关于L0,L1和L2范数的规则化
本文主要整理一下机器学习中的范数规则化学习的内容:
- 规则化
-什么是规则化
-为什么要规则化
-规则化的理解
-怎么规则化
-规则化的作用 - 范数
-L0范数和L1范数
-L2范数
-L1范数和L2范数 - 补充
-condition number
-微博、知乎部分讨论 - 参考附录
规则化
什么是规则化?
回顾一下机器学习算法的3个要点:1.根据数据找合适的模型;2.定义损失以评估模型;3.设计求解优化的方法。
再回顾一下监督学习:规则化参数(防止模型过分拟合训练数据)的同时最小化误差(模型拟合训练数据的偏差)。
Regularization, in mathematics and statistics and particularly in the fields of machine learning and inverse problems, refers to a process of introducing additional information in order to solve an ill-posed problem or to prevent overfitting. —— from wikipedia
Regularization是引入额外的信息来解决ill-posed问题或者防止overfitting的过程。
规则化的表现形式: ω∗=argminω∑iL(yi,f(xi;ω))+λΩ(ω)
第一项是衡量模型对样本的预测与真实的误差(二者越接近越好),最小化误差指该部分。
第二项是对参数w的规则化函数Ω(w)约束模型(使模型简单)。最小化模型测试误差指该部分。
为什么要规则化?
为了解决ill-posed问题或者防止overfitting,期望获得一个能够很好地解释数据而且simple的模型,或者从统计角度来说,是找一个减少过度拟合的估计方法。
一般从线性回归问题也称最小二乘问题(Least Squares Problem, LSP)和逻辑回归问题(Logistic Regression Problem, LRP)引入。前者想象预测的变量是数字,后者预测的变量是“是/否”的这种分类答案。这两个问题中会出现下面的情况导致overfitting:
- When the number of observations or training examples m is not large enough compared to the number of feature variables n, over-fitting may occur. 样本数量m选不如特征维度n大
- Tends to occur when large weights are found in x. 待预测的向量x的有过大的权重,也就是拟合函数的系数过大【考虑太过全面,把noise 或者 error in the data都考虑进去了,过分拟合。这样导致拟合函数波动大。同一量级上考虑,系数小曲线偏平滑,系数大,曲线偏陡峭】
针对1.解决方法是:
- 减少特征数量
- 可以人工选择重要的特征变量以减少特征数。
- 自动的,特征选择(Feature Selection) -> 稀疏性 -> 正则化
-增加样本数量
针对2.解决方法是:
- 正则化
当然还有其他的方法,本文不介绍了。eg.cross-validation, early stopping, pruning, Bayesian priors on parameters or model comparison
规则化的理解
让模型简单,意味着要采取措施降低模型复杂度(过多参数导致模型复杂–稀疏 is ok),使用规则项来约束模型(约束了待学习的模型参数w,也就变相约束了模型)的特性。
还有几种种理解角度:
角度一
经验风险=平均损失函数 ,结构风险=损失函数+正则化项(惩罚项)
正则化是结构风险最小化的策略。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。比如,模型参数向量的范数。角度二
正则化项的引入其实是利用了先验知识,体现了人对问题的解的认知程度或者对解的估计。这样就可以将人对该问题的理解和需求(先验知识)融入到模型的学习当中,对模型参数设置先验,强行地让学习到的模型具有人想要的特性,例如稀疏、低秩、平滑等等。(正则与稀疏、低秩和平滑的关系)
L1正则是laplace先验,l2是高斯先验,分别由参数sigma确定。角度三
附录的Sparsity and the Lasso
最小二乘问题中,ranx(A)<样本数量。对要解决的问题加限制条件(角度二中的先验)–>[subject to]
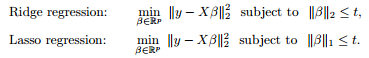
图像表示出来是这样的:

利用对偶,KKT等转化成这样:为什么要凸的,这就用着了。
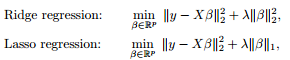
本质上都差不多,切入点不同,就可以从不同方面理解了。
怎么规则化?
