1、lucene的总体架构
1.1、lucene的特点
高效、可扩展的全文检索库;
仅支持纯文本的索引(Indexing)和搜索(Search);
搜索排名——最好的结果显示在最前面;
许多强大的查询类型:短语查询、通配符查询、近似查询、范围查询等;
对字段级别搜索(如标题,作者,内容);
可以对任意字段排序;
支持搜索多个索引并合并搜索结果;
支持更新操作和查询操作同时进行;
灵活的切面、高亮、join和group by功能;
速度快,内存效率高,容错性好;
可选排序模型,包括向量空间模型和BM25模型;
可配置存储引擎;
1.2、lucene的架构及处理过程

架构及处理过程.png
2、索引及搜索过程
2.1、索引及搜索组件:

索引及搜索组件.png
- 被索引的文档用Document对象 表示。
- IndexWriter 通过函数addDocument 将文档添加到索引中,实现创建索引的过程。
- Lucene 的索引是应用反向索引。
- 当用户有请求时,Query 代表用户的查询语句。
- IndexSearcher 通过函数search 搜索Lucene Index 。
- IndexSearcher 计算term weight 和score 并且将结果返回给用户。
- 返回给用户的文档集合用TopDocsCollector 表示。
2.2、索引及搜索实现:
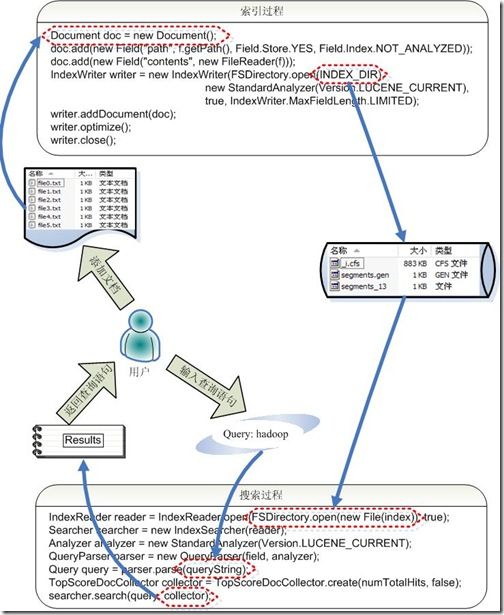
索引及搜索实现.png
索引过程:
- 创建一个IndexWriter 用来写索引文件,它有几个参数,INDEX_DIR 就是索引文件所存放的位置,Analyzer 便是用来对文档进行词法分析和语言处理的。
- 创建一个Document 代表我们要索引的文档。
- 将不同的Field 加入到文档中。我们知道,一篇文档有多种信息,如题目,作者,修改时间,内容等。不同类型的信息用不同的Field 来表示,在本例子中,一共有两类信息进行了索引,一个是文件路径,一个是文件内容。其中FileReader 的SRC_FILE 就表示要索引的源文件。
- IndexWriter 调用函数addDocument 将索引写到索引文件夹中。
搜索过程:
- IndexReader 将磁盘上的索引信息读入到内存,INDEX_DIR 就是索引文件存放的位置。
- 创建IndexSearcher 准备进行搜索。
- 创建Analyer 用来对查询语句进行词法分析和语言处理。
- 创建QueryParser 用来对查询语句进行语法分析。
- QueryParser 调用parser 进行语法分析,形成查询语法树,放到Query 中。
- IndexSearcher 调用search 对查询语法树Query 进行搜索,得到结果TopScoreDocCollector 。
3、Lucene模块结构

模块结构.png
- Lucene 的analysis 模块主要负责词法分析及语言处理而形成Term 。
- Lucene 的index 模块主要负责索引的创建,里面有IndexWriter 。
- Lucene 的store 模块主要负责索引的读写。
- Lucene 的QueryParser 主要负责语法分析。
- Lucene 的search 模块主要负责对索引的搜索。
- Lucene 的similarity 模块主要负责对相关性打分的实现。
4、lucene构建简单搜索
4.1、索引创建
public class Indexer {
private IndexWriter indexWriter;
public Indexer(String indexPath) throws IOException {
//索引初始化
Directory directory = FSDirectory.open(Paths.get(indexPath));
//配置分词器为CJK中文分词器
IndexWriterConfig writerConfig = new IndexWriterConfig(new CJKAnalyzer());
indexWriter = new IndexWriter(directory, writerConfig);
//删除所有索引,以防重复索引
indexWriter.deleteAll();
}
public void close() throws IOException{
indexWriter.close();
}
//将dataPath下的所有文件及文件夹进行索引
public int index(String dataPath) throws IOException{
File file = new File(dataPath);
if(!file.isFile()){
File[] fileNames = file.listFiles();
indexFile(file);
if(fileNames != null){
for (File f: fileNames){
index(f.getCanonicalPath());
}
}
return 1;
}else{
indexFile(file);
return 1;
}
}
//对文件名及路径进行索引
private void indexFile(File f) throws IOException{
System.out.println("index file:" + f.getCanonicalPath());
Document d = new Document();
//文件名
d.add(new TextField("name", f.getName(), Field.Store.YES));
//路径
d.add(new TextField("path", f.getCanonicalPath(), Field.Store.YES));
