神经网络的演变与发展(Part 2)

导言
在上一篇文章中,我们简要的概述了神经网络和深度学习。特别是,主要讨论了传感器模型、前馈神经网络和反向传播。在本文中,我们将深入学习:卷积神经网络(CNN)和递归神经网络(RNN)。
深度学习基础
从20世纪90年代到2006年发展的第二个低谷,神经网络再次进入人们意识,但是,这次比以前更加强大。在神经网络兴起期间发生的巨大事件是由Hinton在包括Salahundinov在内的多个地方提交的多层神经网络(即,现在的“深度学习”)的两个论点。
其中一个论文解决了为神经网络设置初始化值的问题。简单的说,解决方案是将输入值视为x,将输出值视为解码x,然后通过这个方法找到更好的初始化点。另一篇论文提出了一种快速训练深度神经网络的方法。实际上,有许多因素促进了神经网络在现代的普及,例如,计算资源的巨大增长和数据的可用性。在20世纪80年代,由于缺乏数据和计算资源,很难训练大规模的神经网络。
神经网络最早兴起是由三大巨头驱动的,即Hinton、Bengio和LeCun。Hinton的主要 成就是Restricted Boltzmann Machine和Deep Auto encoder。Bengio的主要贡献是使用元模型进行深度学习的一系列突破。这也是深度学习取得重大突破的第一个领域。
2013年,基于元模型的语言建模已经能够胜过当时最有效的方法——概率模型。LeCun的主要成就是与CNN有关的研究。深度学习的主要表现在NIPS、ICML、CVPR、ACL等许多重大峰会上都引起了不小的关注。这包括Google Brain、Deep Mind和Facebook AI的出现,这些都将他们的研究中心放在深度学习领域。

深度学习进入人们意识后的第一个突破是在语音识别领域。在我们开始使用深度学习之前,模型都是在先前定义的统计数据库上进行的。2010年,微软使用深度学习神经网络进行语音识别。从下图可以看出,两个错误指标都下降了2/3,这是一个非常明显的改善。基于最新的ResNet技术,微软已将该指标降至6.9%,并且逐年实现改进。

在图像分类领域,CNN模型在2012年以ImageNet的形式经历了重大突破。在ImageNet中,图像分类使用海量数据集进行测试,然后分类为1,000中类型。在应用深度学习之前,由于Hinton和他的学生在2012年使用CNN所做的工作,图像分类系统的最佳错误率为25.8%(2011年),仅降低了10%。
从图中我们可以看出,子2012年以来,该指标每年都经历了重大突破,所有这些都是使用CNN模型实现的。
这些巨大的成就在很大程度上归功于现代系统的多层结构,因为它们允许独立学习和通过分层抽象结构表达数据的能力。抽象的特征可以应用于各种任务,显著的促进了深度学习的当前流行。

接下来,将介绍两种经典和常见类型的深度学习神经网络:一种是卷积神经网络(CNN);另一种是递归神经网络(RNN)。
卷积神经网络(CNN)
卷积神经网络有两个核心概念。一个是卷积,另一个是汇集。对于这种说法,有些人可能会问我们为什么不简单的使用前馈神经网络而使用CNN。例如,以1,000*1,000的图像为例,神经网络在隐藏层上将拥有100万个节点。那么,前馈神经网络将具有10^12个参数。对于这么大数量的参数,系统几乎不可能学习,因为它需要绝对大量的估计。
但是,大量图像具有这样的特征。如果我们使用CNN对图像进行分类,那么由于卷积的概念,隐藏层上的每个节点只需要连接并扫描图像的一个位置的特征。如果隐藏层上的每个节点连接到10*10个估计,则最终参数数量为1亿,如果可以共享多个隐藏层访问的本地参数,则参数数量会显著减少。
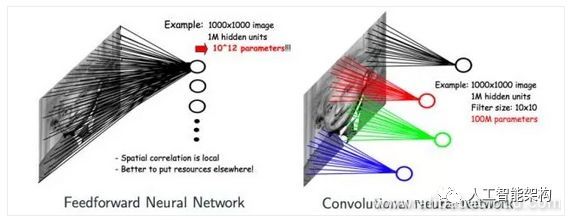
如下图所示,前馈神经网络和CNN之间的差异显然很大。图像中的模型从左到右完全是连接的、正常的、前馈的,是完全连接的前馈和CNN建模的神经网络。通过下图可以看到,它可以共享CNN神经网络隐藏层上节点的连接权重参数。

