强化学习笔记(3)之动态规划法
价值函数的解析解
上一篇文章的马尔科夫过程是强化的学习的理论基础,其中引入了状态价值函数与状态-行为价值函数来对行为策略的评估。补充一下上一篇文章的知识。最优状态价值函数:即在当前状态下,可能发生的所有后续动作,挑选最好的动作来执行的情况下,当前这个状态的价值。
最优状态行为值函数:即在当前状态下执行了特定的行为,然后考虑到执行这个行为后所有可能所处的后续状态并且在这些状态下总是挑选最好的动作来执行得到的长期价值。
有上一篇文章所举出的,Bellman(贝尔曼)方程
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) = ∑ a ∈ A π ( a ∣ s ) ( R s a + γ ∑ s ′ ∈ S P s s ′ a v π ( s ′ ) ) v_{\pi}(s)=\sum_{a\in A} \pi (a|s)q_{\pi}(s,a)=\sum_{a\in A} \pi (a|s)(R_s^a + \gamma \sum _{s'\in S}P_{ss'}^av_{\pi}(s')) vπ(s)=∑a∈Aπ(a∣s)qπ(s,a)=∑a∈Aπ(a∣s)(Rsa+γ∑s′∈SPss′avπ(s′))
设 V π V_{\pi} Vπ 为在 π \pi π策略下的所有状态空间,忽略策略的随机性,Bellman方程可以表示成:
V π = R π + γ P π V π V_{\pi}=R^{\pi}+\gamma P^{\pi}V_{\pi} Vπ=Rπ+γPπVπ
直接求解,得:
V π = ( 1 − γ P π ) − 1 R π V_{\pi}=(1-\gamma P^{\pi})^{-1}R^{\pi} Vπ=(1−γPπ)−1Rπ
所以Bellman方程的复杂度为 O ( n 3 ) O(n^3) O(n3),而且在真实的场景当中, P π P^{\pi} Pπ和 R π R^{\pi} Rπ的规模都非常大,很难直接求解出解析解。
迭代法求解价值函数
常用的价值函数的计算方式都是迭代进行的。
动态规划法: 已知环境模型 P P P和 R R R,每步迭代进行。(但是,在显示应用中,几乎很难获知环境模型的 P P P和 R R R,所以很少会用动态规划法来解决大规模的强化学习问题)。
蒙特卡洛法(Monte Carlo): 没有环境模型,根据经验学习。但是要求任务必须有终点,在任务结束后对所有回报值的进行平均。
时序差分法:没有模型,根据经验学习。每步或者固定有限步数进行迭代,不要求等待任务结束。
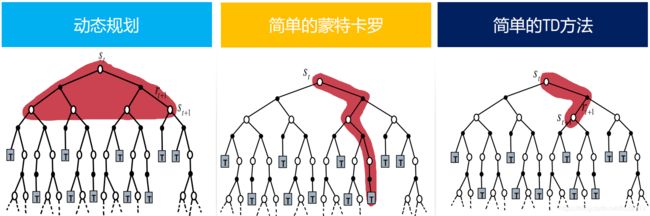
动态规划法
先从一个例子中学习动态规划方法:小明要爬一座有10级台阶的楼梯,由于腿短,每一只能上一级台阶或者2级台阶,问小明从0级台阶爬到楼上有多少种爬法?(如:第1种每一步上一级阶梯:1,1,1,1,1,1,1,1,1,1;第2种每一步上两级阶梯:2,2,2,2,2:第N种:…)
