数据分析师薪酬如何?爬虫拉勾网告诉你
首先说明这篇文章的数据来源,是爬虫拉勾网"数据分析师"这一职位信息所得来的。并且主要分析了数据分析师总体薪酬情况、不同城市薪酬分布、不同学历薪酬分布、北京上海工作经验薪酬分布情况、北上广深对数据分析职位需求量以及有招聘需求的公司所处行业的词云图分析。
阅读路线:
- 数据采集
- 数据清洗与处理
- 数据分析报告
- 分析结论
- 思考总结
数据采集
- 找到我们所要的信息位置
首先登录拉勾网,在顶端输入框内输入"数据分析师",点击搜索。按F12并且按F5刷新,就能看如图我们需要的内容。

要注意的这是火狐浏览器的界面并且爬虫程序是Python3环境下运行的。
- 开始上代码了
爬虫前所需要掌握的知识:Requests库的用法、Python字典与josn的异同、python基础
# -*- coding: UTF-8 -*-
import json
import requests
#headers内容,网页上会有,其中cooies就包括登录的效果,暂时简单理解为:拉勾网不会因为我们的操作频繁而阻止
headers = {
"Cookie": "user_trace_token=20171010163413-cb524ef6-ad95-11e7-85a7-525400f775ce; LGUID=20171010163413-cb52556e-ad95-11e7-85a7-525400f775ce; JSESSIONID=ABAAABAABEEAAJAA71D0768F83E77DA4F38A5772BDFF3E6; _gat=1; PRE_UTM=m_cf_cpt_baidu_pc; PRE_HOST=bzclk.baidu.com; PRE_SITE=http%3A%2F%2Fbzclk.baidu.com%2Fadrc.php%3Ft%3D06KL00c00f7Ghk60yUKm0FNkUsjkuPdu00000PW4pNb00000LCecjM.THL0oUhY1x60UWY4rj0knj03rNqbusK15yDLnWfkuWN-nj0sn103rHm0IHdDPbmzPjI7fHn3f1m3PDnsnH9anDFArH6LrHm3PHcYf6K95gTqFhdWpyfqn101n1csPHnsPausThqbpyfqnHm0uHdCIZwsT1CEQLILIz4_myIEIi4WUvYE5LNYUNq1ULNzmvRqUNqWu-qWTZwxmh7GuZNxTAn0mLFW5HDLP1Rv%26tpl%3Dtpl_10085_15730_11224%26l%3D1500117464%26attach%3Dlocation%253D%2526linkName%253D%2525E6%2525A0%252587%2525E9%2525A2%252598%2526linkText%253D%2525E3%252580%252590%2525E6%25258B%252589%2525E5%25258B%2525BE%2525E7%2525BD%252591%2525E3%252580%252591%2525E5%2525AE%252598%2525E7%2525BD%252591-%2525E4%2525B8%252593%2525E6%2525B3%2525A8%2525E4%2525BA%252592%2525E8%252581%252594%2525E7%2525BD%252591%2525E8%252581%25258C%2525E4%2525B8%25259A%2525E6%25259C%2525BA%2526xp%253Did%28%252522m6c247d9c%252522%29%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FH2%25255B1%25255D%25252FA%25255B1%25255D%2526linkType%253D%2526checksum%253D220%26ie%3Dutf8%26f%3D8%26ch%3D2%26tn%3D98010089_dg%26wd%3D%25E6%258B%2589%25E5%258B%25BE%25E7%25BD%2591%26oq%3D%25E6%258B%2589%25E5%258B%25BE%25E7%25BD%2591%26rqlang%3Dcn%26oe%3Dutf8; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F%3Futm_source%3Dm_cf_cpt_baidu_pc; _putrc=347EB76F858577F7; login=true; unick=%E6%9D%8E%E5%87%AF%E6%97%8B; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=63; TG-TRACK-CODE=index_search; _gid=GA1.2.1110077189.1507624453; _ga=GA1.2.1827851052.1507624453; LGSID=20171011082529-afc7b124-ae1a-11e7-87db-525400f775ce; LGRID=20171011082545-b94d70d5-ae1a-11e7-87db-525400f775ce; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507444213,1507624453,1507625209,1507681531; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1507681548; SEARCH_ID=e420ce4ae5a7496ca8acf3e7a5490dfc; index_location_city=%E5%8C%97%E4%BA%AC",
