【CSDN编者按】以人为鉴,可明得失。对于新手程序员来说,面对复杂的开发需求很容易因为经验不足或技术不够娴熟等原因而踩坑。本文的作者表示:坐在高级软件工程师旁边工作或许可以事半功倍!长达一年的观察学习,他收获了包括编写代码、测试、设计、部署以及监控的一系列的长足进步。
声明:本文已获作者翻译授权,原文(https://neilkakkar.com/things-I-learnt-from-a-senior-dev.html)。
作者 | Neil Kakkar
译者 | 王艳妮,责编 | 郭芮
出品 | CSDN(ID:CSDNnews)
以下为译文:
一年前,我开始了在彭博社的全职工作,我那时就想象着要写这篇文章了。我想象着自己脑中会充满各种各样的想法,在时机成熟时可以将其诉诸笔端。仅仅一个月以后,我就意识到了这件事并不容易:我总是在慢慢忘记我已经学到的东西——它们要么被完全内化,以至于我的大脑让我以为我本来就知道这些,要么就被我渐渐淡忘了。
这是我开始写“日志”的原因之一。每天,当我遇到有趣的情况时,我都会记录下来。我很幸运地能坐在一位高级软件工程师旁边,这样我可以仔细观察他在做什么,以及这与我的做法有何不同。我们经常组队编程,这使得观察他更容易了。此外,在我的团队文化中,在别人写代码的时候站在后面看并不是什么不好的事情。每当我感觉到有趣的事情正在发生时,我就会转过去看看。由于经常凑过去看,我总是知道事情发生的前因后果。
我有一年的时间都坐在这位高级软件工程师旁边工作,以下是我学到的一些东西。
写代码
如何命名
我接手的第一样东西就是React UI。我们有一个主要组件,它容纳了其他所有组件。我喜欢在代码中加入一点幽默感,我想把它命名为GodComponent。在code review的时候,我才明白为什么命名是一件很难的事情。
计算机科学有两个难点:
缓存失效,给变量命名,以及差一错误。
——Leon Bambrick
我经手的每一段代码都带有隐喻意。GodComponent?那是用来盛放所有那些我不知道该放到哪里的的烂代码的,它包罗万象。如果我将一个变量命名为LayoutComponent,未来我看到的时候就会知道,它所做的只是规划布局,而不涉及任何状态。
我发现的另一个好处是:如果它看起来太大了,就像包含大量业务逻辑的LayoutComponent一样,我就知道是时候重构了,因为业务逻辑不应当属于那部分。而如果使用GodComponent这个名称,那对里面的业务逻辑就不会产生任何影响。
命名你的集群?根据在它上面运行服务来命名是个好主意,可是你以后还可能会在上面运行其他东西。最终,我们是用团队名称来命名的。
对于函数来说也是一样。doEverything()是一个可怕的名字,这会产生很多后果。如果这个函数可以完成所有操作,那么测试这个函数的特定部分就会变得特别难。无论这个函数有多大,你都不会觉得奇怪,因为毕竟这个函数就是要做所有事情的。所以需要换个函数名,重构。
有意义的命名也有不好的一面。如果名称太有意义并隐藏一些歧义怎么办?例如,在SQLAlchemy中调用session.close()时,closing sessions不会关闭基础数据库连接。
在这种情况下,将名称视为x,y,z而不是count(),close(),insertIntoDB()可以防止赋予它们隐含意义——并迫使我仔细检查它们正在做什么。
从来没想到,关于命名我要说的东西居然不能用一句话就概括完。
旧代码和下一个开发者
你有没有看过一些代码并觉得很奇怪?那些开发者为什么这样做?这完全说不通啊。
我曾经有幸使用过遗留代码库。其中有类似这样的注释,“在与穆罕默德一起解决了这个问题以后,注释就删掉了。”你在做什么?谁是穆罕默德?
