SQL 改写,优化SQL
我一直以为 会写SQL, 是最实在的基础,会写SQL了,才会优化SQL,会优化SQL,才知道怎么设计表结构,进而设计更加精妙的业务类型, 业务类型就大致知道IO的大致规律。 从而知道更加复杂的架构模型。好了废话不多说:
上SQL; SQL老复杂了, 我也是耐得住寂寞看下来的。也不知道哪位大师,大神,大拿,大爷写的SQL:
SELECT MR_MODE_CODE MODE_CODE,
MR_MODE_CODE MODE_NAME,
SHOULD_COUNT,
ACTUAL_COUNT,
BEFORE_COUNT,
AFTER_COUNT,
ACTUAL_COUNT - BEFORE_COUNT - AFTER_COUNT NORMAL_COUNT,
SHOULD_COUNT - ACTUAL_COUNT NO_COUNT,
GU_COUNT,
TOTAL_MNT
FROM (SELECT P.MR_MODE_CODE,
NVL(SUM((SELECT COUNT(DISTINCT R.CONS_NO)
FROM (SELECT *
FROM R_DATA
WHERE ORG_NO = '34401'
AND SRC_CODE = '01'
AND AMT_YM = '201806'
UNION ALL
SELECT *
FROM ARC_R_DATA
WHERE ORG_NO = '34401'
AND SRC_CODE = '01'
AND AMT_YM = '201806') R
WHERE R.MR_PLAN_NO = P.MR_PLAN_NO
GROUP BY P.MR_PLAN_NO)),
0) SHOULD_COUNT,
NVL(SUM((SELECT COUNT(DISTINCT R.CONS_NO)
FROM (SELECT *
FROM R_DATA
WHERE ORG_NO = '34401'
AND SRC_CODE = '01'
AND AMT_YM = '201806'
UNION ALL
SELECT *
FROM ARC_R_DATA
WHERE ORG_NO = '34401'
AND SRC_CODE = '01'
AND AMT_YM = '201806') R
WHERE P.MR_PLAN_NO = R.MR_PLAN_NO
AND R.MR_STATUS_CODE >= '02'
AND R.MR_STATUS_CODE <= '03')),
0) ACTUAL_COUNT,
NVL(SUM((SELECT COUNT(DISTINCT R.CONS_NO)
FROM R_DATA R
WHERE P.MR_PLAN_NO = R.MR_PLAN_NO
AND R.MR_STATUS_CODE >= '02'
AND R.MR_STATUS_CODE <= '03'
AND SRC_CODE = '01'
AND AMT_YM = '201806'
AND R.THIS_YMD <
TO_DATE(P.PLAN_MR_DATE, 'YYYY-MM-DD')) +
(SELECT COUNT(DISTINCT R.CONS_NO)
FROM ARC_R_DATA R
WHERE P.MR_PLAN_NO = R.MR_PLAN_NO
AND R.MR_STATUS_CODE >= '02'
AND R.MR_STATUS_CODE <= '03'
AND SRC_CODE = '01'
AND AMT_YM = '201806'
AND R.THIS_YMD <
TO_DATE(P.PLAN_MR_DATE, 'YYYY-MM-DD'))),
0) BEFORE_COUNT,
NVL(SUM((SELECT COUNT(DISTINCT R.CONS_NO)
FROM R_DATA R
WHERE P.MR_PLAN_NO = R.MR_PLAN_NO
AND R.MR_STATUS_CODE >= '02'
AND R.MR_STATUS_CODE <= '03'
AND SRC_CODE = '01'
AND AMT_YM = '201806'
AND R.THIS_YMD >=
TO_DATE(P.PLAN_MR_DATE, 'YYYY-MM-DD') + 1) +
(SELECT COUNT(DISTINCT R.CONS_NO)
FROM ARC_R_DATA R
WHERE P.MR_PLAN_NO = R.MR_PLAN_NO
AND R.MR_STATUS_CODE >= '02'
AND R.MR_STATUS_CODE <= '03'
AND SRC_CODE = '01'
AND AMT_YM = '201806'
AND R.THIS_YMD >=
TO_DATE(P.PLAN_MR_DATE, 'YYYY-MM-DD') + 1)),
0) AFTER_COUNT,
NVL(SUM((SELECT COUNT(DISTINCT R.CONS_NO)
FROM R_DATA R