"Host": "www.lagou.com",
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.3408.400 QQBrowser/9.6.12028.400'}
post_data = {'first': 'false', 'kd':'数据分析师' }#这是请求网址的一些参数
def start_requests(pn):
html = requests.post(myurl + str(pn), data=post_data, headers=headers, verify=False)
html_text = html.text
content = json.loads(html_text) #loads()暂时可以理解为把json格式转为字典格式,而dumps()则是相反的
pagesize = content.get('content').get('pageSize') #这是Pytho字典中的get()用法
return pagesize
def get_result(pagesize):
for page in range(1, pagesize+1):
content_next = json.loads(requests.post(myurl + str(page), data=post_data, headers=headers, verify=False).text)
company_info = content_next.get('content').get('positionResult').get('result')
if company_info:
for p in company_info:
line = str(p['city']) + ',' + str(p['companyFullName']) + ',' + str(p['companyId']) + ',' + \
str(p['companyLabelList']) + ',' + str(p['companyShortName']) + ',' + str(p['companySize']) + ',' + \
str(p['businessZones']) + ',' + str(p['firstType']) + ',' + str(
p['secondType']) + ',' + \
str(p['education']) + ',' + str(p['industryField']) +',' + \
str(p['positionId']) +',' + str(p['positionAdvantage']) +',' + str(p['positionName']) +',' + \
str(p['positionLables']) +',' + str(p['salary']) +',' + str(p['workYear']) + '\n'
file.write(line)
if __name__ == '__main__':
title = 'city,companyFullName,companyId,companyLabelList,companyShortName,companySize,businessZones,firstType,secondType,education,industryField,positionId,positionAdvantage,positionName,positionLables,salary,workYear\n'
file = open('%s.txt' % '爬虫拉勾网', 'a') #创建爬虫拉勾网.txt文件
file.write(title) #把title部分写入文件作为表头
cityList = [u'北京', u'上海',u'深圳',u'广州',u'杭州',u'成都',u'南京',u'武汉',u'西安',u'厦门',u'长沙',u'苏州',u'天津',u'郑州'] #这里只选取了比较热门的城市,其他城市只几个公司提供职位
for city in cityList:
print('爬取%s' % city)
myurl = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city={}&needAddtionalResult=false&pn='.format(
city)
pagesize=start_requests(1)