另一个操作是汇集。CNN将在卷积原理的基础上,在中间形成隐藏层,即会基层。最常见的池化方法是MaxPooling,其中隐藏层上的节点选择最大输出值。因为多个内核正在汇集,所以我们在中间获得了多个隐藏层节点。
有什么好处呢?首先,汇集进一步减少了参数的数量;其次,它提供了一定的平移不变性。如图所示,如果图像中显示的九个节点之一要经历翻译,则在池化层上生成节点将保持不变。

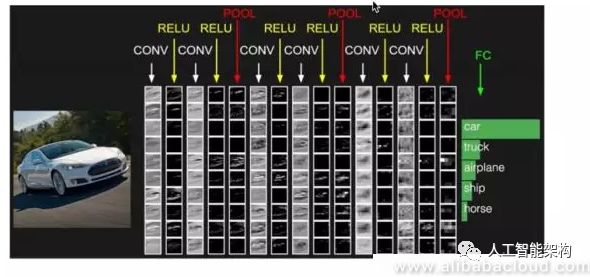
CNN的这两个特性使其在图像处理领域中流行,并且已成为图像处理领域的标准。下面的可视化汽车的例子是CNN在图像分类领域中应用的一个很好的例子。在将汽车的原始图像输入CNN模型后,可以通过卷积和ReLU激活层传递一些简单粗糙的特征,如边缘和点。我们能够直观的看到它们距离最上面的输出层的输出图像越接近汽车的轮廓。这个过程最终将检索隐藏的图层表示,并将其连接到分类图层,之后它将接收图像的分类,如图像中显示的汽车、卡车、飞机、船舶和马。
下图是LeCun和其他研究人员在手写识别领域早期使用的神经网络。该网络在20世纪90年代在美国邮政系统中得到应用。有兴趣的读者可以登录LeCun的网站查看手写识别的动态过程。

虽然CNN在图像识别领域已经变得非常受欢迎,但它在过去两年中也在文本识别方面发挥了重要作用。例如,CNN是目前文本分类最佳解决方案的基础。在确定一段文本的类别方面,所有人真正需要做的是从文本中的关键词中寻找指示,这是一项非常适合CNN模型的任务。
CNN具有广泛的实际应用,例如在调查,自动驾驶汽车,分段和神经风格中。神经风格是一个迷人的应用程序。例如,AppStore中有一个名为Prisma的流行应用程序,它允许用户上传图像,并将其转换为不同的样式。例如,它可以转换为Van Goh的Starry Night风格。这个过程在很大程度上依赖于CNN。
递归神经网络
至于递归神经网络背后的基本原理,我们可以从下面的图像中看到,这种网络的输出不仅依赖于输出x,还依赖于隐藏层的状态,隐藏层的状态根据先前的输入x进行更新。展开的图像显示了整个过程。来自第一个输入的隐藏层是S(t-1),它影响下一个输入X(t)。递归神经网络模型的主要优点是,可以在顺序数据操作中使用它,如文本、语言和语音,其中当前数据的状态受先前数据状态的影响。使用前馈神经网络很难处理这种类型的数据。

说到递归神经网络,我们不得不说前面提到的LSTM模型。LSTM实际上并不是一个完整的神经网络。简而言之,它是RNN节点经过复杂处理的结果。LSTM具有三个门,即输入门、遗忘门和输出门。
这些门中的每一个用于处理单元中的数据,并确定单元中的数据是否应该被输入,遗忘或输出。

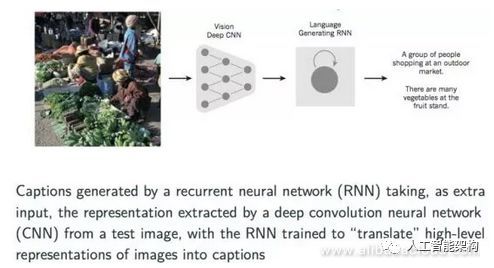
最后,我们来谈谈神经网络的跨学科应用,这种应用正在获得广泛的认可。该应用程序涉及将图像转换为图像的文本描述或描述它的标题。我们可以首先使用CNN模型来描述具体的实现过程,以提取有关图像的信息并生成矢量表示。稍后,我们可以将该向量作为输入传递给已经训练过的递归神经网络,以产生图像的描述。
总结
在本文中,我们主要讨论了神经网络的发展,并介绍了该领域的几个基本概念和方法。上述文章是基于孙飞博士在年度阿里巴巴云计算大会上发表的演讲。他目前参与研究推荐系统和文本生成方法。

长按二维码 ▲
订阅「架构师小秘圈」公众号
如有启发,帮我点个在看,谢谢↓