int suffixIndex = f.getName().indexOf('.');
indexWriter.addDocument(d);
}
}
4.2、搜索处理
public class Searcher {
public static void search(String indexDir, String q) throws IOException, ParseException {
// 得到读取索引文件的路径
Directory dir = FSDirectory.open(Paths.get(indexDir));
// 通过Dir得到路径下所有文件
IndexReader reader = DirectoryReader.open(dir);
// 建立索引查询器
IndexSearcher searcher = new IndexSearcher(reader);
// 实例化分析器
Analyzer analyzer = new StandardAnalyzer();
/********建立查询解析器********/
// 第一个参数是要查询的字段; 第二个参数市分析器Analyzer
String[] fields = {"name", "path"};
Map fieldMap = new HashMap<>();
fieldMap.put("name",100.0f);
fieldMap.put("path",1.0f);
QueryParser parser = new MultiFieldQueryParser(fields,new CJKAnalyzer());
// 根据传进来的q查找
Query query = parser.parse(q);
// 计算索引开始时间
long start = System.currentTimeMillis();
/********开始查询********/
// 第一个参数是通过传过来的参数来查找得到的query; 第二个参数是要查询出的行数
TopDocs hits = searcher.search(query,10);
// 计算索引结束时间
long end = System.currentTimeMillis();
System.out.println("匹配 "+ q + ",查询到 " + hits.totalHits + " 个记录, 用时:" + (end - start));
// 遍历hits.scoreDocs,得到scoreDoc
// scoreDoc:得分文档,即得到的文档 scoreDocs:代表topDocs这个文档数组
for (ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = searcher.doc(scoreDoc.doc);
System.out.println("name:" + doc.get("name") + " ,path=" + doc.get("path"));
}
//关闭reader
reader.close();
}
}
4.3、测试及输出
测试代码:
public class Main {
private static String INDEX_PATH = "D:\\index";
public static void main(String[] args){
try {
Indexer indexer = new Indexer(INDEX_PATH);
indexer.index("D:\\book");
indexer.close();
Searcher.search(INDEX_PATH,"mongodb");
}catch (Exception e){
System.out.println(e.getCause());
}
}
}
输出结果:
index file:D:\book
index file:D:\book\Elasticsearch
index file:D:\book\Elasticsearch\Elasticsearch 权威指南.pdf
index file:D:\book\Elasticsearch\ElasticSearch+可扩展的开源弹性搜索解决方案.pdf
index file:D:\book\Elasticsearch\ElasticSearchManual.pdf
index file:D:\book\Elasticsearch\elasticsearch介绍与使用-new.pptx
index file:D:\book\Elasticsearch\elasticsearch技术解析与实战.pdf
index file:D:\book\Elasticsearch\Elasticsearch服务器开发(第2版).pdf
index file:D:\book\Elasticsearch\Elasticsearch集成Hadoop最佳实践.pdf
index file:D:\book\Elasticsearch\ppt文档
index file:D:\book\Elasticsearch\ppt文档\Elasticsearch 调研.pptx
index file:D:\book\Elasticsearch\ppt文档\elasticsearch介绍与使用-new.pptx
index file:D:\book\Elasticsearch\ppt文档\es geo.pptx
index file:D:\book\Elasticsearch\ppt文档\ES 创建索引代码流程.pptx
index file:D:\book\Elasticsearch\ppt文档\ES-Client研究.pptx
index file:D:\book\Elasticsearch\ppt文档\ES5 alpha4的leader选举.pptx