前面提到,正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大(为了给予复杂模型以惩罚,因为优化的时候要最小化函数,想要得到simple模型,越复杂,惩罚越大),并且优化过程还想得到稀疏的参数。(看怎么理解稀疏了,L1参数大多为0,L2参数大多接近0)。下面介绍的是用向量范数的形式来规则化,看范数那一节。
为什么参数要稀疏呢?——特征选择;问题的可解释性
1. 特征选择:large-scale 可能大部分特征是对于最终的输出y是无影响的或者影响很小的。训练时最小化目标函数,如果考虑这些特征会得到更小的误差,但是会对新样本的预测结果产生影响。Lasso regularization的引入是为了完成特征自动选择,它会在优化过程中主动去学习去掉这些没有用的特征,把特征对应的权重置为0。【L1】
2. 可解释性:例如一回归问题,假设回归模型为:y=w1*x1+w2*x2+…+w1000*x1000+b。通过学习,如果最后学习到的w*,只有很少的非零元素,大部分w*为0或接近于0,例如只有5个非零的wi,那可以认为y只受这5个xi(因素)的影响,更有利于人们对问题的认识和分析,抓住影响问题的主要方面(因素)更符合认知习惯。【L2】
【正则与平滑】实际上,这些参数值越小,通常对应于越光滑的函数,也就是更加简单的函数。
【正则与稀疏】为什么正则化会使参数稀疏呢?
规则化的作用?
- 防止过拟合(平衡了偏差与方差,拟合能力与泛化能力,结构风险和经验风险);
- 正则化导致的稀疏性是有益的:特征选择以及把人对于问题的认知作为先验引入优化过程中;
- 降低condition number,处理因其过大导致逆矩阵不好求的情况;
范数
L0范数和L1范数
L0范数是指向量中非0的元素的个数。
L1范数是指向量中各个元素绝对值之和,也称Lasso regularization
如果用L0范数来规则化一个参数矩阵W的话,就是希望W的大部分元素都是0,也就是让参数W是稀疏的。L0应该不算是norm。像L1,L2等可以转换到convex或者本身就是convex的这种算norm。(能用来优化)
为什么L1范数会使权值稀疏?
见L1范数和L2范数部分。
L2范数
∥x∥2 权值衰减 weight decay , 回归问题里叫岭回归(ridege regression)
指向量各元素的平方和再求平方根。让L2范数的规则项最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0。
L2范数好处
1.学习理论角度——L2范数可以防止过拟合,提升模型的泛化能力
2.优化计算角度——L2范数有助于处理 矩阵 condition number不好的情况下矩阵求逆很困难的问题
为什么L2范数有助于处理矩阵condition number不好的情况下矩阵求逆很困难的问题?
以最小二乘问题LSP为例,添加正则项(add “preference” for certain parameter values)之后的cost function J :
用同样的方法,求得新的解的表达式为
此时,该问题是well-posed,加入了L2正则后,改善了 X−−TX−− 的condition number,而且不需要直接求逆矩阵,可通过解线性方程组的众多方法来解决。如果说我本来也不准备求逆矩阵,用迭代方法求解可不可以不加正则项了?condition number 太大,收敛速度慢。
L1范数和L2范数
Unlike the L2-regularization which restricts large values, the L1-regularization term penalizes all factors equally, which can create sparse answers.
