大数据系列 (一)、数据分片与路由(Hash partition and Routing)
大数据背景下,数据规模已经由GB级跨越到PB级,单机明显无法存储与处理如此规模的数据量,只能依靠大规模集群来对这些数据进行存储和处理,所以系统可扩展成衡量系统优劣的重要指标。传统并行数据库系统为了支持更多的数据,往往采用纵向扩展(Scale Up)的方式,既不增加机器数量,而是通过改善单机硬件资源配置来解决问题。而目前主流的大数据存储与计算系统往往采用横向扩展(Scale Out)的方式支持系统的可扩展性,即通过增加机器数目来获得水平扩展的能力。与此对应,对于待存储处理的海量数据,需要用过数据分片(Shard/Partition)将数据进行切分并分配到各个机器中区,数据分片后,如何能够找到某条记录的存储位置就成为必然要解决的问题。这一般被称为数据路由(Routing)
数据分片与数据复制是紧密联系的两个概念,对于海量数据,通过数据分片实现系统的水平扩展能力,通过数据复制保证数据的高可用性。由于机器可能存在隐患,为了保证数据不丢失,可将数据备份起来,客户端可从多个备份数据中选择物理距离较近的进行读取,增加了读操作的并发性又可以提高单次读的读取效率。

1 抽象模型
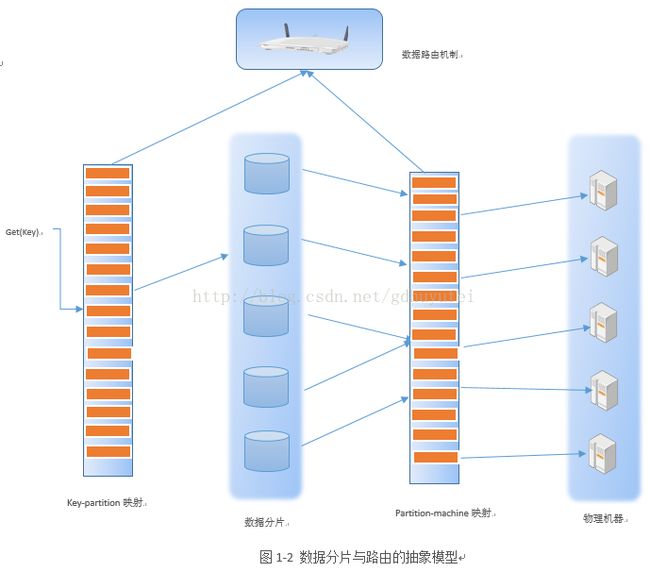
图1-2展示了一个很高抽象级别的数据分片与路由模型,可以看做是一个二级映射关系。第一级映射是key-partition映射,其将数据记录映射到数据分片空间,这往往是多对一的映射关系,即一个数据分片包含多天记录数据;第二级映射是partition-machine映射,其将数据分片映射到物理机器中,这一版也是多对一映射关系,机一台物理主机容纳多个数据分片。
在做数据分片时,根据keypartition映射关系将大数据水平切割成中多的数据分片,然后再按照partition-machine映射关系将数据分片放置到对应的物理机器上。而在数据路由时,比如要查找某条记录的值get(key),首先根据key-partition映射找到对应的数据分片,然后再查找partition-machine关系表,就可以知道具体哪台物理机器存储该条数据,之后即可从相应的物理机读取key对应的value内容
大数据背景下,数据规模已经由GB级跨越到PB级,单机明显无法存储与处理如此规模的数据量,只能依靠大规模集群来对这些数据进行存储和处理,所以系统可扩展成衡量系统优劣的重要指标。传统并行数据库系统为了支持更多的数据,往往采用纵向扩展(Scale Up)的方式,既不增加机器数量,而是通过改善单机硬件资源配置来解决问题。而目前主流的大数据存储与计算系统往往采用横向扩展(Scale Out)的方式支持系统的可扩展性,即通过增加机器数目来获得水平扩展的能力。与此对应,对于待存储处理的海量数据,需要用过数据分片(Shard/Partition)将数据进行切分并分配到各个机器中区,数据分片后,如何能够找到某条记录的存储位置就成为必然要解决的问题。这一般被称为数据路由(Routing)
数据分片与数据复制是紧密联系的两个概念,对于海量数据,通过数据分片实现系统的水平扩展能力,通过数据复制保证数据的高可用性。由于机器可能存在隐患,为了保证数据不丢失,可将数据备份起来,客户端可从多个备份数据中选择物理距离较近的进行读取,增加了读操作的并发性又可以提高单次读的读取效率。
1 抽象模型
图1-2展示了一个很高抽象级别的数据分片与路由模型,可以看做是一个二级映射关系。第一级映射是key-partition映射,其将数据记录映射到数据分片空间,这往往是多对一的映射关系,即一个数据分片包含多天记录数据;第二级映射是partition-machine映射,其将数据分片映射到物理机器中,这一版也是多对一映射关系,机一台物理主机容纳多个数据分片。
在做数据分片时,根据keypartition映射关系将大数据水平切割成中多的数据分片,然后再按照partition-machine映射关系将数据分片放置到对应的物理机器上。而在数据路由时,比如要查找某条记录的值get(key),首先根据key-partition映射找到对应的数据分片,然后再查找partition-machine关系表,就可以知道具体哪台物理机器存储该条数据,之后即可从相应的物理机读取key对应的value内容