假设10级阶梯有 f ( 10 ) f(10) f(10)种走法,我们把楼梯问题拆分,小明迈出了第一步:两种可能:1.一步只上了一级,剩下还有 f ( 9 ) f(9) f(9)种可能走法;2.第一步上了两级,剩下没走的还有 f ( 8 ) f(8) f(8)种走法,所以 f ( 10 ) = f ( 9 ) + f ( 8 ) f(10)=f(9)+f(8) f(10)=f(9)+f(8), f ( 9 ) = f ( 8 ) + f ( 7 ) f(9)=f(8)+f(7) f(9)=f(8)+f(7)… f ( 3 ) = f ( 2 ) + f ( 1 ) f(3)=f(2)+f(1) f(3)=f(2)+f(1), f ( 2 ) = 2 f(2)=2 f(2)=2, f ( 1 ) = 1 f(1)=1 f(1)=1。演绎出: f ( n ) = f ( n − 1 ) + f ( n − 2 ) f(n)=f(n-1)+f(n-2) f(n)=f(n−1)+f(n−2)
(这都是个小学的例子,拿出来糊弄一下小学生)
这就是一个动态规划的过程:把复杂的问题分阶段进行化简,逐步化简成简单的问题。动态规划是一种求解决策问题的一种数学思想。动态规划的求解过程是迭代进行的,每一次迭代的过程中,只需保留前一种或者前有限种状态,就可以推导出新的状态。不需要像备忘录那样保留全部子状态,实现时间和空间上的最优化。
字面上解析动态规划,“动态”指的是问题存在时间序列上贯序性,“规划”是指问题优化的一个计划,一种策略。
但是,并不是所有问题都能用动态规划求解的,动态规划问题需要待解决的问题包含两个性质:
1.最优子结构:保证问题存在最优性准则,从而问题的最优解可以分解成子问题的最优解;
2.重叠子问题:子问题重复出现,因而可以缓存并重用子问题的解。
最优子结构是依赖于特定问题和子问题的分割方式儿成立的条件。各子问题具有最优解,就能求出整个问题的最优解,此时条件成立。反之,如果不能利用子问题的最优解获得整个问题的最优解,那么这种问题不具备最优子结构。
动态规划的问题都是递归问题,假设当前决策结果 f [ n ] f[n] f[n],最优子结构就是让 f [ n − k ] f[n-k] f[n−k]最优,最优子结构就是能让转移到 n n n的状态是最优的。
所以一般动态规划的求解过程:
a)将问题分解为子问题;
b)求解子问题;
c)将子问题的解合并,求问题的解。
马尔科夫决策过程的求解
MDP(马尔科夫决策过程)正好满足动态规划问题的两个性质:
- 贝尔曼方程给出了问题的迭代分解,
- 价值函数的保存和重用问题的解。
所以可以用动态规划来求解MDP规划问题,但是,必须明确环境模型是已知的,也就是模型的状态转移矩阵 P P P已知。
强化学习的目的就是找到最优策略,即MDP的最优解。
求解强化学习的过程一般分为两个步骤:
- 预测:给定策略,评估相应状态的价值函数或者状态-行为价值函数。
- 控制:状态价值函数或者状态-行为价值函数求得之后,就可以得到当前状态的最优动作。
| 状态价值 | 状态-行为价值 | |
|---|---|---|
| 预测 | V π V_{\pi} Vπ | q π q_{\pi} qπ |
| 控制 | V ∗ V_* V∗ | q ∗ q_* q∗ |
迭代的应用Bellman期望方程:在每一次迭代的过程中,对第 k + 1 k+1 k+1次迭代,所有的状态 s s s的价值都用 v k ( s ′ ) v_k(s') vk(s′)来计算(本轮次本状态的计算依据来源于上一次计算的结果),并更新该状态第 k + 1 k+1 k+1迭代中使用的价值 v k ( s ) v_k(s) vk(s),其中 s ′ s' s′是状态 s s s的后继状态。
