python数据分析知识点汇总(一)
一、缺失值
1.缺失值的产生 ?有以下3种情况
(1)有些信息暂时无法获取
(2)有些信息被遗漏
(3)有些信息被错误处理
2、缺失值的处理方法有哪些?主要有以下3种
(1)数据补齐
(2)删除对应缺失行
(3)不处理
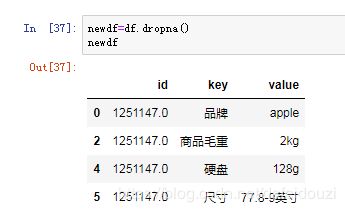
3、缺失值处理,删除对应缺失行用的是dropna()函数
- dropna函数作用:去除数据结构中值为空的数据
- dropna函数语法:dropna()
下面用一个例子说明:
先导入库,别名
import pandas as pd
import numpy as np然后这里有一个带有缺失值的商品的数据(品牌、商品名称、商品毛重、产地、硬盘、尺寸)

这时候我们想要删除缺失值所在行,就可以用上面说的dropna()函数
二、空值处理
- 处理空值用的是strip()函数
- strip函数作用:清除字符数据左右的空格
- strip函数用法:strip()

三、字段提取
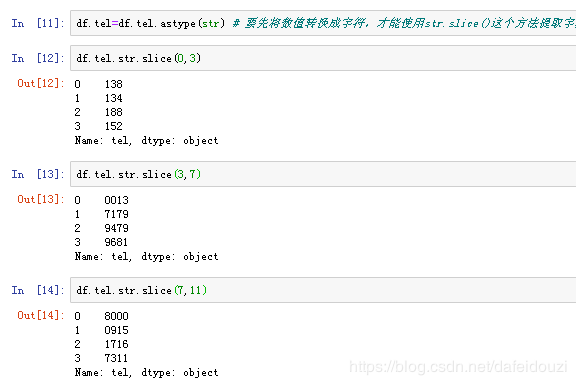
- 字段提取是根据已知列数据的开始和结束位置,抽取出新的列
- 字段截取函数: slice(start,stop)
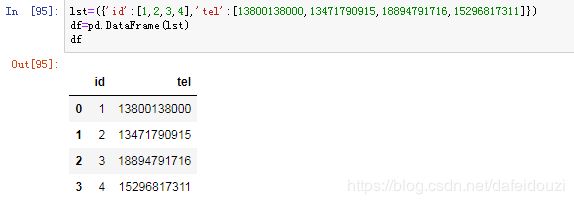
这里我生成了3个电话号码,我想提取出这几串号码的某几个数字
因为电话号码是数值,要将数值转换成字符才能用str.slice()这个方法提取字段
四、字段拆分
- 字段拆分是指按照固定的字符,拆分已有字符串
- 字符分割函数:split(sep,n,expand=False)
- 参数说明:sep 用于分割的字符串;n 分割成几列;expand 是否展开为dataframe,默认为False
- 返回值:如果expand为True,返回dataframe;如果expand为False,则返回series
下面用例子说明,我用的是之前博文里面的店铺数据

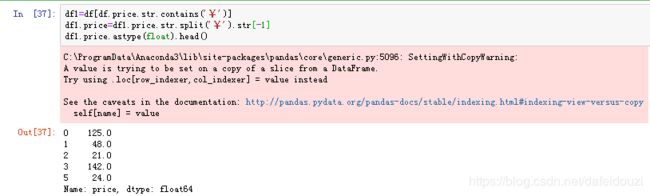
我要分割price这个字段,提取出price这列的数值,观察price这一列可以看到,所有带有‘¥’这个符号的都跟着价格,带有‘人均’这两个字的不一定带有价格,因此我们就根据‘¥’这个固定字符去拆分字符串,并提取出价格;
平时用到最多的筛选应该是字符串的模糊筛选,在pandas中一般使用str.contains()来实现;先是通过str.contains()筛选出带有'¥'这个符号的字符串,然后使用split()根据'¥'去分割字符串,因为价格这个数值是在最后一个位置,所以我提取的时候用了str[-1],这里要注意的是从左到右0开始,从右到左-1开始。
五、记录抽取
- 记录抽取是根据一定的条件对数据进行抽取
- 记录抽取函数:dataframe[condition]
- 参数说明: condition 过滤的条件
- 返回值:dataframe
常用的条件类型
(1)比较运算:(>、<、>=、<=、!=)
例如:df[df.comments>10000]
(2)范围运算 between(left,right)
例如:df[df.comments.between(1000,10000)]
(3)空值匹配 pandas.isnull(column)
例如:df[pandas.isnull(df.title)]
(4)字符匹配 str.contains(patten,na=False)
例如:df[df.title.str.contains('台电',na=False)]
(5)逻辑运算:与(&)、或(|)、取反(not)
例如:df[(df.comments>=1000)&(df.comments<=10000)]
与上面的范围运算 (df[df.comments.between(1000,10000)])等价
还是前面的店铺数据,我就用上面已经提取出来的价格进行记录抽取操作
提取出价格大于1000的所有店铺信息
提取出价格在(1000,5000)之间的所有店铺信息,有两种方法:
