人工智能(1)用tensorflow识别MNIST手写数字数据集
基于TensorFlow的MNIST数据集识别实验
1. Softmax逻辑回归算法
l 模型公式:pred = softmax(W·x+b)
l 损失函数:交叉熵
模型中softmax函数将evidence=W·x+b的结果控制在0-1之间且每个结果类的pred值之和为1。

l Python源码:
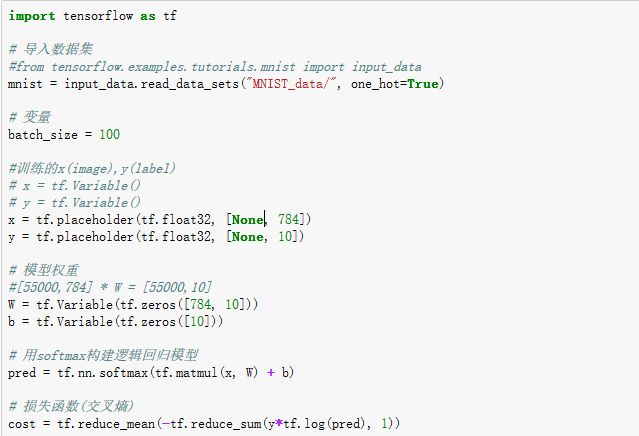
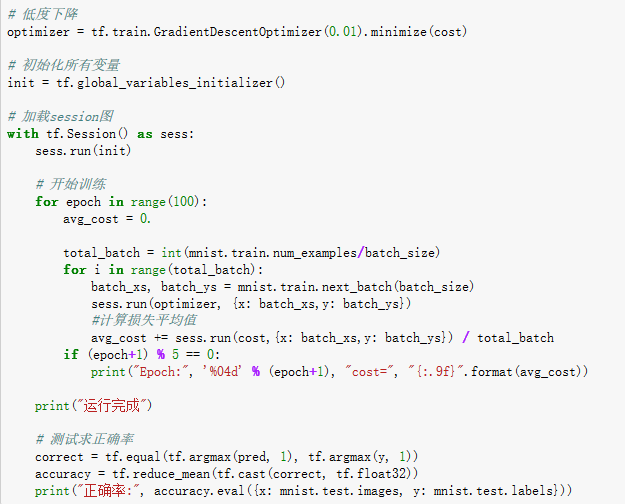
运行结果:
可以看出随着迭代次数的增加,平均损失的降低,以及最终在测试集上的准确率。

