【作为开发你必须弄懂的几个问题—Mysql】
【MylSAM和InnoDB】
MyISAM是MySQL的默认数据库引擎(5.5版之前),由早期的ISAM(Indexed Sequential Access Method:有索引的顺序访问方法)所改良。虽然性能极佳,但却有一个缺点:不支持事务处理(transaction)。不过,在这几年的发展下,MySQL也导入了InnoDB(另一种数据库引擎),以强化参考完整性与并发违规处理机制,后来就逐渐取代MyISAM。
InnoDB,是MySQL的数据库引擎之一,为MySQL AB发布binary的标准之一。InnoDB由Innobase Oy公司所开发,2006年五月时由甲骨文公司并购。与传统的ISAM与MyISAM相比,InnoDB的最大特色就是支持了ACID兼容的事务(Transaction)功能,类似于PostgreSQL。目前InnoDB采用双轨制授权,一是GPL授权,另一是专有软件授权。
区别:
1.mylsam不支持事务 Innodb支持事务 Innodb支持事务
2.mylsam可被压缩,占用存储空间少(.frm文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex))
Innodb需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引
3.mylsam支持全文索引,Innodb不支持全文索引
4.mylsam不支持外键,Innodb支持外键
5.mylsam所有操作都是表级锁,mylsam支持行级锁
MyISAM和InnoDB两者的应用场景:
1) MyISAM管理非事务表。它提供高速存储和检索,以及全文搜索能力。如果应用中需要执行大量的SELECT查询,那么MyISAM是更好的选择。
2) InnoDB用于事务处理应用程序,具有众多特性,包括ACID事务支持。如果应用中需要执行大量的INSERT或UPDATE操作,则应该使用InnoDB,这样可以提高多用户并发操作的性能。还有事务日志,故障恢复,也都非常方便。
更多请点击https://www.cnblogs.com/kevingrace/p/5685355.html
【为什么用自增列作为主键】
1.如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择主键作为聚集索引、如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引、如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
2.数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
3.如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页
4.如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面
【为什么使用数据索引能提高效率】
1.数据索引的存储是有序的
2.在有序的情况下,通过索引查询一个数据是无需遍历索引记录的
3.极端情况下,数据索引的查询效率为二分法查询效率,趋近于 log2(N)
【B+树索引和哈希索引的区别】
B+树是一个平衡的多叉树,从根节点到每个叶子节点的高度差值不超过1,而且同层级的节点间有指针相互链接,是有序的

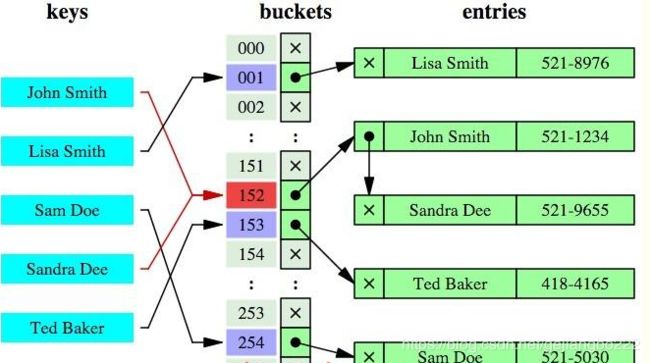
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可,是无序的
哈希索引的优势:
1.等值查询。哈希索引具有绝对优势(前提是:没有大量重复键值,如果大量重复键值时,哈希索引的效率很低,因为存在所谓的哈希碰撞问题。)
哈希索引不适用的场景:
1.不支持范围查询
2.不支持索引完成排序
3.不支持联合索引的最左前缀匹配规则
在HEAP表中,如果存储的数据重复度很低(也就是说基数很大),对该列数据以等值查询为主,没有范围查询、没有排序的时候,特别适合采用哈希索引
而常用的InnoDB引擎中默认使用的是B+树索引,它会实时监控表上索引的使用情况,如果认为建立哈希索引可以提高查询效率,则自动在内存中的“自适应哈希索引缓冲区”建立哈希索引(在InnoDB中默认开启自适应哈希索引),通过观察搜索模式,MySQL会利用index key的前缀建立哈希索引,如果一个表几乎大部分都在缓冲池中,那么建立一个哈希索引能够加快等值查询。
注意:在某些工作负载下,通过哈希索引查找带来的性能提升远大于额外的监控索引搜索情况和保持这个哈希表结构所带来的开销。但某些时候,在负载高的情况下,自适应哈希索引中添加的read/write锁也会带来竞争,比如高并发的join操作。like操作和%的通配符操作也不适用于自适应哈希索引,可能要关闭自适应哈希索引。
【B树和B+树的区别】
1.B树,每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为nul,叶子结点不包含任何关键字信息。
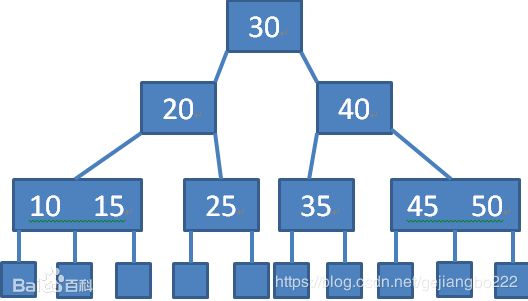
2.B+树,所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接,所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)
【为什么说B+比B树更适合实际应用中操作系统的文件索引和数据库索引?】
1.B+的磁盘读写代价更低B+的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了
2.B+-tree的查询效率更加稳定由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
【MySQL联合索引】
1.联合索引是两个或更多个列上的索引。对于联合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a 、 a,b 、 a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。
2.利用索引中的附加列,您可以缩小搜索的范围,但使用一个具有两列的索引 不同于使用两个单独的索引。复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知 道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。
【什么情况下应不建或少建索引】
1.表记录太少
2.经常插入、删除、修改的表
3.数据重复且分布平均的表字段,假如一个表有10万行记录,有一个字段A只有T和F两种值,且每个值的分布概率大约为50%,那么对这种表A字段建索引一般不会提高数据库的查询速度。
4.经常和主字段一块查询但主字段索引值比较多的表字段
【四种隔离级别】
1.Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
2.Repeatable read (可重复读):可避免脏读、不可重复读的发生。
3.Read committed (读已提交):可避免脏读的发生。
4.Read uncommitted (读未提交):最低级别,任何情况都无法保证。
【行级锁定的优缺点】
优点:
1.当在许多线程中访问不同的行时只存在少量锁定冲突。
2.回滚时只有少量的更改
3.可以长时间锁定单一的行。
缺点:
1.比页级或表级锁定占用更多的内存。
2.当在表的大部分中使用时,比页级或表级锁定速度慢,因为你必须获取更多的锁。
3.如果你在大部分数据上经常进行GROUP BY操作或者必须经常扫描整个表,比其它锁定明显慢很多。
4.用高级别锁定,通过支持不同的类型锁定,你也可以很容易地调节应用程序,因为其锁成本小于行级锁定。
【MySQL触发器简单实例】
1.CREATE TRIGGER <触发器名称> --触发器必须有名字,最多64个字符,可能后面会附有分隔符.它和MySQL中其他对象的命名方式基本相象.