index file:D:\book\Elasticsearch\ppt文档\ES数据迁移.pptx
index file:D:\book\Elasticsearch\ppt文档\ES服务化实践.pptx
index file:D:\book\Elasticsearch\ppt文档\ES相关系统介绍.pptx
index file:D:\book\Elasticsearch\ppt文档\ES简介.pptx
index file:D:\book\Elasticsearch\大数据搜索与日志挖掘及可视化方案 ELK Stack Elasticsearch Logstash Kibana 第2版.pdf
index file:D:\book\Elasticsearch\深入理解ElasticSearch.pdf
index file:D:\book\java多线程
index file:D:\book\java多线程\Java 并发编程实战.pdf
index file:D:\book\java多线程\Java多线程编程实战指南 设计模式篇.pdf
index file:D:\book\java多线程\Java多线程编程核心技术_完整版 PDF电子书下载 带书签目录.pdf
index file:D:\book\java多线程\java多线程设计模式详解.pdf
index file:D:\book\java多线程\java多线程设计模式详解PDF及源码.zip
index file:D:\book\java多线程\Java并发程序设计教程-2010-08-10.pdf
index file:D:\book\java多线程\Java并发编程的艺术.pdf
index file:D:\book\java多线程\Java并发编程:设计原则与模式(第二版).pdf
index file:D:\book\java多线程\[email protected]
index file:D:\book\java多线程\七周七并发模型.pdf
index file:D:\book\java多线程\分布式java应用-基础与实际.pdf
index file:D:\book\java虚拟机
index file:D:\book\java虚拟机\HotSpot实战.pdf
index file:D:\book\java虚拟机\Java性能权威指南.pdf
index file:D:\book\java虚拟机\Java程序员修炼之道.pdf
index file:D:\book\java虚拟机\Java程序性能优化-.让你的Java程序更快、更稳定.pdf
index file:D:\book\java虚拟机\Java虚拟机规范 Java SE 8版@www.jqhtml.com.pdf
index file:D:\book\java虚拟机\深入理解Java虚拟机:JVM高级特性与最佳实践.pdf
index file:D:\book\java语言
index file:D:\book\java语言\Java 8函数式编程.pdf
index file:D:\book\java语言\Java 8实战.pdf
index file:D:\book\Lucene
index file:D:\book\Lucene\Lucene 实战(第2版).pdf
index file:D:\book\Lucene\Lucene搜索引擎开发权威经典.pdf
index file:D:\book\Lucene\Lucene搜索引擎开发进阶实战www.java1234.com.pdf
index file:D:\book\Lucene\《从Lucene到Elasticsearch 全文检索实战》.pdf
index file:D:\book\Lucene\从Lucene到Elasticsearch:全文检索实战@www.java1234.com.pdf
index file:D:\book\Lucene\开放源代码的全文检索引擎Lucene.pdf
index file:D:\book\Lucene\解密搜索引擎技术实战 LUCENE & JAVA精华版 第3版@www.java1234.com.pdf
index file:D:\book\mongodb
index file:D:\book\mongodb\MongoDB大数据处理权威指南 第2版 .pdf
index file:D:\book\mongodb\mongodb实战.pdf
index file:D:\book\mongodb\MongoDB权威指南第2版.pdf
index file:D:\book\《从Lucene到Elasticsearch 全文检索实战》.pdf
匹配 mongodb,查询到 4 hits 个记录, 用时:184
name:mongodb ,path=D:\book\mongodb
name:mongodb实战.pdf ,path=D:\book\mongodb\mongodb实战.pdf
name:MongoDB权威指南第2版.pdf ,path=D:\book\mongodb\MongoDB权威指南第2版.pdf
name:MongoDB大数据处理权威指南 第2版 .pdf ,path=D:\book\mongodb\MongoDB大数据处理权威指南 第2版 .pdf
Disconnected from the target VM, address: '127.0.0.1:50869', transport: 'socket'
github:https://github.com/zhaozhou11/search-demo.git
参考博客:
https://blog.csdn.net/forfuture1978/article/details/4745802