我可以在这里做一个角色转换——想想以后来接手我代码的人们——他们会不会发现它很奇怪。Peer review 部分解决了这个问题,这让我意识到了环境的重要性:要时刻记得我的团队正在工作的环境是什么样的。
如果我忘记了代码,稍后又看到它,而无法重新回想起当时的环境时,我会说:“到底为什么他们会这样做?这讲不通......哦等等,这是我自己写的。”
这就是文档和代码注释发挥作用的地方了。
文档和代码注释
它们有助于保留环境(上下文,语境),以及分享知识。
正如Li在“如何建立良好的软件”中所说的那样,“软件的主要价值不在于生成的代码,而在于产生它的人所积累的知识。”
“软件的主要价值不在于产生的代码,而在于产生它的人所积累的知识。”——Li
我们有一个面向客户的API终端,似乎没有人使用过。那么我们就要删除它吗?毕竟,这是技术负债。
如果我告诉你,每年在特定国家/地区,10名记者会将他们的报告发送到该终端,该怎么办?你要如何测试?如果没有文档(现实中确实没有),我们就没办法。但是没有办法,我们还是直接删除了该端点。几个月以后那个一年一度的时刻到了,十名记者根本无法发送10份重要报告,因为终端不再存在了,
拥有关于这个产品的知识的人也都已经离开了团队。
当然,现在代
码中有一些注释解释了端点的用途。
据我所知,文档是一个每个团队都在努力解决的问题,我就很喜欢Antirez对不同类型的有价值的代码注释的详细分类。。不仅仅是代码文档,还有代码周围的流程。但目前,
我们还没有找到一个完美的解决方案。
原子性提交
如果你必须回到之前的步骤(是的你会的,详见测试部分),这个提交作为一个单元是否合适?
在删除烂代码的时候有自信
删除烂代码或过时的代码会使我感到非常不舒服,我认为多年之前被写下的代码是神圣的。我的想法是“当他们写下这些东西时,他们肯定是考虑到一些事情的。”这是传统和文化与第一原则思维方式之间的较量。删除一年一次的终端也是如此,我在这方面得到了太多具体的教训。
我会试着从周围解决代码,而高级工程师则会试着从中间解决。删除所有内容:一个永远不会运行的if语句,一个不应该调用的函数——是的,一切都被删了。我?我只会在最上面写下我自己的函数而已,技术债务一点都没有减少。如果我做了什么的话,我也只是增加了代码复杂性和给他人的误导而已,对下一个人来说把这些代码功能拼凑到一起会更艰难。
我现在使用的启发是:现有的代码你无法理解,而且你知道有些代码是你永远也不会用到的。那么最好删除那些你永远不会用到的代码,并对那些你不理解的代码保持谨慎的态度。
Code Reviews
Code review是非常棒的学习途径。这是一个外部反馈循环,反映了你现在和将来会怎么写代码。两者的差别在哪里?有一种方式比另一种更好吗?我在每次code review时都会问自己这个问题:“为什么他们那样做?”。每当我找不到合适的答案时,我都会和他们谈谈。
在第一个月之后,我开始在我的队友代码中发现一些错误(就像他们曾经为我做的那样)。这太疯狂了,同行地评论对我来说变得更加有趣了——变成了我期待的一场游戏——一场改善我的代码感的游戏。
我的启发是:在我了解代码如何工作之前不要批准代码。
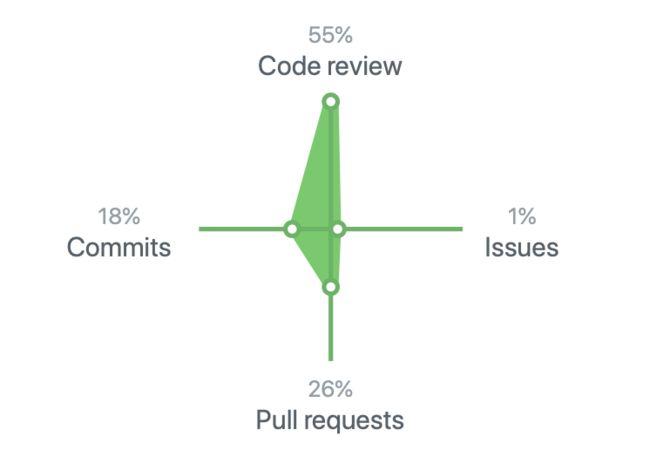
我的Github数据
测试
我非常喜欢测试,以至于如果没有测试,在代码库中写代码会使我感到很不舒服。
如果你的整个应用程序只做一件事(就像我所有的课设一样),那么手动测试仍然可行,我以前就是这么做的。但是当应用程序能做100种不同的事情时会发生什么?我不想花整整半小时来逐项测试,而且有时我会遗忘真正需要测试的那一个东西——那样的话简直是一场噩梦!
