t-trainer命令对格式化样本进行训练:
t2t-trainer --t2t_usr_dir=self_script --problem=my_problem --data_dir=./self_data --model=lstm_seq2seq_attention --hparams_set=lstm_attention --output_dir=./train
我们使用的模型是lstm_seq2seq_attention模型,使用的超参数集是lstm_attention。因为还在学习阶段,就没有特地去选择模型。
需要注意的点:
(1)如果在训练过程中有如下报错:
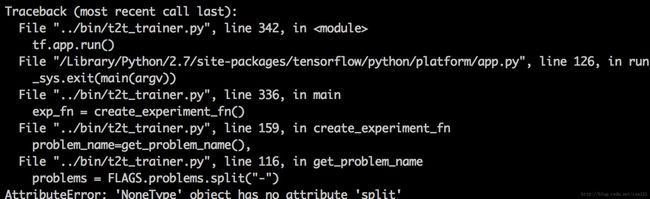
说明当前tensor2tensor和tensorflow的版本兼容有问题,需要更换两者的版本,经过查阅tensor2tensor在github的代码提交和其他信息,试验出来tensor2tensor1.5.3和tensorflow1.4.1这两个版本组合是没有问题的。有报错的可以把两者版本降低一下。
(2)在训练过程中我没有指定训练的次数和打印准确率的步数,t2t默认是训练1000次打印一次准确率。如果感觉准确率符合预期的话,可以直接kill掉训练任务。t2t会自动保存最新的训练模型。
6.预测
使用t2t-decoder命令对训练好的样本进行预测
先看下预测的样本:
decoder/q.txt
老师很幽默
非常好 讲的很详细 很幽默哈哈哈
第一次听!讲得还挺清楚,只是不清楚后面怎么安排呢
预测是命令:
t2t-decoder --t2t_usr_dir=self_script --problem=my_problem --data_dir=./self_data --model=lstm_seq2seq_attention --hparams_set=lstm_attention --output_dir=./train --decode_hparams="beam_size=4,alpha=0.6" --decode_from_file=decoder/q.txt --decode_to_file=decoder/a.txt
可以在你指定的decode_to_file文件下看到预测的结果是否符合预期
7.导出模型
t2t-exporter --t2t_usr_dir=self_script --problems=my_problem --data_dir=./self_data --model=lstm_seq2seq_attention --hparams_set=lstm_attention --output_dir=./train
需要注意的点:
(1)github中t2t的源码中有提到导出功能只支持tensorflow 1.5+,所以如果在训练过程中有降低了tensorflow版本的操作,还需要把版本升到1.5+;
(2)注意导出命令中的problems=my_problem参数,前面训练时使用的是problem=my_problem,导出时需要加problem参数名要加s。不知道t2t中为什么会存在这种不兼容的情况,希望后续会修复这个参数的问题吧。
8.搭建一个常驻内存的预测服务
搭建服务时请确保mac上安装了brew,没有安装的请先自行安装brew。后续步骤如下:
(1)安装tensorflow-serving-api
sudo pip install tensorflow-serving-api
(2)安装Bazel
bazel是google的一个编译工具,类似于Make。我们需要使用它对源码进行编译出一个tensorflow_model_server二进制文件。执行:brew install bazel
(3)下载serving源码
我们需要使用bazel对源码进行编译,所以需要先下载该源码:
git clone --recurse-submodules https://github.com/tensorflow/serving
(4)创建tensorflow_serving
cd serving
bazel build tensorflow_serving/
(5)编译出一个用来启动服务的tensorflow_model_server的二进制文件
bazel build -c opt //tensorflow_serving/model_servers:tensorflow_model_server
注:时间比较长,编译大概用了一个多小时吧
(6)配置命令
将tensorflow_model_server命令起个别名指定到目录,这样就不用在特定的目录下执行启动服务的操作了
vim ~/.bashrc
alias tensorflow_model_server='~/serving/bazel-bin/tensorflow_serving/model_servers/tensorflow_model_server'
source ~/.bashrc
(7)启动server
tensorflow_model_server --port=9000 --model_name=lstm_seq2seq_attention --model_base_path=~/self_t2t/train/export/Servo
经过以上的步骤,就可以启动一个常驻内存的预测服务了。
9.客户端发请求预测
t2t-query-server --server=127.0.0.1:9000 --servable_name=lstm_seq2seq_attention --t2t_usr_dir=self_script --problem=my_problem --data_dir=./self_data
后记
-
经过上述的所有操作,对t2t的使用上有了一个初步的了解,在后续的使用中可以根据各自不同的业务场景自定义不同的problem、更换model和hparams。
-
在使用的过程中,发现目前t2t和tf的版本间兼容性还不是很好,相信后续应该会更完善吧。
-
虽然t2t将现有的一些主流模型做了封装,我们可以不用关注模型的生成,但是我们也有必要多了解其背后的实现原理。