WHERE P.MR_PLAN_NO = R.MR_PLAN_NO
AND R.MR_STATUS_CODE = '03'
AND SRC_CODE = '01'
AND AMT_YM = '201806') +
(SELECT COUNT(DISTINCT R.CONS_NO)
FROM ARC_R_DATA R
WHERE P.MR_PLAN_NO = R.MR_PLAN_NO
AND R.MR_STATUS_CODE = '03'
AND SRC_CODE = '01'
AND AMT_YM = '201806')),
0) GU_COUNT,
NVL(SUM(NVL((SELECT SUM(NVL(R.THIS_READ_PQ, 0))
FROM R_DATA R
WHERE P.MR_PLAN_NO = R.MR_PLAN_NO
AND R.MR_STATUS_CODE >= '02'
AND R.MR_STATUS_CODE <= '03'
AND AMT_YM = '201806'
AND R.READ_TYPE_CODE = '11'),
0) + NVL((SELECT SUM(NVL(R.THIS_READ_PQ, 0))
FROM ARC_R_DATA R
WHERE P.MR_PLAN_NO = R.MR_PLAN_NO
AND R.MR_STATUS_CODE >= '02'
AND R.MR_STATUS_CODE <= '03'
AND AMT_YM = '201806'
AND R.READ_TYPE_CODE = '11'),
0)),
0) TOTAL_MNT
FROM R_PLAN P
WHERE P.AMT_YM = '201806'
AND P.ORG_NO = '34401'
AND P.EVENT_TYPE != '003'
GROUP BY P.MR_MODE_CODE)
简单说下, R_PLAN P二级分区表 P.AMT_YM = '201806'
AND P.ORG_NO = '34401'已经定位到某最下级分区, 数据量也不大。这个SQL除了改写别无他发。。。 好多相似标量子查询可以通过外连接关联从而一次性取数。而不是在标量中, 输出一次取一次数据。(这个太坑了,这个得多少重复扫描?)很多业务经不住高并发,我目前看就是因为这种数据太多,导致CPU压力持续性高位。因为你取数据逻辑有问题。重复重复多次多次取数啊。。。
耐住寂寞改写SQL。 这个SQl整了好长时间,基本上一个代码代码敲出来的。
select tab1.MR_MODE_CODE MODE_CODE , tab1.MR_MODE_CODE MODE_NAME, SHOULD_COUNT,ACTUAL_COUNT,BEFORE_COUNT, AFTER_COUNT,
ACTUAL_COUNT - BEFORE_COUNT - AFTER_COUNT NORMAL_COUNT,
SHOULD_COUNT - ACTUAL_COUNT NO_COUNT,
GU_COUNT,TOTAL_MNT
from ( select MR_MODE_CODE,
count(distinct CONS_NO2)+count(distinct CONS_NO3) BEFORE_COUNT,
count(distinct CONS_NO4)+count(distinct CONS_NO5) AFTER_COUNT,
count(distinct CONS_NO6)+count(distinct CONS_NO7) GU_COUNT,
nvl(sum( CONS_NO8),0)+nvl(sum( CONS_NO9),0) TOTAL_MNT
from ( SELECT P.MR_MODE_CODE,
case when r2.MR_STATUS_CODE >= '02' and r2.MR_STATUS_CODE <= '03' and r2.SRC_CODE = '01' AND r2.THIS_YMD < TO_DATE(P.PLAN_MR_DATE, 'YYYY-MM-DD')
then r2.CONS_NO else null end CONS_NO2,
case when r3.MR_STATUS_CODE >= '02' and r3.MR_STATUS_CODE <= '03' and r3.SRC_CODE = '01' AND r3.THIS_YMD < TO_DATE(P.PLAN_MR_DATE, 'YYYY-MM-DD')
then r3.CONS_NO else null end CONS_NO3,
case when r2.MR_STATUS_CODE >= '02' and r2.MR_STATUS_CODE <= '03' and r2.SRC_CODE = '01' AND r2.THIS_YMD >= TO_DATE(P.PLAN_MR_DATE, 'YYYY-MM-DD')+1
then r2.CONS_NO else null end CONS_NO4,