2. 人工神经网络算法
l 模型公式: pred=softmax(sigmoid(W1·x)·W2)
l 损失函数:交叉熵
l Python源码:
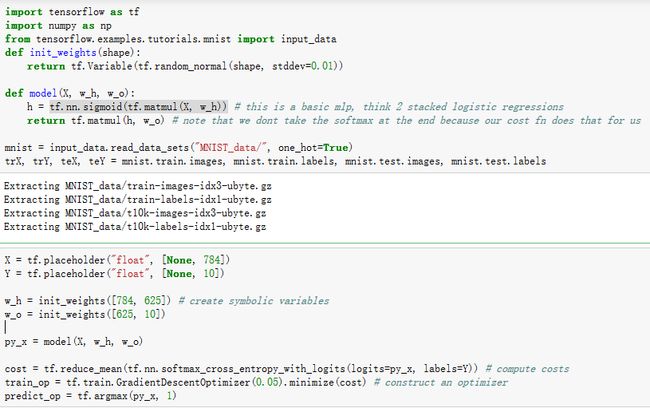
3. 卷积神经网络算法
卷积神经网络与普通神经网络的区别在于,卷积神经网络包含了一个由卷积层和池化层构成的特征抽取器。在卷积神经网络的卷积层中,一个神经元只与部分邻层神经元连接。在CNN的一个卷积层中,通常包含若干个特征平面(featureMap),每个特征平面由一些矩形排列的的神经元组成,同一特征平面的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。子采样也叫做池化(pooling),通常有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。子采样可以看作一种特殊的卷积过程。卷积和子采样大大简化了模型复杂度,减少了模型的参数。
l 重要函数:
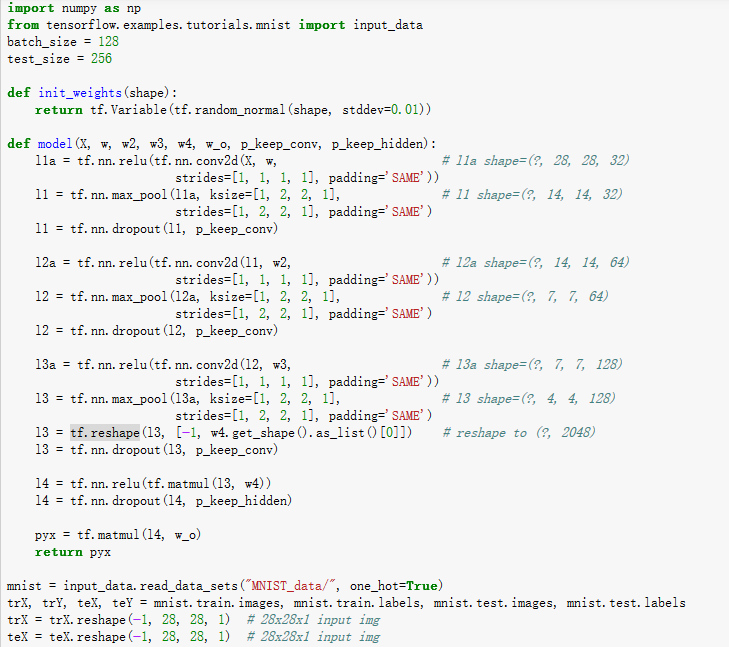
1. tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None,name=None)
除去name参数用以指定该操作的name,与方法有关的一共五个参数:
第一个参数input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width,in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一。
第二个参数filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width,in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维。
第三个参数strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4。
第四个参数padding:string类型的量,只能是"SAME","VALID"其中之一,这个值决定了不同的卷积方式(后面会介绍)。
第五个参数:use_cudnn_on_gpu:bool类型,是否使用cudnn加速,默认为true。
结果返回一个Tensor,这个输出,就是我们常说的feature map
2. tf.nn.max_pool(value, ksize, strides, padding, name=None)
参数是四个,和卷积很类似:
第一个参数value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch, height, width,channels]这样的shape。
第二个参数ksize:池化窗口的大小,取一个四维向量,一般是[1, height, width, 1],因为我们不想在batch和channels上做池化,所以这两个维度设为了1。
第三个参数strides:和卷积类似,窗口在每一个维度上滑动的步长,一般也是[1, stride,stride, 1]。
第四个参数padding:和卷积类似,可以取'VALID' 或者'SAME'。
返回一个Tensor,类型不变,shape仍然是[batch, height, width, channels]这种形式。
3. tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None,name=None)
tf.nn.dropout是TensorFlow里面为了防止或减轻过拟合而使用的函数,它一般用在全连接层。
Dropout就是在不同的训练过程中随机扔掉一部分神经元。也就是让某个神经元的激活值以一定的概率p,让其停止工作,这次训练过程中不更新权值,也不参加神经网络的计算。但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了。
上面方法中常用的是前两个参数:
第一个参数x:指输入
第二个参数keep_prob: 设置神经元被选中的概率,在初始化时keep_prob是一个占位符, keep_prob =tf.placeholder(tf.float32) 。tensorflow在run时设置keep_prob具体的值,例如keep_prob: 0.5
4. tf.nn.relu(features, name = None)
这个函数的作用是计算激活函数relu,即max(features, 0)。
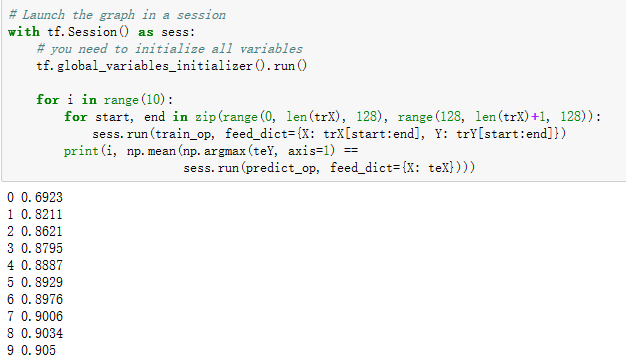
l Python源码:

l 运行结果:

