Sharding-Sphere:SpringBoot 2 读写分离、水平分表结合Druid,分库分表-基础篇
前提:
MySQL 主从复制
Maven坐标
io.shardingsphere
sharding-jdbc-spring-boot-starter
3.1.0
io.shardingsphere
sharding-jdbc-spring-namespace
3.1.0
读写分离
# 配置真实数据源
sharding.jdbc.datasource.names=master1,slave0
# 主数据库
sharding.jdbc.datasource.master1.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.master1.hikari.driver-class-name=com.mysql.cj.jdbc.Driver
sharding.jdbc.datasource.master1.jdbc-url=jdbc:mysql://192.168.0.3:3306/ds0?characterEncoding=utf-8&autoReconnect=true&serverTimezone=Asia/Shanghai
sharding.jdbc.datasource.master1.username=test
sharding.jdbc.datasource.master1.password=12root
# 从数据库
sharding.jdbc.datasource.slave0.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.slave0.hikari.driver-class-name=com.mysql.cj.jdbc.Driver
sharding.jdbc.datasource.slave0.jdbc-url=jdbc:mysql://192.168.0.3:3306/ds0?characterEncoding=utf-8&autoReconnect=true&serverTimezone=Asia/Shanghai
sharding.jdbc.datasource.slave0.username=test
sharding.jdbc.datasource.slave0.password=12root
# 配置读写分离
# 配置从库选择策略,提供轮询与随机,这里选择用轮询
sharding.jdbc.config.masterslave.load-balance-algorithm-type=round_robin
sharding.jdbc.config.masterslave.name=ms
sharding.jdbc.config.masterslave.master-data-source-name=master1
sharding.jdbc.config.masterslave.slave-data-source-names=slave0
# 开启SQL显示,默认值: false,注意:仅配置读写分离时不会打印日志
sharding.jdbc.config.props.sql.show=true
spring.main.allow-bean-definition-overriding=true读写分离&水平分表&Druid
# ++++++++++++++++++ shardingsphere【START】 ++++++++++++++++++
# 配置数据源 分别是 主数据库1个 从数据库1个
sharding.jdbc.datasource.names=master0,master0slave0
# 主第一个数据库
sharding.jdbc.datasource.master0.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.master0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master0.url=jdbc:mysql://192.168.2.156:3306/sdkcms?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowMultiQueries=true
sharding.jdbc.datasource.master0.username=root
sharding.jdbc.datasource.master0.password=XXXX
# 从第一个数据库
sharding.jdbc.datasource.master0slave0.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.master0slave0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master0slave0.url=jdbc:mysql://192.168.2.157:3306/sdkcms?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowMultiQueries=true
sharding.jdbc.datasource.master0slave0.username=root
sharding.jdbc.datasource.master0slave0.password=XXXX
# 读写分离配置
# 从库的读取规则为round_robin(轮询策略),除了轮询策略,还有支持random(随机策略)
sharding.jdbc.config.masterslave.load-balance-algorithm-type=round_robin
# 逻辑主从库名和实际主从库映射关系
# 主数据库0
sharding.jdbc.config.sharding.master-slave-rules.sdkcms.master-data-source-name=master0
# 从数据库0
sharding.jdbc.config.sharding.master-slave-rules.sdkcms.slave-data-source-names=master0slave0
# 水平分表配置--自定义【START】
# 白名单用户
# 分表策略 其中uvip_user_class为逻辑表 分表主要取决于org_id行
sharding.jdbc.config.sharding.tables.vip_user_class.actual-data-nodes=sdkcms.vip_user_class_$->{0..2}
sharding.jdbc.config.sharding.tables.vip_user_class.table-strategy.inline.sharding-column=org_id