get_result(pagesize)
file.close()
在pycharm上显示的效果大概就是这样的

其实这个爬虫部分的代码写的比较简单,运用知识主要是for循环,另外拉勾网对于我们请求的响应结果是json格式,也简化了我们的操作。操作的过程肯定会存在莫名的错误,大家要学会搜索并要有耐心啊。
数据的清洗与处理
对于刚刚上面txt格式文件,我另存为了csv格式,并要把中文名改成英文名称,不然下面读取的时候易出错
import pandas as pd
import numpy as np
#read_csv()表示读取csv格式文件,'gb2312'表示csv文件格式的编码
df=pd.read_csv('C:/Users/lkx941013/PycharmProjects/dataanalyis/DataAnalyst.csv',encoding='gb2312')
#读取前五行
df.head()
下面是从拉勾网 上抓取下来的数据,因为技术原因只能为大家粘贴一部分

从上面的图中,我们能看出关于工资方面应该做出处理,这里只是一个工资的区间,下面我们把工资清理成平均值形式
import pandas as pd
import numpy as np
df=pd.read_csv('C:/Users/lkx941013/PycharmProjects/dataanalyis/DataAnalyst.csv',encoding='gb2312')
#drop_duplicates()是去重函数,subset参数表示选择选择以哪个列为去重基准,数据集中positionId是职位ID,值唯一,所以选择positionId为基准。
df_duplicates=df.drop_duplicates(subset='positionId',keep='first')#keep='first'表示保留第一个,删除后面的重复值;keep='last'表示保留最后一个,删除前面的重复值
def cut_word(word,method):
position=word.find('-') #查找“7k-8k”这种形式"-"的位置
length=len(word)
if position !=-1: # "-1" 是False的意思,表示字符串中存在'-'
bottomsalary=word[:position-1]
topsalary=word[position+1:length-1]
else:
bottomsalary=word[:word.upper().find('K')] #这里是指不存在'10k-15k'这种形式,数据中存在7k以上,k有的大写有的小写
topsalary=bottomsalary
if method=="bottom": #获得工资下限
return bottomsalary
else:
return topsalary #获得工资的上限
df_duplicates['topsalary']=df_duplicates.salary.apply(cut_word,method="top") # apply()函数形式:apply(func,*args,**kwargs),*args相当于元组,**kwargs相当于字典
df_duplicates["bottomsalary"]=df_duplicates.salary.apply(cut_word,method="bottom")#apply()函数作用:用来间接的调用一个函数,并把参数传递给函数
df_duplicates.bottomsalary.astype('int')# 字符串转为数值型
df_duplicates.topsalary.astype('int')
df_duplicates["avgsalary"]=df_duplicates.apply(lambda x:(int(x.bottomsalary)+int(x.topsalary))/2,axis=1) #lambda是一种函数,举例:lambda x:x+1,x是参数,x+1是表达式;axis=1表示作用于行
df_duplicates
下面的图中,大家能够看到生成了一列平均的数值

这里的数据清洗工作完成的比较简单,当初数据采集的时候做了准备,估计工作后清洗会比较复杂。
数据分析
- 总体薪酬情况
df_clean=df_duplicates[['city','companyShortName','companySize','education','positionName','positionLables','workYear','avgsalary','industryField']]
import matplotlib.pyplot as plt
%matplotlib inline #%matplotlib inline是jupyter自带的方式,允许图表在cell中输出。
plt.style.use("ggplot") #使用R语言中的ggplot2配色作为绘图风格,为好看
from matplotlib.font_manager import FontProperties #matplotlib.Font_manager 是一种字体管理工具