依照此方式反复迭代最终将收敛至 v π v_{\pi} vπ。数据公式为:
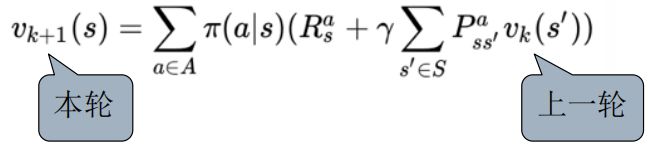
格子世界的例子:
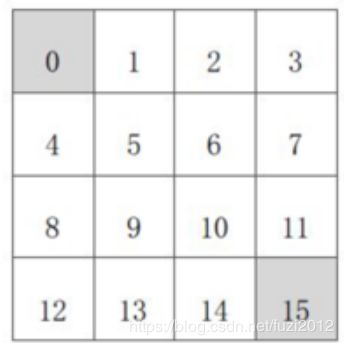
- 格子世界的状态空间 S S S: S 1 − S 14 S_1-S_{14} S1−S14为非终止终止状态, S T S_T ST为终止状态,即灰色方格显示的两个位置;
- 状态空间A:{n,e,s,w}(北,东,南,西)对于任何非终止状态可以有东南西北四种方向移动行为;
- 转移概率P:任何试图离开方格世界的动作其位置将不会发生改变,其余条件下将100%地转移到动作指向的状态;
- 即时奖励R:任何在非终止状态的转移得到的即时奖励均为-1,进入终止状态的即时奖励为0;
- 衰减系数 γ \gamma γ:1;
- 当前采取的行动策略:agent采用随机行动策略,在任何一个非终止状态下有均等的几率采取任一移动方向的行为;
即: π ( n ∣ ∗ ) = π ( e ∣ ∗ ) = π ( s ∣ ∗ ) = π ( w ∣ ∗ ) = 1 / 4 \pi (n|*)=\pi(e|*) =\pi(s|*)=\pi(w|*)=1/4 π(n∣∗)=π(e∣∗)=π(s∣∗)=π(w∣∗)=1/4 - 问题:求该方格世界在给定策略下的(状态)价值函数,也就是给定策略下,该方格世界每一个状态的价值。
按照公式: v π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) = ∑ a ∈ A π ( a ∣ s ) ( R s a + γ ∑ s ′ ∈ S P s s ′ a v π ( s ′ ) ) v_{\pi}(s)=\sum_{a\in A} \pi (a|s)q_{\pi}(s,a)=\sum_{a\in A} \pi (a|s)(R_s^a + \gamma \sum _{s'\in S}P_{ss'}^av_{\pi}(s')) vπ(s)=a∈A∑π(a∣s)qπ(s,a)=a∈A∑π(a∣s)(Rsa+γs′∈S∑Pss′avπ(s′))
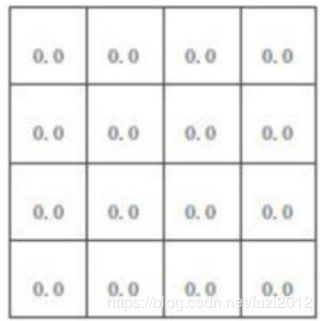
开始迭代: k = 0 k=0 k=0
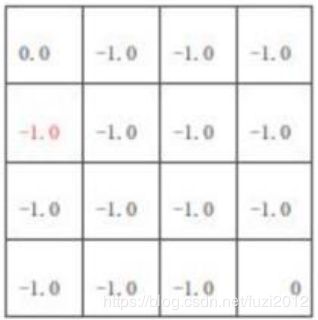
k = 1 k=1 k=1 :如图中红色的方格计算方式: − 1.0 = ( 1 / 4 ) ∗ ( − 1 + 1 ∗ 0 ) + ( 1 / 4 ) ( − 1 + 1 ∗ 0 ) + ( 1 / 4 ) ( − 1 + 1 ∗ 0 ) + ( 1 / 4 ) ( − 1 + 1 ∗ 0 ) -1.0=(1/4)*(-1+1*0)+(1/4)(-1+1*0)+(1/4)(-1+1*0)+(1/4)(-1+1*0) −1.0=(1/4)∗(−1+1∗0)+(1/4)(−1+1∗0)+(1/4)(−1+1∗0)+(1/4)(−1+1∗0)