# 分片算法表达式
sharding.jdbc.config.sharding.tables.vip_user_class.table-strategy.inline.algorithm-expression=vip_user_class_$->{org_id %3}
# 水平分表配置--自定义【END】
# 打印操作的sql以及库表数据等
# 开启SQL显示,默认值: false,注意:仅配置读写分离时不会打印日志
sharding.jdbc.config.props.sql.show=true
分库分表
# 数据源 ds0,ds1
sharding.jdbc.datasource.names=ds0,ds1
# 第一个数据库
sharding.jdbc.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds0.jdbc-url=jdbc:mysql://localhost:3306/ds0?characterEncoding=utf-8
sharding.jdbc.datasource.ds0.username=root
sharding.jdbc.datasource.ds0.password=root
# 第二个数据库
sharding.jdbc.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds1.jdbc-url=jdbc:mysql://localhost:3306/ds1?characterEncoding=utf-8
sharding.jdbc.datasource.ds1.username=root
sharding.jdbc.datasource.ds1.password=root
# 水平拆分的数据库(表) 配置分库 + 分表策略 行表达式分片策略
# 分库策略
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=ds$->{id % 2}
# 分表策略 其中user为逻辑表 分表主要取决于age行
sharding.jdbc.config.sharding.tables.user.actual-data-nodes=ds$->{0..1}.user_$->{0..1}
sharding.jdbc.config.sharding.tables.user.table-strategy.inline.sharding-column=age
# 分片算法表达式
sharding.jdbc.config.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{age % 2}
# 主键 UUID 18位数 如果是分布式还要进行一个设置 防止主键重复
#sharding.jdbc.config.sharding.tables.user.key-generator-column-name=id
# 打印执行的数据库以及语句
sharding.jdbc.config.props..sql.show=true
spring.main.allow-bean-definition-overriding=true读写分离&分库分表
# 可以看到配置四个数据源 分别是 主数据库两个 从数据库两个
sharding.jdbc.datasource.names=master0,master1,master0slave0,master1slave0
# 主第一个数据库
sharding.jdbc.datasource.master0.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.master0.hikari.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master0.jdbc-url=jdbc:mysql://192.168.0.4:3306/ds0?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
sharding.jdbc.datasource.master0.username=test
sharding.jdbc.datasource.master0.password=12root
# 主第二个数据库
sharding.jdbc.datasource.master1.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.master1.hikari.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master1.jdbc-url=jdbc:mysql://192.168.0.4:3306/ds1?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
sharding.jdbc.datasource.master1.username=test
sharding.jdbc.datasource.master1.password=12root
# 从第一个数据库
sharding.jdbc.datasource.master0slave0.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.master0slave0.hikari.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master0slave0.jdbc-url=jdbc:mysql://192.168.0.3:3306/ds0?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
sharding.jdbc.datasource.master0slave0.username=test
sharding.jdbc.datasource.master0slave0.password=12root
# 从第一个数据库
sharding.jdbc.datasource.master1slave0.type=com.zaxxer.hikari.HikariDataSource
sharding.jdbc.datasource.master1slave0.hikari.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.master1slave0.jdbc-url=jdbc:mysql://192.168.0.3:3306/ds1?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
sharding.jdbc.datasource.master1slave0.username=test
sharding.jdbc.datasource.master1slave0.password=12root