这时测试和测试自动化登场了。
我把测试当做是文档。测试告诉我,我(或我之前的人)如何期望代码来工作,以及他们认为事情会出错的地方。
所以,当我现在编写测试时,我会记住这一点:
演示如何使用我正在测试的类/函数/系统;
展示出所有我认为可能会出错的内容。
上述的一个必然结果是,在大多数情况下,我测试的是行为而不是实现。
因此,每当我发现一个bug时,我都会确保代码修复程序有相应的测试(称为回归测试)来记录信息:这是另一种可能出错的方法。
但是,仅仅编写这些测试并不能提高代码质量,仍需要实际编写代码,但是我从阅读测试中获得的见解能帮助我写更好的代码。
那么接下来就是部署环境登场的地方。
你可能有完美的单元测试,但如果没有进行系统测试,则会发生以下情况:
这锁好使(吗?)
对于经过良好测试的代码也是如此:如果你的机器上没有所需的库,则会崩溃。
首先是你用来开发的机器(所有“它在我的机器上能正常工作!”这类meme(梗)的来源);
其次是你用来测试的机器(可能与你用来开发的机器相同);
最后,有你用来部署的机器(请不要让它与你用来开发的机器相同)。
如果测试和部署机器之间的环境不匹配,你就麻烦了。
我们的机器上有本地开发,它位于Docker中。
我们还有一个开发环境,其中机器安装了一组库(和开发工具),我们在上面安装在这些库上编写的代码,
其他依赖系统的所有测试都可以在这里进行。
然后是beta / stage环境,它与生产环境完全一样。
最后,生产环境,它们是运行代码并为实际客户提供服务的机器,
目的是尝试捕获单元和系统测试发现不了的bug。
例如,请求和响应系统之间的API不匹配。
我想个人项目或小公司的情况会有很大不同,并非每个人都有资源来部署自己的基础设施。但是,这个想法对于AWS和Azure等云提供商的服务也适用。
你可以为开发和生产设置单独的集群。AWS ECS使用Docker镜像进行部署,因此各环境之间相对一致,棘手的一点是其他AWS服务之间的集成。你是否从正确的环境中调用了正确的端点?
你甚至可以更进一步:为其他AWS服务下载备用容器映像,并使用docker-compose设置本地完整环境,这样能加速反馈循环。
等我启动自己的业余项目以后,我可能会在这方面有更多的经验。
降低风险
(Derisking)
Derisking是一门通过你所部署的代码来降低风险的艺术。
那么
可以采取哪些措施来降低灾难发生的风险呢?
如果这是一个新的突破性变化,
当出现问题时又如何保证最小程度的损
失?
“我们不需要对所有这些新变化都进行全系统部署。”——哦,等等,真的吗?我当时怎么一点也没想到!