1 哈希分片(Hash Partition)
1.1 Round Robin
RoundRobin就是俗称的哈希取模法,是实际中非常常用的数据分片方法。假设有K台物理机,通过以下哈希函数即可实现数据分片:
H(key)=hash(key)modK
对物理机进行编号0到K-1,根据以上哈希函数,对于以key为主键的某个记录,H(key)的数值即是物理机在在集群中的放置位置(编号),Round Robin方法缺乏灵活性,因为一旦集群中加入了某台机器或减少某台机器都会导致整个机器位置的重排。
1.2 虚拟桶
Membase是一个内存分布式NoSQL数据库,对于数据分片管理,其提出了虚拟桶的实现方式,运行机制如图1-3所示。
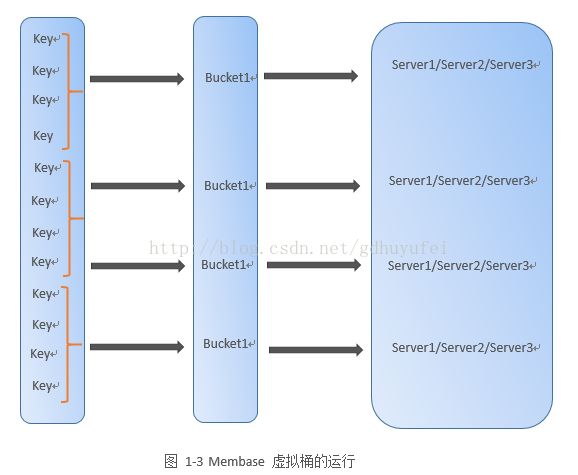
,Membase在待存储记录的物理机之间引入了虚拟桶层,所有记录首先通过哈希函数映射到对应的虚拟桶,记录和虚拟桶是多对一的关系,即一个虚拟桶包含多条记录信息;第二层映射是虚拟桶和物理机之间的映射关系,同样也是多对一映射,一个物理机可以容纳多个虚拟桶,具体实现方式通过查找表来实现的,即Membase通过内存表管理这些映射关系。
对照抽象模型可以看出,Membase的虚拟桶层就是对应数据分片层,一个虚拟桶即是一个数据分片。Key-partition映射采用映射函数。
与Round Roubin相比,Membase引入了虚拟桶层,这样将原先由记录直接到物理机的单层映射解耦成两级映射,大大增加了系统的扩展灵活性。当新加入机器时,将某些虚拟桶从原先分配的机器重新分配各机器,只需要修改partition-machine映射表中受影响的个别条目就能实现扩展,具有较强的灵活性。
1.3 一致性哈希(Consistent Hashing)
分布式哈希表(DHT)是P2P网络和分布式存储中常见的一项技术,是通过哈希表的分布式扩展,既考虑在多机分布式环境中,每台机器负责承载部分数据的存储情形下,如何通过哈希方式老对数据进行增/删/改/查等数据操作方法。DHT只是一种技术概念,具体的实现方式有很多种,一致性哈希是其中一种实现方式,图1-4是哈希空间长度为5的二进制数值(m=5)的一致性哈希算法示意图。

一致性哈希算法是建立在一种环状结构上,在哈希空间可容纳 个长度(0~31)空间里,每个机器根据IP地址或者端口号经过哈希函数映射到环内(图中6个大圆代表机器,后面的数字代表哈希值,即根据IP地址或者端口号经过哈希函数计算得出的在环状空间内的具体位置),而这台机器则负责存储落在一段有序哈希空间内,比如N12节点就存储哈希值扩在9~12范围内的数据,而N5负责存储哈希值落在(30~31和0~5)的范围内的数据。同时,每台机器还记录着自己的前驱和后继节点,是成为一个真正意义上的有向环。
1) 路由问题
a) 直接插画造法
那么问题来了,怎样根据接收到的请求,找到存储的值呢,拿图1-4来说,假如有一个请求向N5查询的主键为H(key)=6,因为此哈希值落在N5和N8之间,所以该请求的值存储在N8的节点上,即如果哈希值落在自身管辖的范围内则在此节点上查询,否则继续往后找一只找到节点Nx x是大于等于待查节点值的最小编号,这样一圈下来肯定能找到结果。
b) 路由表法
很明显一种方法缺乏效率,为了加快查找速度,可以在每个机器节点配置路由表,路由表存储每个节点到每个除自身节点的距离拿N12来说,路由表如下
![]()
例如表中第三项代表与N12的节点距离为4的哈希值(12+4=16)落在N17节点身上,同理第五
项代表与N12的距离为16的哈希值落在N29身上,这样找起来就非常的快速,有了路由表假设
机器节点Ni接收到了主键为key查询请求,如果H(key)=j不再Ni的管辖范围,此时该如何
操作呢?
2) 一致性哈希路由算法
拿具体的节点来说,如图1-4,假设请求节点N5查询,把N5的路由表列如下:
![]()
假如请求的主键哈希值为H(key)=24,首先查询是否在N5的后继结点上,发现后继节点N8小于逐渐哈希值,则根据N5的路由表查询,发现大于24的最小节点为N29(只有29)(因为5+16=21<24)则在