深入理解计算机系统-之-数值存储(五)--浮点数在内存中的存储方式
前景回顾
前面我们了解到依据CPU的端模式的架构不同,数据的存储的字节序也不同
BE big-endian 大端模式,最直观的字节序 地址低位存储值的高位,地址高位存储值的低位 ,数据填写时,不要考虑对应关系,只需要把内存地址从左到右按照由低到高的顺序写出,把值按照通常的高位到低位的顺序写出,两者对照,一个字节一个字节的填充进去。
LE little-endian 小端模式,则最符合人的思维的字节序,地址低位存储值的低位,地址高位存储值的高位 ,这点比较符合人的思维的字节序,是因为从人的第一观感来说,低位值小,就应该放在内存地址小的地方,也即内存地址低位,反之,高位值就应该放在内存地址大的地方,也即内存地址高位
任何数据在内存中都是以二进制的形式存储的。
具体参照深入理解计算机系统-之-数值存储(一)-CPU大端和小端模式详解
接着我们讨论了如何通过程序打印出变量在内存中的存储形式,具体参照深入理解计算机系统-之-数值存储(二)–C程序打印变量的每一字节或者位
接着我们了解了原码,反码,补码和移码的表示形式,具体参照深入理解计算机系统-之-数值存储(三)– 原码、反码、补码和移码详解
最后我们通过分析发现,整数在内存中通过补码的表现形式来存储。
详细参见深入理解计算机系统-之-数值存储(四)–整数在内存中的存储方式
浮点数二进制科学表示法
但是对于浮点数在内存是如何存储的?
目前所有的C/C++编译器都是采用IEEE所制定的标准浮点格式,即二进制科学表示法。这种表示方法我们在本科学习计算机组成原理的时候肯定都不止依次提到。
我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?
在C/C++语言以及C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit,double数据占用64bit,理论上double和float在32、64位机上应该是占用相同字节数的, 因为其实不论是float还是double在存储方式上都是遵从IEEE的规范的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53。
浮点数格式
根据国际标准IEEE 754,任意一个二进制浮点数V可以表示成下面的形式:
浮点数=(−1)S×M×2E
- (-1)^s表示符号位,当s=0,V为正数;当s=1,V为负数。
- M表示有效数字,大于等于1,小于2,一般化为规范小数的形式,这样其最高位(个位)必为1, 因此个位和小数点就不存储,省略作为隐藏位,从而使浮点数尾数不变,但是精度进一步增加。
- 2^E表示指数位。
举例来说,十进制的5.0,写成二进制是101.0,相当于 1.010×22 。那么,按照上面V的格式,可以得出S=0,M=1.01,E=2。
十进制的-5.0,写成二进制是-101.0,相当于-1.01×2^2。那么,S=1,M=1.01,E=2。
因此通过上面的分析,我们知道只需要3个部分就可以表示一个浮点数
- 符号位(Sign) : 0代表正,1代表为负
- 阶码,也称指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移码存储。
- 尾数部分(Mantissa),隐藏了个位和小数点的有效数字。
那么我们的浮点数float和double的存储格式就有如下
| 类型 | 长度 | 符号位 | 阶码(不含1位隐藏位) | 尾数 | 阶码范围 | 阶码偏移量 | 浮点数范围 |
|---|---|---|---|---|---|---|---|
| float | 32 | 1 | 8 | 23 | -126~+127 | +127 | 10−38−10+38 |
| double | 64 | 1 | 11 | 52 | -1022~+1023 | +1023 | 10−308−10+308 |
| 扩展精度 | 80 | 1 | 15 | 64 | -16382~+16383 | +16383 |

规范化尾数
前面说过,1≤M<2,也就是说,M可以写成1.xxxxxx的形式,其中xxxxxx表示小数部分。
IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的xxxxxx部分。
比如保存1.01的时候,只保存01,等到读取的时候,再把第一位的1加上去。
这样做的目的,是节省1位有效数字。以32位浮点数为例,留给M只有23位,将第一位的1舍去以后,等于可以保存24位有效数字。
阶码用移码表示
首先,E为一个无符号整数(unsigned int)。
这意味着,如果E为8位,它的取值范围为0~255;如果E为11位,它的取值范围为0~2047。但是,我们知道,科学计数法中的E是可以出现负数的(浮点数如果表示一个<1的小数,那么尾数为规格化小数,那么阶码应该<0)
所以IEEE 754规定,E的真实值必须再减去一个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。即阶码偏移量。这个就是移码的表示形式。
比如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。
通过阶码偏移量,将-126~+127的阶码转换为1~254范围的移码来表示。指数部分(阶码)即使用所谓的偏正值(阶码偏移量)形式表示,偏正值为实际的指数大小与一个固定值(32位的情况是127)的和。采用这种方式表示的目的是简化比较。因为,指数的值可能为正也可能为负,如果采用补码表示的话,全体符号位S和阶码自身的符号位将导致不能简单的进行大小比较。正因为如此,指数部分通常采用一个无符号的正数值存储。单精度的指数部分是−126~+127加上偏移值127 ,指数值的大小从1~254(0和255是特殊值)。浮点小数计算时,指数值减去偏正值将是实际的指数大小。
然后,我们提到了采用移码存储的阶码,表示范围32位时为1~254,但并不是0和255不使用,而是作为特殊值,因此阶码E还可以再分成三种情况:
- E不全为0或不全为1。这时,浮点数就采用上面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第一位的1。
- E全为0。这时,浮点数的指数E等于1-127(或者1-1023),有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示±0,以及接近于0的很小的数字。
- E全为1。这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s);如果有效数字M不全为0,表示这个数不是一个数(NaN)。
示例
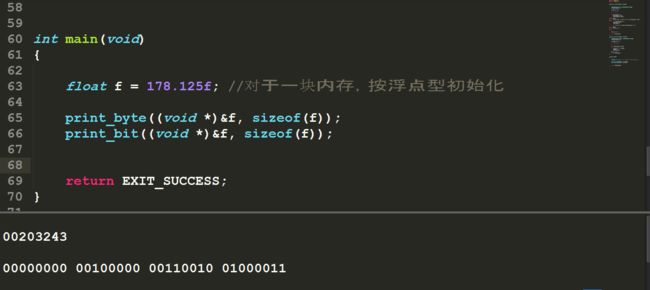
对于float a = 178.125=10110010.001B=1.0110010001×27
阶码E = 7+127 =134 = 10000110B
| 符号位 | 阶码 | 尾数 |
|---|---|---|
| 0 | 10000110 | 0110010001000000000 |
存储起来就是43322000H,用小端模式存储,按照字节由低到高存储依次是00 20 32 43 H
#include 程序的运行结果如下