设计
我为什么要把设计放在写代码和测试这两项之后呢?好吧,设计可能是首要问题,但如果我还没有在现在这个环境中编码和测试过,我可能不会像现在这样擅长设计一个尊重环境特性的系统。
在设计一个系统时有很多事情值得考虑:
我需要把它转换成一份名为“收集需求”的整洁的清单。今年我这方面做的还不够多,这是我明年在公司要解决的问题。
这个过程有点违背敏捷——在开始实施之前你能设计到什么程度呢?这是一个平衡——而且你要选择什么时间做什么事情:什么时候该埋头苦干,什么时候该后退一步?
当然,收集需求并不是全部,
我认为将开发过程包含在设计中也是有好处的。
比如:
本地开发将如何运作?
我们将如何打包和部署?
我们如何进行端到端测试?
我们将如何对这项新服务进行压力测试?
我们将如何管理秘密?
CI / CD集成?
我们最近为BNEF开发了一个新的检索系统。我必须设计本地开发,了解DPKG(打包和部署),并与秘密部署搏斗。
谁能想到把秘密部署到生产中居然会那么棘手?
我们不想手动地去做事情。
最后,我们使用了具有角色访问控制的数据库(只有我们和我们的机器可以与数据库通信),我们的代码在启动时从这个数据库获取秘密。这在开发、beta和生产中都有很好的复现,各自的数据库中都有秘密。
同样,如果你用的是AWS等云提供商提供的服务,情况可能会有很大不同。你只要获取你的角色帐户,在UI中输入秘密,你的代码就会在需要时找到它们。这样简化了不少东西,挺酷的——但我很高兴自己有前面的经验可以来欣赏它的简洁性。
设计时考虑到维护
设计系统令人兴奋,而维护就不怎么样了。
我的维护经历让我想到了这个问题,系统是为何以及如何退化的?
首先是不弃用旧的、反而总是添加更多新的东西,即倾向于添加而不是删除。(让你想起某人了吗?)
其次是设计时总想着最终目标。一个不断发展着去做不是自己本应做的事情的系统,表现必然没有那些从一开始就目标明确的系统好。这是采取后退一步的方法,而不是马上上手。
我现在知道至少三种降低系统退化速度的方法。
部署
我是将功能捆绑在一起好呢,还是逐个部署好呢?
根据当前的流程,如果上面
这个问题的答案是将功能捆绑在一起,则会出现问题。所以真正
该问的应该是:为什么要将功能捆绑在一起?
部署是否需要花费太多时间?
Code review会变得更加不容易吗?
无论是出于什么原因,这都是解决问题的瓶颈所在。
关于功能捆绑,我知道至少存在两个问题:
然后,无论你选择哪种部署流程,你总是希望你的机器像牛一样,而不是像宠物一样(它们并不珍贵)。你确切知道每台机器上运行的是什么,以及如何在它坏掉的时候重新创建一个出来。当一台机器坏掉时,你不会感到沮丧,你只需要启动一台新机器——你豢养它们,而不是抚养它们。
当有地方出错时......
当出现问题时(问题必然会出现的),黄金法则就是尽量减少对客户的影响。
每当
出现问题
,我的自然反应就
是去解决问题。
事实证明,其实这并不是最优解决方案。
首先要做的是回滚,而不是修复出错的地方,即使“改一行代码就行”。最好的方法是回到之前的工作状态——这是让客户恢复工作版本的最快方式。
然后我再去看看出了什么问题,并修复这些bug
。
集群中的“borked”机器也是如此——先将其下线,标记为不可用,然后再尝试找出机器出了什么毛病。
我发现有一点很奇怪,那就是我的自然倾向和本能反应竟然与最佳解决方案大相径庭。
我认为这种本能也让我走上了解决bug的漫长道路。
有时,我觉得它不work,就是因为我写的代码出了问题,而且我会深入研究我写的每一行代码。
最后发现是配置更改导致时,也就是说,我没有事先启用该功能,这让我很生气......
我在改bug方面做得远远达不到最优。
从那时起,我的启发式方法就是在深度优先搜索之前进行广度优先搜索,以摆脱顶级节点。我可以使用当前资源确认什么?