# 读写分离配置
# 从库的读取规则为round_robin(轮询策略),除了轮询策略,还有支持random(随机策略)
sharding.jdbc.config.masterslave.load-balance-algorithm-type=round_robin
# 逻辑主从库名和实际主从库映射关系
# 主数据库0
sharding.jdbc.config.sharding.master-slave-rules.ds0.master-data-source-name=master0
# 从数据库0
sharding.jdbc.config.sharding.master-slave-rules.ds0.slave-data-source-names=master0slave0
# 主数据库1
sharding.jdbc.config.sharding.master-slave-rules.ds1.master-data-source-name=master1
# 从数据库1
sharding.jdbc.config.sharding.master-slave-rules.ds1.slave-data-source-names=master1slave0
# 分库分表配置
# 水平拆分的数据库(表) 配置分库 + 分表策略 行表达式分片策略
# 分库策略
sharding.jdbc.config.sharding.default-database-strategy.inline.sharding-column=id
sharding.jdbc.config.sharding.default-database-strategy.inline.algorithm-expression=ds$->{id %2}
# 分表策略 其中user为逻辑表 分表主要取决于age行
sharding.jdbc.config.sharding.tables.user.actual-data-nodes=ds$->{0..1}.user_$->{0..1}
sharding.jdbc.config.sharding.tables.user.table-strategy.inline.sharding-column=age
# 分片算法表达式
sharding.jdbc.config.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{age %2}
# 主键 UUID 18位数 如果是分布式还要进行一个设置 防止主键重复
#sharding.jdbc.config.sharding.tables.user.key-generator-column-name=id
# 打印操作的sql以及库表数据等
sharding.jdbc.config.props.sql.show=true
spring.main.allow-bean-definition-overriding=true问题
1. 无法知道走的到底是哪个数据源
相信大家也发现了,当读写分离和分库分表集成时
虽然我们配置sql.show=true
但是控制台最终打印不出所执行的数据源是哪个
不知道是从库还是主库
2.读写分离实现
读写分离的流程
获取主从库配置规则,数据源封装成MasterSlaveDataSource
根据ShardingMasterSlaveRouter路由计算,
得到sqlRouteResult.getRouteUnits()单元列表,
然后将结果addAll添加并返回
执行每个RouteUnits的时候需要获取连接,
这里根据轮询负载均衡算法RoundRobinMasterSlaveLoadBalanceAlgorithm得到从库数据源
拿到连接后就开始执行具体的SQL查询了,这里通过PreparedStatementHandler.execute()得到执行结果
结果归并后返回
- MasterSlaveDataSource.class
package io.shardingsphere.shardingjdbc.jdbc.core.datasource;
import io.shardingsphere.api.ConfigMapContext;
import io.shardingsphere.api.config.rule.MasterSlaveRuleConfiguration;
import io.shardingsphere.core.constant.properties.ShardingProperties;
import io.shardingsphere.core.rule.MasterSlaveRule;
import io.shardingsphere.shardingjdbc.jdbc.adapter.AbstractDataSourceAdapter;
import io.shardingsphere.shardingjdbc.jdbc.core.connection.MasterSlaveConnection;
import io.shardingsphere.transaction.api.TransactionTypeHolder;
import java.sql.Connection;
import java.sql.DatabaseMetaData;
import java.sql.SQLException;
import java.util.Map;
import java.util.Properties;
import javax.sql.DataSource;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MasterSlaveDataSource extends AbstractDataSourceAdapter {
private static final Logger log = LoggerFactory.getLogger(MasterSlaveDataSource.class);
private final DatabaseMetaData databaseMetaData;
private final MasterSlaveRule masterSlaveRule;
private final ShardingProperties shardingProperties;
public MasterSlaveDataSource(Map dataSourceMap, MasterSlaveRuleConfiguration masterSlaveRuleConfig, Map configMap, Properties props) throws SQLException {
super(dataSourceMap);
this.databaseMetaData = this.getDatabaseMetaData(dataSourceMap);
if (!configMap.isEmpty()) {