case when r3.MR_STATUS_CODE >= '02' and r3.MR_STATUS_CODE <= '03' and r3.SRC_CODE = '01' AND r3.THIS_YMD >= TO_DATE(P.PLAN_MR_DATE, 'YYYY-MM-DD')+1
then r3.CONS_NO else null end CONS_NO5 ,
case when r2.MR_STATUS_CODE = '03' and r2.SRC_CODE = '01'
then r2.CONS_NO else null end CONS_NO6,
case when r3.MR_STATUS_CODE = '03' and r3.SRC_CODE = '01'
then r3.CONS_NO else null end CONS_NO7,
case when r2.MR_STATUS_CODE >= '02' and r2.MR_STATUS_CODE <= '03' and R2.READ_TYPE_CODE = '11'
then r2.THIS_READ_PQ else null end CONS_NO8,
case when r3.MR_STATUS_CODE >= '02' and r3.MR_STATUS_CODE <= '03' and R3.READ_TYPE_CODE = '11'
then r3.THIS_READ_PQ else null end CONS_NO9
FROM sgpms.R_PLAN P
left join sgpms.R_DATA r2 on P.MR_PLAN_NO = R2.MR_PLAN_NO and r2.AMT_YM = '201806'
left join sgpms.ARC_R_DATA r3 on P.MR_PLAN_NO = R3.MR_PLAN_NO and r3.AMT_YM = '201806'
WHERE P.AMT_YM = '201806'
AND P.ORG_NO = '34401'
AND P.EVENT_TYPE != '003'
) group by MR_MODE_CODE
) tab1 left join (
SELECT P.MR_MODE_CODE, sum( CONS_NO_CNT1) SHOULD_COUNT ,sum( CONS_NO_CNT2) ACTUAL_COUNT
FROM sgpms.R_PLAN P
inner join ( select MR_PLAN_NO, count(distinct CONS_NO) CONS_NO_CNT1,count(case when MR_STATUS_CODE >= '02' and MR_STATUS_CODE <= '03' then CONS_NO else null end ) CONS_NO_CNT2
from ( SELECT MR_PLAN_NO,CONS_NO ,MR_STATUS_CODE FROM sgpms.R_DATA
WHERE ORG_NO = '34401'
AND SRC_CODE = '01'
AND AMT_YM = '201806'
UNION
SELECT MR_PLAN_NO,CONS_NO,MR_STATUS_CODE
FROM sgpms.ARC_R_DATA
WHERE ORG_NO = '34401'
AND SRC_CODE = '01'
AND AMT_YM = '201806')
group by MR_PLAN_NO ) r1 on r1.MR_PLAN_NO = P.MR_PLAN_NO
WHERE P.AMT_YM = '201806'
AND P.ORG_NO = '34401'
AND P.EVENT_TYPE != '003'
GROUP BY P.MR_MODE_CODE
) tab2 on tab1.MR_MODE_CODE = tab2.MR_MODE_CODE;
原来的SQL对表R_DATA,ARC_R_DATA 扫描6次。扫描次数太多。 通过SQL等价改写后 R_DATA,ARC_R_DATA 扫描2次。
改写前: 8S, 40万逻辑读,2万内存排序。

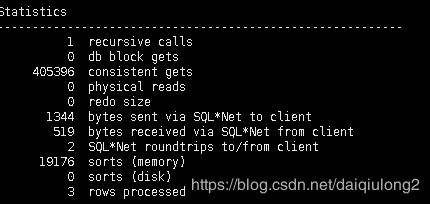
改写后:7.6S 18万逻辑读 2 内存排序。

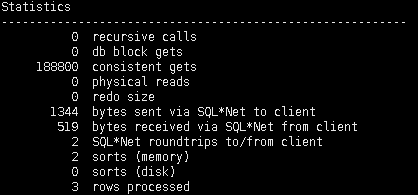
有的人说速度不过提升了 0.4S。 其实这样说不对, 因为如果用时间维度评价一个SQl的优化效果的话。因为系统压力高峰期,和低峰期根本就是2个概念啊。。。 高峰期取40万逻辑读试试看?? 和可能 5分钟以上。。。
而且第一个SQL明显内存排序2万个。 高峰期很可能用到磁盘排序。。 磁盘排序2万个试试看?? 时间出来老长了!!
可能对20万逻辑读没有概念。 1G表,如果全部在内存中,扫描一把,估计只有13万逻辑读左右。 1G的表什么概念呢? 就好比常见的表, 1千万条数据左右吧。。 大宽表就另算了哈。。。