机器开启了吗?
是否装好了正确的代码?
配置到位了吗?
<代码特定配置>,就像代码中的路由是否正确?
架构版本是否正确?
然后,进入代码部分。
我们以为是Nginx没有在机器上正确安装好,但最后发现,只是配置被设置了false。
当然,我不需要一直这样做。有时,仅仅error提示就足以将搜索空间缩减而直指到我的代码。
当我无法弄清楚这个问题的时候,我会尽量将代码的改动保持在最低限度。改动的地方越少,我就能越快地研究真正的问题,将推理跳跃保持在最低限度。
我现在还会记下那些花了我1个多小时才解决的bug:我漏掉了什么?通常是因为我忘记检查一些愚蠢的小事,比如设置路由、确保架构版本和服务版本匹配等等。这是使我对当前使用的技术栈熟悉起来的另一个步骤,不过还有一样东西只能靠经验培养——能弄清楚事情为什么不work的直觉。
战争故事
如果没有战争故事的部分,这篇文章怎么能够说是完整呢?
现在我有一个故事想分享一下:
这是个关于搜索和SQLAlchemy的传说。
在彭博社
,我们有很多分析师来撰写研究报告。
每当报告发布时,我们都会收到一条消息。
每当我们收到消息时,我们都会通过SQLAlchemy进入我们的数据库,获取我们需要的所有东西,将其转换,然后将它发送到我们的solr实例进行索引。
就在这时,奇怪的AF bug发生了。
每天早上,连接到数据库都会失败,显示error“MYSQL服务器已经消失。”有时候,下午也是如此。机器在下午转动,所以我首先检查的就是这个。不,机器转动时从未发生过错误。我们全天向数据库发出数千个请求,没有一个失败的。那么,这个非常低的负载触发怎么会失败呢?
哦,也许是因为我们没有在事务结束后关闭会话?所以,如果是相同的会话,并且下一个请求在很长一段时间后出现,我们就超时了,服务器就消失了。去看一眼代码,果然,我们在每次读取时使用上下文管理器,在__exit __()上调用session.close()。
用一整天时间来排查所有可能的故障,一无所获,第二天早上上班,机缘巧合之下找到了原因。像往常一样,那天早上也报错了,一秒后,有其他三个索引请求成功了,这符合有一个会话没有被正确关闭的所有表现。
后面的故事你已经知道了。
除非你使用的是NullPool,否则SQLAlchemy的mysql语言中的Session.close()不会关闭基础数据库连接。是的,后来就把这里修好了。
好玩的是,这个bug的发生仅仅是因为,我们没有选择在晚上或午餐时间发布研究报告。这里还有另一个教训——Stack Overflow上的大部分答案(我当然有事先Google过了!)是调整会话超时时间,或者是调整控制每个SQL语句可以发送的数据量的参数。那些回答对我来说都讲不通,因为它们与根本性的问题几乎无关。我检查过查询大小是否在限制范围内,以确保关闭会话时不会发生超时。
我们可以通过将会话超时的值增加到8小时而不是原来的1小时来“修复”此bug。这似乎也可以解决这个问题,直到遇到下一次工作日放假——第二天早上的第一份研究报告将会失败。
这是调整参数或玩弄统计数据,以及修复根本原因之间的一段曲折故事。
监控
这是我之前从未想过要做的事情。平心而论,在全职写代码之前,我从未维护过系统。我仅仅是建造它们,用了一个星期然后开始下一个项目。
通过使用两个系统,一个具有良好的监控功能,另一个则不具备,这让我懂得了监控的重要性。如果我都不知道它们的存在,我就无法修复bug。最糟糕的感受之一就是从客户那里才知道有bug出现——“我在做什么?!我连我自己的系统出了什么问题都不知道?“
我认为监控由三个组件构成——日志记录、度量和警报。
代码写的日志就像人类日志一样,是一个渐进的过程。
找出可能需要监视的内容,记录这些内容,然后运行系统。
随着时间的推移,你会发现一些bug,但你还没有充足的信息来解决它们。
这是增强日志记录的好时机——你的代码中漏掉了什么?