2.{ BEFORE | AFTER } --触发器有执行的时间设置:可以设置为事件发生前或后。
3.{ INSERT | UPDATE | DELETE } --同样也能设定触发的事件:它们可以在执行insert、update或delete的过程中触发。
4.ON <表名称> --触发器是属于某一个表的:当在这个表上执行插入、 更新或删除操作的时候就导致触发器的激活. 我们不能给同一张表的同一个事件安排两个触发器。
5.FOR EACH ROW --触发器的执行间隔:FOR EACH ROW子句通知触发器 每隔一行执行一次动作,而不是对整个表执行一次。
6.<触发器SQL语句> --触发器包含所要触发的SQL语句:这里的语句可以是任何合法的语句, 包括复合语句,但是这里的语句受的限制和函数的一样。
例:
DROP TRIGGER IF EXISTS demo;
DELIMITER ;; #修改结束符
CREATE TRIGGER demo BEFORE DELETE ON users FOR EACH ROW #建立一个触发器,名称+条件
BEGIN
INSERT INTO logs VALUES(NOW()); #触发器出发后数据库做的操作
INSERT INTO logs VALUES(NOW());
END;;
DELIMITER ; #改回结束符【什么是存储过程】
简单的说,就是一组SQL语句集,功能强大,可以实现一些比较复杂的逻辑功能,类似于JAVA语言中的方法;
ps:存储过程跟触发器有点类似,都是一组SQL集,但是存储过程是主动调用的,且功能比触发器更加强大,触发器是某件事触发后自动调用;
有哪些特性
1.有输入输出参数,可以声明变量,有if/else, case,while等控制语句,通过编写存储过程,可以实现复杂的逻辑功能;
2.函数的普遍特性:模块化,封装,代码复用;
3.速度快,只有首次执行需经过编译和优化步骤,后续被调用可以直接执行,省去以上步骤;
例:
创建:
DROP PROCEDURE IF EXISTS `proc_adder`;
DELIMITER ;;
CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_adder`(IN a int, IN b int, OUT sum int)
BEGIN
DECLARE c int;
if a is null then set a = 0;
end if;
if b is null then set b = 0;
end if;
set sum = a + b;
END
;;
DELIMITER ;
执行存储过程:
set @b=5;
call proc_adder(2,@b,@s);
select @s as sum;
【MySQL优化】
1.开启查询缓存,优化查询
2.explain你的select查询,这可以帮你分析你的查询语句或是表结构的性能瓶颈。EXPLAIN 的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的
3.当只要一行数据时使用limit 1,MySQL数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据
4.为搜索字段建索引
5.使用 ENUM 而不是 VARCHAR,如果你有一个字段,比如“性别”,“国家”,“民族”,“状态”或“部门”,你知道这些字段的取值是有限而且固定的,那么,你应该使用 ENUM 而不是VARCHAR。
6.Prepared StatementsPrepared Statements很像存储过程,是一种运行在后台的SQL语句集合,我们可以从使用 prepared statements 获得很多好处,无论是性能问题还是安全问题。Prepared Statements 可以检查一些你绑定好的变量,这样可以保护你的程序不会受到“SQL注入式”攻击
7.垂直分表
8.选择正确的存储引擎
9.对于大数据字段,独立表进行存储,以便影响性能(例如:简介字段)
10.使用varchar类型代替char,因为varchar会动态分配长度,char指定长度是固定的。
11.给表创建主键,对于没有主键的表,在查询和索引定义上有一定的影响。
12.避免表字段运行为null,建议设置默认值(例如:int类型设置默认值为0)在索引查询上,效率立显!
13.建立索引,最好建立在唯一和非空的字段上,建立太多的索引对后期插入、更新都存在一定的影响(考虑实际情况来创建)。
【key和index的区别】
1.key 是数据库的物理结构,它包含两层意义和作用,一是约束(偏重于约束和规范数据库的结构完整性),二是索引(辅助查询用的)。包括primary key, unique key, foreign key 等
2.index是数据库的物理结构,它只是辅助查询的,它创建时会在另外的表空间(mysql中的innodb表空间)以一个类似目录的结构存储。索引要分类的话,分为前缀索引、全文本索引等;