C的代码是如何变成程序的
C的代码是如何变成程序的
C语言是一门典型的编译语言,源代码文件需要编译成目标代码文件才能运行。可以认为程序文件就是编译好的目标代码文件。
以GCC的编译过程为例。GCC的翻译过程可以分成四个阶段:预处理器、编译器、汇编器、链接器,执行这四个阶段的程序一起构成了一个编译系统。

图 1 GCC编译系统(取自《深入理解计算机系统》)
1 预处理器
预处理器(cpp)负责对源代码进行文本处理。它根据以字符#开头的命令,修改原始的C代码。如:
1. #include
从编译器的内置查找路径的根部开始查找stdio.h文件,读取其内容,并把它直接插入到程序文本中。 2. #include ”my_header.h” 与上条的区别就是查找路径是从当前代码文件所在目录开始。
3. #define MACRO_NAME CONTEXT 将原始代码中所有的MACRO_NAME文本都替换成CONTEXT,这种替换可能会引起很多难以理解的错误。
4. #define FUNC_NAME(PARA_LIST) CONTEXT 与上条类似,区别在于会在查找到FUNC_NAME的地方进行参数匹配,并将CONTEXT中出现的参数名称用对应的文本进行替换。
5. #define MACRO_NAME #undef MACRO_NAME 前者用于单纯的宏定义,后者用于取消宏定义。
6. #ifdef #ifndef #else #endif 这几个都是用于条件编译的命令,用于决定被包括的文本是否加入到处理后的文本中。
常用的预处理命令就是这些,处理后就得到了另一个C代码文件,一般用.i作为扩展名。
这部分有一个常用的技巧:header guard,用于防止头文件被重复加载。
假设一个场景,某个工程中的3个文件:main.c、a.h、b.h,其中每个文件的开头有这样的文本:
//main.c
#include ”a.h”
#include ”b.h”
...//a.h
#include ”b.h”
void func_a();//b.h
void func_b();//main.i
void func_b();
void func_a();
void func_b();
...#ifndef XXX_YYY_ZZZ
#define XXX_YYY_ZZZ
...
#endif2 编译阶段
编译器(ccl)将文本文件hello.i翻译成文本文件hello.s,它包含一个汇编语言程序。汇编语言程序中的每条语句都以一种标准的文本格式确切地描述了一条低级机器语言指令。汇编语言为不同高级语言的不同编译器提供了通用的输出语言,例如C编译器和Fortran编译器产生的输出文件用的都是一样的汇编语言。
例如,hello.c为:
#include
int main(int argc, char *argv[])
{
printf("hello world\n");
return 0;
} .file "hello.c"
.def ___main; .scl 2; .type 32; .endef
.section .rdata,"dr"
LC0:
.ascii "hello world\0"
.text
.globl _main
.def _main; .scl 2; .type 32; .endef
_main:
LFB6:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
...3 汇编阶段
接下来,汇编器(as)将hello.s翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的格式,并将结果保存在目标文件hello.o中。hello.o文件是一个二进制文件,它的字节编码是机器语言指令而不是字符,如果我们在文本编辑器中打开hello.o文件,看到的将是一堆乱码。
运行gcc –c hello.c可以得到hello.o文件,它是二进制格式,无法直接查看,可以用反汇编器来查看它的编码:objdump –d code.o
以一种典型的可重定位目标格式ELF为例。ELF文件的头部数据包含了:
1. 生成该文件的系统的字的大小和字节顺序。
2. 帮助链接器语法分析和解释目标文件信息的数据。
ELF文件中包含的数据可分成几个节,每个节的位置和大小是由节头部表描述的:
1. .text 机器代码
2. .rodata 只读数据,比如双引号括起的字符串等。
3. .data 已初始化的全局变量。
4. .bss 未初始化的全局变量。在ELF文件中它只是占位符,在目标文件中不占据实际的空间。
5. .symtab 一个符号表,存放在程序中定义和引用的函数和全局变量的信息。
6. .rel.text 一个.text节中位置的列表,当链接器进行链接时,需要修改这些位置。
7. .rel.data 被引用或定义的全局变量的重定位信息,依赖于其它模块信息的已初始化的全局变量,其值在链接时需要被修改。
8. .debug 调试符号表。
9. .line 机器代码与源文件行号的对应关系,只有在-g选项时才会产生。
10. .strtab 一个字符串表,包括.symtab和.debug中的符号表,以及每个节的名字。
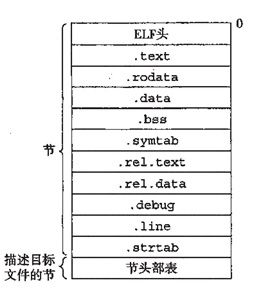
图 2 典型的ELF可重定位目标文件
4 链接阶段
链接器(ld)负责将多个可重定位目标文件(.o文件)合并为一个可执行文件,如hello程序文件就是由hello.o和printf.o文件合并得来的。合并过程中链接器负责解析符号表,并修改不同编译模块间的引用信息,如hello.o的main函数调用printf函数时,机器代码的跳转位置直到链接阶段才会确定,链接器会将跳转位置修改为printf函数的入口位置。
链接器解析本地符号的引用是非常简单的。编译器只允许每个模块中每个本地符号只有一个定义。不过,对全局符号的解析就很复杂。如果链接器在所有模块中都找不到某个符号时,它就输出”undefined reference”错误信息并终止。如果所有符号的解析都顺利完成,链接器最后会输出所有符号的引用位置都确定了的可执行文件。