参考附录9
- example 1

解释一下,考虑向量 x⃗ =(1,ε)∈R2 且 ε<0 ,给出 x⃗ 的L1,L2范数。作为正则化的过程,减少 x⃗ 其中的一个元素(相当于在某个元素上添加扰动)。给出了 x1 , x2 分别减少 δ(δ≤ε) 之后的L1,L2范数。
L2范数结果,考虑减小 δ 之后的新的 x⃗ 中的x1,x2。对于较大的x1会产生大的reduction (1+ε2)−(1−2δ+δ2+ε2)=2δ−δ2 ,对于接近于0的x2会产生很小的reduction (1+ε2)−(1−2δε+δ2+ε2)=2δε−δ2 .比较一下二者的量级,不平等的惩罚(把reduction看做惩罚),值大的惩罚大,值小的惩罚小。【restricts large values】
L1范数结果,不论扰动给x1还是x2,前后的reduction都是 δ ,平等的惩罚(给谁扰动都是一样的惩罚)。一直按着这个步子朝着0前进。【penalizes all factors equally->can create sparse answers】
用L2范数惩罚模型,惩罚进程中,不太可能有任何元素被置为0。主要看值小的那一项(给x2添扰动,值小的靠近0,看看他的变化情况), reduction=2δε−δ2 ,下一次的扰动后, reduction=4δε−3δ2 ,可以看到reduction越来越小,而且和x2本身的值,不在一个数量级上。
L1范数惩罚可以使稀疏;L2惩罚过程中,元素朝着0移动的这种reduction越来越小,意味着移动速度越来越慢,一定程度上阻碍了稀疏性。可以根据范数的图像,看导数。
- example 2
考虑含有参数 (ω1,ω2,...,ωm) 的模型。用L1正则,用一个loss function L1(ω)=∑i|ωi| 来惩罚模型。用L2正则,用loss function L2(ω)=12∑iω2i 惩罚模型。
假设只考虑模型的一个参数 ω1 ,loss function 和其导函数图像如下。
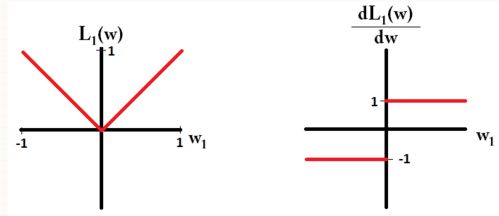
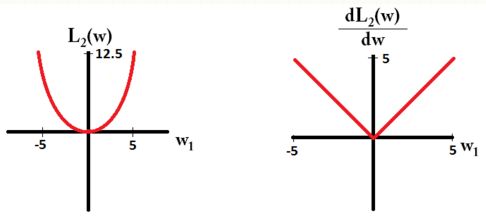
Notice that for L1, the gradient is either 1 or -1, except for when w1=0. That means that L1-regularization will move any weight towards 0 with the same step size, regardless the weight’s value. In contrast, you can see that the L2 gradient is linearly decreasing towards 0 as the weight goes towards 0. Therefore, L2-regularization will also move any weight towards 0, but it will take smaller and smaller steps as a weight approaches 0.
假设以 ω1=5 , η=12
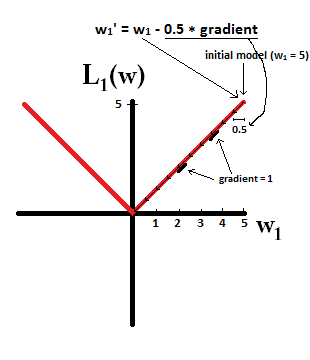
L1-regularization 10步 就可以把 ω1 置为0。
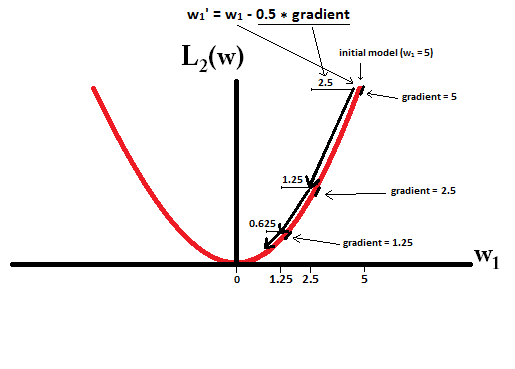
L2-regularization 每一步都是只前进 0.5∗ω1 ,参数 ω1 永远不能到0。 12+14+18+...+12n+...<1
Note that L2-regularization can make a weight reach zero if the step size ηη is so high that it reaches zero or beyond in a single step. However, the loss function will also consist of a term measuring the error of the model with the respect to the given weights, and that term will also affect the gradient and hence the change in weights. However, what is shown in this example is just how the two types of regularization contribute to a change in weights.
