Python爬虫实战:糗事百科
前面我们已经说了那么多基础知识了,下面我们做个实战项目来挑战一下吧。这次就用前面学的urllib和正则表达式来做,Python爬虫爬取糗事百科的小段子。
爬取前我们先看一下我们的目标:
1.抓取糗事百科热门段子
2.过滤带有图片的段子
3.段子的发布人,段子内容,好笑数,评论数
1.确定URL并抓取页面代码
首先我们确定好页面的URL,糗事百科的网址是:http://www.qiushibaike.com,但是这个URL不方便我们后面连续抓取,我们可以看一下第二页就知道URL如何构造了,URL是 http://www.qiushibaike.com/8hr/page/1/?s=4872200,其中中间的数字1代表页数,我们可以传入不同的值来获得某一页的段子内容,其他的部分是不变的。
我们先看看最基本的页面抓取方式,看看会不会成功
import urllib2
page=1
url = 'http://www.qiushibaike.com/8hr/page/'+str(page)+'/?s=4872200'
try:
request = urllib2.Request(url)
response = urllib2.urlopen(request)
print response.read()
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason结果出现 raise BadStatusLine(line) httplib.BadStatusLine: '',我们需要加上headers验证,如下:
import urllib2
page=1
url = 'http://www.qiushibaike.com/8hr/page/'+str(page)+'/?s=4872200'
user_agent ='Mozilla/4.0(compatible;MSIE 5.5;Windows NT)'
headers={'User-Agent':user_agent}
try:
request = urllib2.Request(url,headers = headers)
response = urllib2.urlopen(request)
print response.read()
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason2、用正则表达式提取段子
我们先看审查元素,看一下代码,如下图:
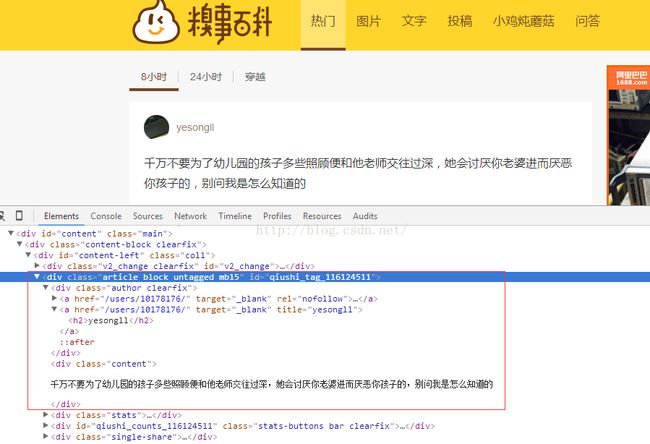
现在我们需要
段子的发布人,段子内容,好笑数,评论数,用正则表达式匹配如下:
content = response.read().decode('utf-8')
pattern = re.compile('.*?.*?.*?.*?(.*?)
.*?content">'+
'(.*?) .*?vote".*?number">(.*?).*?stats-comments".*?(.*?)',re.S)
items = re.findall(pattern,content)
for item in items :
print item[0],item[1],item[2],item[3]
看一下爬出来的段子:
看一下爬出来的段子:
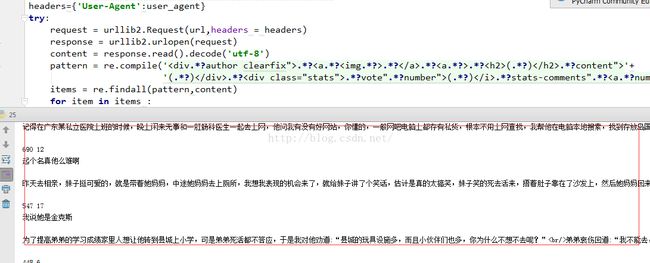
好啦下面我们把代码完整的留下,加了一个小循环,爬取10页:
# _*_ coding:utf-8 _*_
import urllib2
import re
page=1
print u"第%d页"%page
while page < 10:
url = 'http://www.qiushibaike.com/8hr/page/' + str(page) + '/?s=4872200'
user_agent ='Mozilla/4.0(compatible;MSIE 5.5;Windows NT)'
headers={'User-Agent':user_agent}
try:
request = urllib2.Request(url,headers = headers)
response = urllib2.urlopen(request)
content = response.read().decode('utf-8')
pattern = re.compile('.*?.*?.*?.*?(.*?)
.*?content">' +
'(.*?) .*?vote".*?number">(.*?).*?stats-comments".*?(.*?)',re.S)
items = re.findall(pattern,content)
for item in items :
print item[0],item[1],item[2],item[3]
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
page = page + 1
print u"第%d页"%page
好啦,代码比较糙,大家可以自己试试!
好啦,代码比较糙,大家可以自己试试!