ConfigMapContext.getInstance().getConfigMap().putAll(configMap);
}
this.masterSlaveRule = new MasterSlaveRule(masterSlaveRuleConfig);
// 从配置文件获取配置的主从数据源
this.shardingProperties = new ShardingProperties(null == props ? new Properties() : props);
}
// 获取主从配置关系
public MasterSlaveDataSource(Map dataSourceMap, MasterSlaveRule masterSlaveRule, Map configMap, Properties props) throws SQLException {
super(dataSourceMap);
this.databaseMetaData = this.getDatabaseMetaData(dataSourceMap);
if (!configMap.isEmpty()) {
ConfigMapContext.getInstance().getConfigMap().putAll(configMap);
}
this.masterSlaveRule = masterSlaveRule;
this.shardingProperties = new ShardingProperties(null == props ? new Properties() : props);
}
// 获取数据库元数据
private DatabaseMetaData getDatabaseMetaData(Map dataSourceMap) throws SQLException {
Connection connection = ((DataSource)dataSourceMap.values().iterator().next()).getConnection();
Throwable var3 = null;
DatabaseMetaData var4;
try {
var4 = connection.getMetaData();
} catch (Throwable var13) {
var3 = var13;
throw var13;
} finally {
if (connection != null) {
if (var3 != null) {
try {
connection.close();
} catch (Throwable var12) {
var3.addSuppressed(var12);
}
} else {
connection.close();
}
}
}
return var4;
}
public final MasterSlaveConnection getConnection() {
return new MasterSlaveConnection(this, this.getShardingTransactionalDataSources().getDataSourceMap(), TransactionTypeHolder.get());
}
public DatabaseMetaData getDatabaseMetaData() {
return this.databaseMetaData;
}
public MasterSlaveRule getMasterSlaveRule() {
return this.masterSlaveRule;
}
public ShardingProperties getShardingProperties() {
return this.shardingProperties;
}
}
配置文件配置的主从规则
- MasterSlaveRule.class
package io.shardingsphere.core.rule;
import com.google.common.base.Preconditions;
import io.shardingsphere.api.algorithm.masterslave.MasterSlaveLoadBalanceAlgorithm;
import io.shardingsphere.api.algorithm.masterslave.MasterSlaveLoadBalanceAlgorithmType;
import io.shardingsphere.api.config.rule.MasterSlaveRuleConfiguration;
import java.util.Collection;
public class MasterSlaveRule {
//名称(这里是ds0和ds1)
private final String name;
//主库数据源名称(这里是ds_master_0和ds_master_1)
private final String masterDataSourceName;
//所属从库列表,key为从库数据源名称,value是真实的数据源
private final Collection slaveDataSourceNames;
//主从库负载均衡算法
private final MasterSlaveLoadBalanceAlgorithm loadBalanceAlgorithm;
//主从库路由配置
private final MasterSlaveRuleConfiguration masterSlaveRuleConfiguration;
轮询负载均衡算算法
- RoundRobinMasterSlaveLoadBalanceAlgorithm.class
package io.shardingsphere.api.algorithm.masterslave;
import java.util.List;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicInteger;
//轮询负载均衡策略,按照每个从节点访问次数均衡
public final class RoundRobinMasterSlaveLoadBalanceAlgorithm implements MasterSlaveLoadBalanceAlgorithm {
private static final ConcurrentHashMap COUNT_MAP = new ConcurrentHashMap();
public RoundRobinMasterSlaveLoadBalanceAlgorithm() {
}
public String getDataSource(String name, String masterDataSourceName, List slaveDataSourceNames) {