还是这个图。
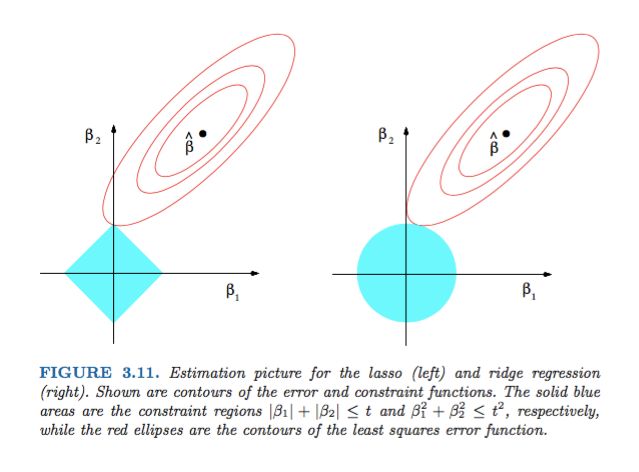
看上图可以得出其实Lp范数,p<=1都有稀疏解。p<1退化,解不唯一。
微博、知乎部分讨论
微博
1. Loss对应的是目标函数的形状,惩罚项对应的是可行域形状,限制可行域是可以带来sparsity,限制目标函数不行。
2. 稀疏性 和系数的L1正则有关系,而不是损失的L1。损失和正则这两个要分清楚。PS:系数的L1正则是系数L0正则的凸稀疏代理,见压缩感知compressed sensing相关论文。
3. L1有特征选择的作用,选择L1还是L2我觉得得看样本的方差情况,想在多大程度上去拟合不大靠谱的样本点。 L2对outlier更敏感。
知乎
1. 可以想象用梯度下降的方法,当w小于1的时候,L2正则项的惩罚效果越来越小,L1正则项惩罚效果依然很大,L1可以惩罚到0,而L2很难。
2. 我们假设有两个完全一样的特征,使用L2正则想的话,两个特征权重相等的时候惩罚最小,所以L2具有权重平均分配的效果。
3. L1、L2都可以防止过拟合,只不过手段不同:L1是舍弃掉一些不重要的特征,L2是控制所有特征的权重。
补充内容
condition number
The condition number of the matrix measures the ratio of the maximum relative stretching to the maximum relative shrinking that matrix does to any non zero vectors. To discuss the errors in numerical problems involving vectors, it is useful to employ
norms.
描述数的绝对误差可以用绝对值,那么如何衡量向量的类似差异——norm,看成绝对值的拓展把。实际角度来看,引入范数为了度量线性代数方程组解的误差的大小,而方程组的解是向量。
定义: κ(A)=∥A∥⋅∥∥A−1∥∥
要求: 方阵A 满秩(非奇异) ,约定 A是奇异的话 κ(A)是无穷大 [也有的记为cond(A)]
从数值分析来理解:condition number of a matrix A 是一种描述方式——描述线性系统Ax=b近似效果的好坏)模型不可能与实际完全一致只能近似,更贴切地理解为线性系统稳定程度和敏感度)。其中,κ(A)小,在1附近,问题是well-conditioned;κ(A)大,远大于1,问题是 ill-conditioned。注意矩阵条件数永远不会小于1. κ(A)=∥A∥⋅∥∥A−1∥∥≥∥∥A⋅A−1∥∥=1
参数微小扰动不会导致解的急剧的不均的变化——condition number值小——well-conditioned;
参数微小扰动导致解的高度敏感的响应——condition number值大——ill-conditioned。
Vector Norm
向量范数 3个条件-略
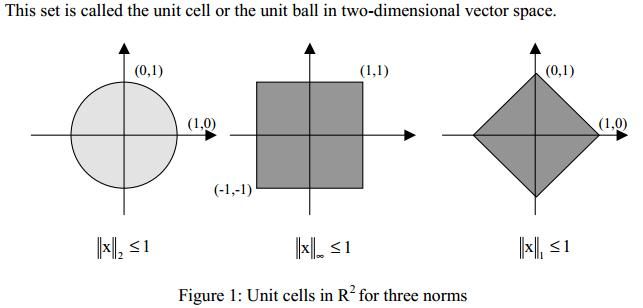
通常来说,对任意向量x来说,根据向量范数定义就可以求得到 ∥x∥1≥∥x∥2≥∥x∥∞
- observation b 带噪声

b的一个相对小变化,导致solution Δx 的相对变化。cond(A)相当于一个bound的放大系数。给定一个相对的变化量 Δb ,就会有一个系统的解的最大相对改变量的bound。
Matrix Norm
矩阵范数 4个条件-略
Norm of matrix measures maximum stretching matrix does to any vector in given vector norm.