(其中1/4 为策略 π \pi π,-1为立即奖励 R R R,1为转移概率P,0为上一轮侧的下一状态价值,对照上面的公式)
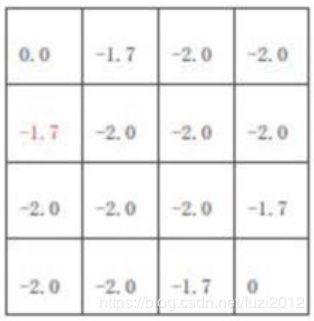
k = 2 k=2 k=2::图中红色的方格计算方式: − 1.7 = ( 1 / 4 ) ∗ ( − 1 + 1 ∗ 0 ) + ( 1 / 4 ) ( − 1 + 1 ∗ ( − 1 ) ) + ( 1 / 4 ) ( − 1 + 1 ∗ ( − 1 ) ) + ( 1 / 4 ) ( − 1 + 1 ∗ ( − 1 ) ) -1.7=(1/4)*(-1+1*0)+(1/4)(-1+1*(-1))+(1/4)(-1+1*(-1))+(1/4)(-1+1*(-1)) −1.7=(1/4)∗(−1+1∗0)+(1/4)(−1+1∗(−1))+(1/4)(−1+1∗(−1))+(1/4)(−1+1∗(−1))
k = 3 k=3 k=3:图中红色的方格计算方式: − 2.4 = ( 1 / 4 ) ∗ ( − 1 + 1 ∗ 0 ) + ( 1 / 4 ) ( − 1 + 1 ∗ ( − 2.0 ) ) + ( 1 / 4 ) ( − 1 + 1 ∗ ( − 2.0 ) ) + ( 1 / 4 ) ( − 1 + 1 ∗ ( − 1.7 ) ) -2.4=(1/4)*(-1+1*0)+(1/4)(-1+1*(-2.0))+(1/4)(-1+1*(-2.0))+(1/4)(-1+1*(-1.7)) −2.4=(1/4)∗(−1+1∗0)+(1/4)(−1+1∗(−2.0))+(1/4)(−1+1∗(−2.0))+(1/4)(−1+1∗(−1.7))
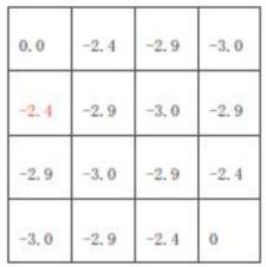
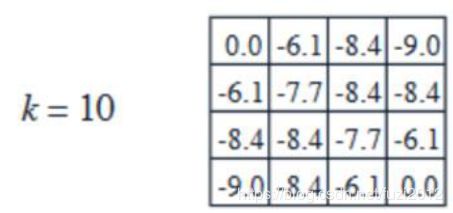
一直迭代下去,直到收敛;
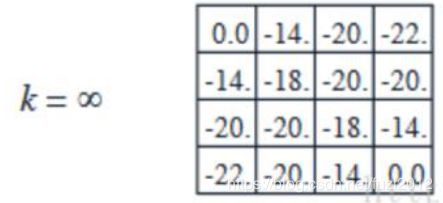
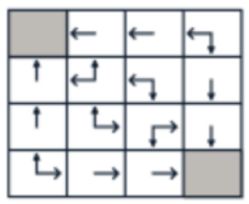
从中选择出最优策略:
最优解的计算方式:策略迭代,价值迭代
策略迭代(policy iteration) 算法通过构建值函数(切记,不是最优值函数)来评估策略,然后利用这些值函数,寻找新的、改进的策略。
值迭代(value iteration) 算法寻找最优质函数,最优值函数包括每个状态或者每个状态动作对的最大回报。最优值函数用来计算最优策略。
策略迭代(policy iteration)
通过格子世界的例子,得到了一个优化策略的办法,分为两步,一:在一个给定策略下迭代更新价值函数:
v π ( s ) = E [ R t + 1 + γ R t + 2 + . . . ∣ S t = s ] v_{\pi}(s)=E[R_{t+1}+\gamma R_{t+2}+...|S_t=s] vπ(s)=E[Rt+1+γRt+2+...∣St=s]
二:在当前策略的基础上,贪婪的选取行为,使得后继状态价值增加最多:
π ′ = g r e e d y ( v π ) \pi'=greedy(v_{\pi}) π′=greedy(vπ)
使用策略迭代算法,每次迭代分两步走:
第1步:先任意假设一个策略 π k \pi_k πk,使用这个策略迭代价值函数直到收敛;