4. 问题探讨:
l 常用的激活函数
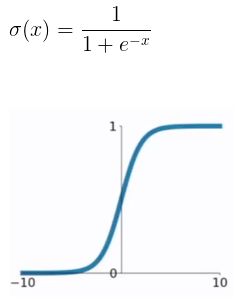
(1) sigmod
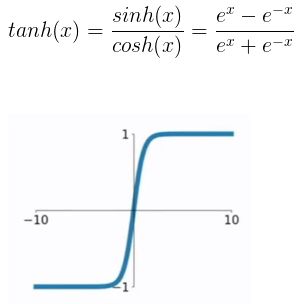
(2) tanh函数
(3) ReLU函数

(4) PReLU函数

l 用数学方程描述感知器模型,用到的多层神经网络模型
感知器使用特征向量来表示的前馈式人工神经网络,它是一种二元分类器,把矩阵上的输入(实数值向量)映射到输出值f(x)上(一个二元的值)。
数学表达式:
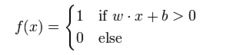
b是一个不依赖于任何输入值的常数,可以认为是激励函数的偏移量,或者给神经元一个基础活跃等级。
实验中所用到的“感知机串接1层隐含层1个非线性激活函数”就是感知机外各自串接一个激活函数,再由全连接的隐含层的输出串接一个激活函数,得到模型输出。
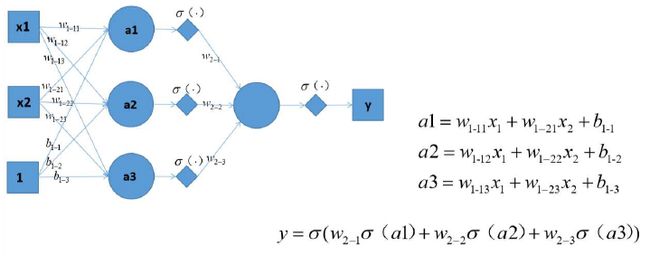
l 简述卷积神经网络要素:卷积核,滤波器,池化,特征图
卷积神经网络包含了一个由卷积层和池化层构成的特征抽取器。在卷积神经网络的卷积层中,一个神经元只与部分邻层神经元连接。在CNN的一个卷积层中,通常包含若干个特征平面(featureMap),每个特征平面由一些矩形排列的的神经元组成,同一特征平面的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。子采样也叫做池化(pooling),通常有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。子采样可以看作一种特殊的卷积过程。卷积和子采样大大简化了模型复杂度,减少了模型的参数。
l 找不到tensorboard模块:
在使用tensorboard进行模型训练过程可视化的过程中,出现“找不到tensorboard”模块的解决方法是单独利用“pip install tensorboard”进行安装,跟Tensorflow一起安装可能会造成这个问题。
l Jupyterkernel切换:
# 安装 ipykernel 模块
(tensorflow0330)> pip install ipykernel
# 将自己环境添加到 ipython 的kernel 里
(tensorflow0330)> python -m ipykernel install --user --nametensorflow0330(你的环境名)`
--display-name "tensorflow0330"(你kernel 的名字,可以在 jupyter 中看到,可以和环境名不一样)
l 隐含层神经元个数如何确定:
在人工网络算法的实验中,我发现隐含层的神经元个数被定为625,这是根据输入(784个感知机)和输出(10个类别)而人为制定的。
查阅相关资料发现,BP神经网络中隐含层的神经元数并没有一个明确的确定方法,有时,是凭个人经验或者调试所得。常见的方法有以下几种:
1)一般取(输入层个数+输出层个数)/2;
2)(输入层个数*输出层个数)^(1/2);
3)隐含层<输入层即可;
4)[(输入+1)/2 (输入-1)];
5)log(输入)
6)2*输入+1