1.对任何非零向量衡量其相对最大拉伸和相对收缩的比率。
2.值越大,矩阵转换的时,unit sphere单位球(指向量范数的区域)更扭曲[失真]
eg. 以二维空间举例, L2 -norm是单位圆,随着condition number的增加,单位圆会越来越朝着雪茄形状的椭圆变化; L1 , L∞ 的unit sphere从方形越来越朝着倾斜的平行四边形变化。
- observation A 带噪声
由上面向量b的扰动变化类比到矩阵A的对应情况:
![]()
![]()
![]()
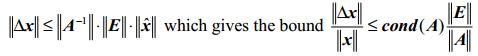
condition number乘以相对变化(in the problem data) 产生了解的最大相对变化量的bound。
上面不等式左端solution的相对变化,分母换成 x+Δx 更容易推导。
computing condition number
condition number 在评估线性体统的accuracy上是usefulness,但是按定义计算出condition number的具体值 比直接解决线性系统的精度评估问题更费力,主要耗费的地方在于求逆矩阵,那怎么办?
实际中,不具体求condition number值,而是估算它的数量级。
∥A∥ 好算, ∥∥A−1∥∥ 不好算,其实就相当于估计 ∥∥A−1∥∥ 怎么估计?参考补充内容的pdf和其中的两个hw。
参考附录
1: CS229 lecture11 - Regularization
2: CS273a lecture - Linear regression (6) Regularization
3: http://blog.csdn.net/zouxy09/article/details/24971995/
4: 李航博士《统计学习方法》1.5节关于正则化部分内容
5: http://blog.csdn.net/u012162613/article/details/44261657
6: http://blog.csdn.net/gshgsh1228/article/details/52199870
7: http://cseweb.ucsd.edu/~saul/teaching/cse291s07/L1norm.pdf
8: https://www.quora.com/What-is-the-difference-between-L1-and-L2-regularization
9: http://stats.stackexchange.com/questions/45643/why-l1-norm-for-sparse-models
10: 数据与算法-数值计算基本概念
http://wenku.baidu.com/link?url=jtp5RX3cVdbzkJnm_e5HJ4wxJRLRe7gNVjE_Ph7j4A4X2zuhswrPwOvtrVlFm3Qu3t3Nu2ZDlYtPh2nad3xCtJOe5n9GbmKM1cFac4O-rhO
11: https://www.zhihu.com/question/37096933
12: https://www.zhihu.com/question/20700829
补充内容
1: https://www.encyclopediaofmath.org/index.php/Condition_number
2: http://www.cse.iitd.ernet.in/~dheerajb/CS210_lect07.pdf
3: http://www.cse.iitd.ernet.in/~dheerajb/CS210_lect08.pdf
4: http://www.math.iup.edu/~jchrispe/MATH_640/Fall2015/Homework2.pdf MATH 640 hw2
5: http://www.ams.sunysb.edu/~jiao/teaching/ams526/HW/hw2.pdf AMS 526 Homework 2
转载请注明出处: http://blog.csdn.net/fightsong/article/details/53311582