V i + 1 π k ( s ) ← ∑ s ′ P ( s , π k ( s ) , s ′ ) [ R ( s , π k ( s ) , s ′ ) + γ π k V i π k ( s ′ ) ] V_{i+1}^{\pi _k}(s)\leftarrow \sum_{s'} P(s,\pi_k(s),s')[R(s,\pi_k(s),s') + \gamma {\pi _k}V_i^{\pi _k}(s')] Vi+1πk(s)←s′∑P(s,πk(s),s′)[R(s,πk(s),s′)+γπkViπk(s′)]
最后得到的 V ( s ) V(s) V(s)就是用策略 π k \pi_k πk下,能够得到的最好的价值函数 V ( s ) V(s) V(s)了。(其实,在策略 π k \pi_k πk下得到的做好的价值函数的值可以看做是当前这个策略 π k \pi_k πk的一种评估)
第2步:重新审视每个状态的所有可能的行为Action,优化策略 π k \pi_k πk检查是否有更优的行为Action代替老的Action,更新策略 π k + 1 \pi_{k+1} πk+1;
π k + 1 = a r g m a x a ∑ s ′ P ( s , a , s ′ ) [ R ( s , a , s ′ ) + γ V π k ( s ′ ) ] \pi_{k+1}=argmax_a\sum_{s'}P(s,a,s')[R(s,a,s')+\gamma V^{\pi_k}(s')] πk+1=argmaxas′∑P(s,a,s′)[R(s,a,s′)+γVπk(s′)]
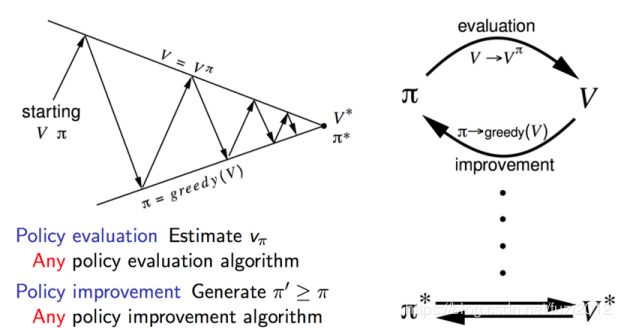
策略迭代的伪代码:

- initialization初始化左右状态 v ( s ) v(s) v(s)以及策略 π \pi π
- policy evaluation 用当前的 v ( s ) v(s) v(s)对当前策略进行评估,计算出每一个状态的 v ( s ) v(s) v(s),直到 v ( s ) v(s) v(s)收敛,这就计算好了在当前策略 π \pi π下的所有状态价值函数 v ( s ) v(s) v(s);
- policy improvement既然上一步已经得到了当前策略 π \pi π的评估函数 v ( s ) v(s) v(s),那么就可以利用这个评估函数进行策略改进。
- 在每个状态S时,对每个可能的动作a,都计算一下采取动作之后达到下一个状态的期望价值。看看那个动作可以到达的状态的期望价值函数最大,就选取这个动作作为下一策略的动作,以此更新了策略 π ( s ) \pi(s) π(s)
- 然后再次循环上述的2、3步骤,直到 v ( s ) v(s) v(s)以及策略 π \pi π都收敛。
价值迭代(value iteration)
最优状态价值函数 :最优值函数 V ∗ ( s ) V_*(s) V∗(s)是在从所有策略产生的状态价值函数中,选取使状态 s s s价值最大的函数:
v ∗ ( s ) = m a x π v π ( s ) v_*(s)=max_{\pi}v_{\pi}(s) v∗(s)=maxπvπ(s)