AtomicInteger count = COUNT_MAP.containsKey(name) ? (AtomicInteger)COUNT_MAP.get(name) : new AtomicInteger(0);
COUNT_MAP.putIfAbsent(name, count);
count.compareAndSet(slaveDataSourceNames.size(), 0);
return (String)slaveDataSourceNames.get(Math.abs(count.getAndIncrement()) % slaveDataSourceNames.size());
}
}
- ShardingMasterSlaveRouter.class
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package io.shardingsphere.core.routing.router.masterslave;
import io.shardingsphere.core.constant.SQLType;
import io.shardingsphere.core.hint.HintManagerHolder;
import io.shardingsphere.core.routing.RouteUnit;
import io.shardingsphere.core.routing.SQLRouteResult;
import io.shardingsphere.core.rule.MasterSlaveRule;
import java.beans.ConstructorProperties;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
import java.util.LinkedList;
public final class ShardingMasterSlaveRouter {
private final Collection masterSlaveRules;
// 得到最终的sql路由
public SQLRouteResult route(SQLRouteResult sqlRouteResult) {
Iterator var2 = this.masterSlaveRules.iterator();
while(var2.hasNext()) {
MasterSlaveRule each = (MasterSlaveRule)var2.next();
this.route(each, sqlRouteResult);
}
return sqlRouteResult;
}
//进行计算筛选得到最终sql路由
private void route(MasterSlaveRule masterSlaveRule, SQLRouteResult sqlRouteResult) {
Collection toBeRemoved = new LinkedList();
Collection toBeAdded = new LinkedList();
Iterator var5 = sqlRouteResult.getRouteUnits().iterator();
while(var5.hasNext()) {
RouteUnit each = (RouteUnit)var5.next();
if (masterSlaveRule.getName().equalsIgnoreCase(each.getDataSourceName())) {
toBeRemoved.add(each);
if (this.isMasterRoute(sqlRouteResult.getSqlStatement().getType())) {
MasterVisitedManager.setMasterVisited();
toBeAdded.add(new RouteUnit(masterSlaveRule.getMasterDataSourceName(), each.getSqlUnit()));
} else {
toBeAdded.add(new RouteUnit(masterSlaveRule.getLoadBalanceAlgorithm().getDataSource(masterSlaveRule.getName(), masterSlaveRule.getMasterDataSourceName(), new ArrayList(masterSlaveRule.getSlaveDataSourceNames())), each.getSqlUnit()));
}
}
}
//路由移除(查询时 移除所有主库)
sqlRouteResult.getRouteUnits().removeAll(toBeRemoved);
//添加从库/主库 具体事件定
sqlRouteResult.getRouteUnits().addAll(toBeAdded);
}
// 判断是不是主库
private boolean isMasterRoute(SQLType sqlType) {
return SQLType.DQL != sqlType || MasterVisitedManager.isMasterVisited() || HintManagerHolder.isMasterRouteOnly();
}
@ConstructorProperties({"masterSlaveRules"})
public ShardingMasterSlaveRouter(Collection masterSlaveRules) {
this.masterSlaveRules = masterSlaveRules;
}
}
- 注: 判断是不是主库的规则为:
private boolean isMasterRoute(SQLType sqlType) {
return SQLType.DQL != sqlType || MasterVisitedManager.isMasterVisited() || HintManagerHolder.isMasterRouteOnly();
}
SQL语言的判断
SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。
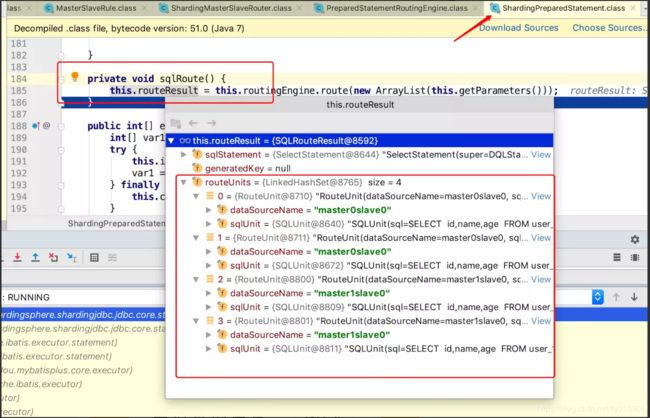
通过断点,查询全部数据时最终的sql路由为
参考链接:https://mp.weixin.qq.com/s?timestamp=1561336330&src=3&ver=1&signature=*9kjZ313jAi7n3pMci6zgk1XNP7ok5C*vnn0I-o6QlOK0ZuYK-40N5S-4f7eiIx3tU75DtzUcqs28QwCZHxrPjtiz-dPXS-6H3OhW0WoDaZjN6RS7tYyX3FX1ibPRBKOo91zcUHp1HsibOH1OGB9u0P2IRHRQQns*W5ARh40pWw=