我认为,你自然而然地就会知道哪些东西是值得记录的。这位高级软件工程师和我的记录之间有很大不同。我认为请求—响应日志就足够了,而他有很多度量,比如查询执行时间、代码所做的一些特定内部调用、以及何时轮换日志,所有这些都已整理出来。
在没有日志的情况下进行debug几乎是不可能的——如果你连系统所处的状态都不知道,又谈何重新创建一个出来?
度量标准可以从日志中产生,也可以在代码中独立存在。(例如将事件发送到AWS CloudWatch和Grafana)。你可以自己决定度量并在代码运行时把那些数字发送出去。
在一个好的监控系统中,警报是将所有内容整合在一起的粘合剂。如果一个度量是当前参与生产的机器数量,当这个数字下降到50%时,将是一个很严重的警报——你就知道出问题了。
失败计数超过某个阈值?是的,还会有另一个警报。
由于知道如果出错了那么警报就会叫醒我,所以我在晚上能安然入睡。
这暗示了另一种需要培养的习惯。当你修复bug时,你不仅仅是专注于如何修复这个bug,而且要思考,为什么没有早点弄清楚?警报设置到位吗?如何更好地监控以防止类似问题再次出现?
到目前为止我还没弄明白如何监控用户界面,只测试组件是否到位不足以让我知道哪里出错了。通常情况下仍然是客户告诉我们的——哪里看起来有点不对劲......
结论
在过去的一年里,我学到了很多东西。我很庆幸自己刚开始工作时就决定要写这篇文章,有了这篇文章作参照,我能够更好地体会到自己成长了多少。我希望你也可以从这里得到一些启发!
我也非常幸运能够身处一支优秀的团队中——我们写代码很多,欢声笑语也很多,我们能从头开始设计系统,并与很多其他团队合作。
今年,我坐在了两为高级开发人员的旁边。那些优秀的工程师,他们自己设计的系统更健壮,更容易被他人理解。这具有乘数效应,可以使同事们在他们设计的系统上更快更可靠地开发。
所以今年会怎么样呢?让我们拭目以待吧
!
感谢团队!

下一步的方向
我还没有悟到软件工程的真谛。因此,我还有很多东西需要学习!如果我的方向正确,明年这个List应该会变得更长:
从抽象还是实现的角度思考?
我应该对如何做事有强烈意见吗?也许是因为以前吃过亏?我以前做过的工作是否为自己赢得了话语权?
开发工作流程。如果因紧急情况或事件需要改变工作方式——那么这个流程是否会被破坏?它需要被修理好吗?
utils(你放置随机东西的文件夹,不放在这里的话,你不知道该放在哪里)是代码味道(code smell)吗?
如何处理代码和工作流的文档?
如何监控UI才能知道什么时候出问题了?
花时间设计完美的API /代码合同,以及自己写出代码并反复迭代选出最优的那个之间,哪一种更好?
简单的方式vs正确的方式?我不觉得正确的方法永远是优越的。
自己做事vs教那些不会的人如何做事。前者完成速度快,后者意味着你以后就很少需要自己亲自动手了。
当重构和防止巨大问题时:“如果我先改变了所有的测试,那么我会看到我有52个文件需要修改,这显然太大了,但是我先去管代码而不是测试吧。”分开处理值得吗?
在降低风险(derisking)方面做进一步探索。有哪些策略可以降低项目的风险?
收集需求的有效方法有哪些?
如何降低系统退化率?
【END】
热 文 推 荐
Python 分析热门旅游景点,告诉你哪些地方好玩、便宜、人又少!
 点击阅读原文,BDTC 2019最新动态抢先看!
点击阅读原文,BDTC 2019最新动态抢先看!