最优状态价值行为函数 : q ∗ ( s , a ) q_*(s,a) q∗(s,a)是从所有策略产生的行为价值函数中,选取状态行为对
q ∗ ( s , a ) = m a x π q π ( s , a ) q_*(s,a)=max_{\pi}q_{\pi}(s,a) q∗(s,a)=maxπqπ(s,a)
价值迭代 :先更新每个状态 s s s的长期价值函数 V ( s ) V(s) V(s),这个价值是立即回报 r ( s , a ) r(s,a) r(s,a)与下一个状态 s + 1 s+1 s+1的长期价值的综合,从而获得更新。每次迭代,对于每个状态 s s s都要更新价值函数 V ( s ) V(s) V(s),对于每个状态 s s s的价值更新,需要好考虑所有行文Action的可能性。
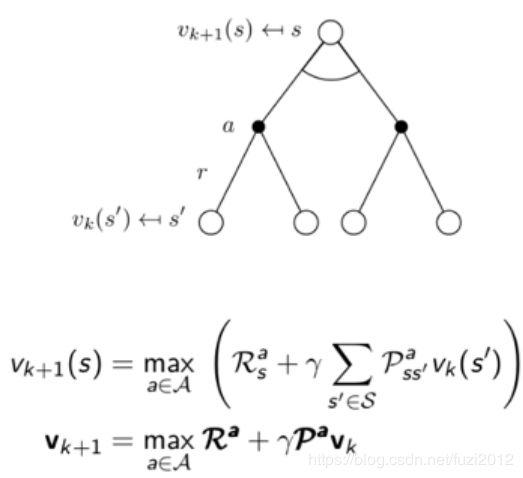
价值迭代的伪代码:

1.initialization:初始化所有状态的 V ( s ) V(s) V(s);
2.finding optimal value function:(找到最有价值函数)注意伪代码里的max;
- 对每一个当前状态 s s s,对每一个可能的动作 a a a,都计算一下采取这个动作之后到达的下一个状态的期望价值;
- 看哪个动作可能达到的状态的价值函数最大,就将这个最大的期望价值函数作为当前状态 s s s的价值函数 V ( s ) V(s) V(s),
- 循环执行这个步骤,知道价值函数收敛,就可以得到最优的价值函数了
3.policy extraction:利用上面的步骤得到的optimal价值函数和状态转移概率就计算出每一个状态应采取的optimal动作,这个是确定的。
策略迭代与价值迭代的区别
策略迭代:使用Bellman方程来更新value,最后收敛的value即 V π V^{\pi} Vπ是当前policy下的value值(所以叫做对policy进行评估),目的是为了后面的policy improvement得到新的policy。
价值迭代 使用Bellman最优方程来更新value,最后收敛得到的value即 V ∗ V^* V∗就是当前state状态下最优的value值,因此只要最后收敛,那么最优的policy也就得到了。
二者之间的区别与联系:策略迭代的第二步policy evaluation与价值迭代的第二步finding optimal value function十分相似,除了后者拥有max操作,前者没有max。因此后者可以得出optimal value function,而前者不能得到optimal function。
策略迭代的收敛速度要更快一些。
在状态空间较小时,最好选择策略迭代方法;
在状态空间较大时,价值迭代的计算量会更小一些;
本质上都依赖于模型,而且理想情况下都需要遍历所有状态,这在稍微复杂一点儿的问题上基本不可能了 。
动态规划的不足
DP的缺点显而易见,必须知道状态转移概率才能进行最优策略的计算,着在真实场景中几乎不可能实现。
对于DP而言,她的推演是整个树状散开的,这种方法被称为FULL-width backup方法。在这个方法中,对于每一次backup来说,所有的后继状态和动作都要被考虑在内,并且需要已知MDP的转移矩阵和奖励函数,因此DP面临着梯度灾难问题。