zh_font = FontProperties(fname="C:\\WINDOWS\\Fonts\\simsun.ttc")#matplotlib.Font_manager.FontProperties(fname) 是指定一种字体,C:\\WINDOWS\\Fonts\\simsun.ttc 是字体路径,直接复制到电脑搜索,你看能不能找到
fig=plt.figure(figsize=(8,5)) #关于绘图方面,文末放了一个链接,讲述的比较详细
ax=plt.subplot(111)
rect=ax.hist(df_duplicates["avgsalary"],bins=30)
ax.set_title(u'薪酬分布',fontProperties=zh_font)
ax.set_xlabel(u'K/月',fontProperties=zh_font)
plt.xticks(range(5,100,5)) #xticks为x轴主刻度和次刻度设置颜色、大小、方向,以及标签大小。
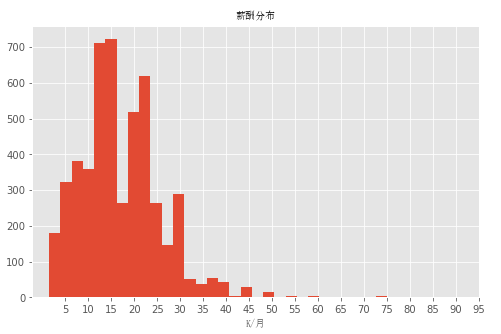
从上面的图中,我们可能很容易就能看出这是一个右分布。大多数10k-25k每月,当然也只有少数人获得了更高的薪酬。同时也期待大家能够成为那些薪酬极高的人。但这只是拉勾网显示的工资,实际情况就不知道了。
- 不同城市薪酬分布情况
ax=df_clean.boxplot(column='avgsalary',by='city',figsize=(9,7))
for label in ax.get_xticklabels():
label.set_fontproperties(zh_font)
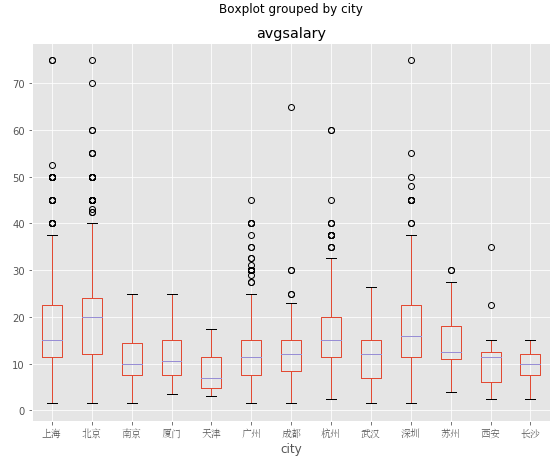
北京市薪酬分布中位数大约在20k,居全国首位。其次是上海、杭州、深圳,中位数大约为15k左右,而广州中位数只大约为12k。现在大家有没有想去北京发展了呢?说实话我是有点心动了。
- 不同学历的薪酬分布
ax=df_clean.boxplot(column='avgsalary',by='education',figsize=(9,7))
for label in ax.get_xticklabels():
label.set_fontproperties(zh_font)
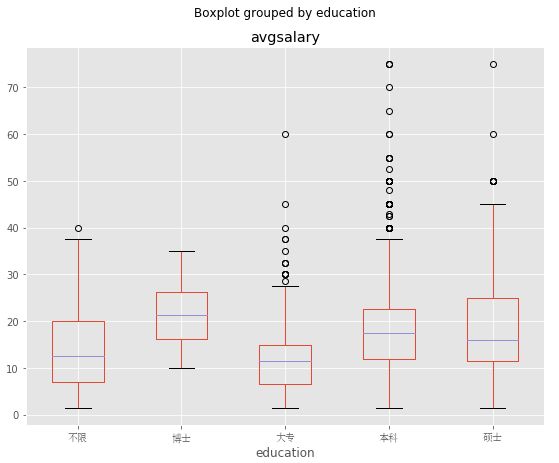
我们很容易看出来学历越高发展所获得工资是越高啊,博士薪资遥遥领先,但是在top区域不如本科和硕士,那么分析会不会存在一些问题呢?让我们先看一下招聘人数。
df_clean.groupby(['city','education']).avgsalary.count().unstack() #unstack()函数可进行行列转置,大家不妨去掉看下效果
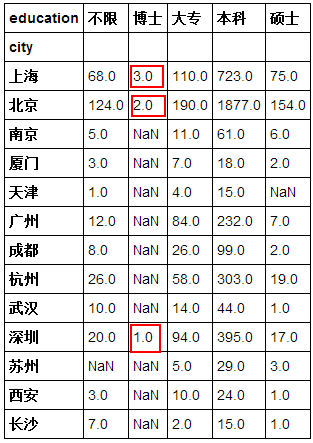
图上的结果很明确了,从图中我们能够明确的知道要求博士学历的岗位只有上海3个、北京2个、深圳1个,这6个职位要求,所以说薪资的总体范围和薪资中位数,就是完全依赖那几家公司的,波动性比较大。但回过头想一下,博士学历岗位只有6个呢,如果数据没有误的情况下,我的看法是:1. 高学历的数据分析师比较稀缺,他们不通过职业网站找工作而是被一些公司直接给挖走了;2. 高学历的研究生可能就不做数据分析了,他们可能从事数据挖掘、大数据分析架构或是人工智能方面了(一点灼见)
- 北京上海工作经验不同薪酬分布情况
对于方面经验不充足,但又想去北京和上海这两个城市发展的朋友们,用数据告诉你去哪个城市易于发展
df_bj_sh=df_clean[df_clean['city'].isin(['上海','北京'])]
ax=df_bj_sh.boxplot(column='avgsalary',by=['workYear','city'],figsize=(19,6))
for label_x in ax.get_xticklabels():
label_x.set_fontproperties(zh_font)
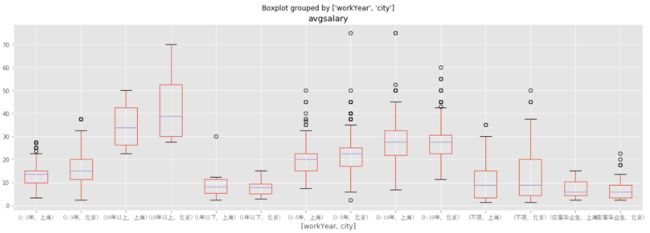
从图中我们能够得出,对于工作一年以下的,上海和北京两个地方薪资基本一致,但是有能力的人在北京能够得到较高的薪水。对于工作1-3年的人,北京工资的中位数都要比上海的上四分位数要大了。如果你的工作经验还不大充足,你想好去哪里发展了吗?(相应的,北京的互联网人才是比较多,竞争也比较激烈)
- 北上广深对数据分析职位需求量
def topN(df,n=5):
counts=df.value_counts() #value_counts()统计所有非零元素的个数
return counts.sort_values(ascending=False)[:n] #sort_values()对数据进行排序,ascending是设置升序和降序
df_bj_sh_gz_sz=df_clean[df_clean['city'].isin(['上海','北京','广州','深圳'])]
df_bj_sh_gz_sz.groupby('city').positionName.apply(topN)

我们现在可以看出,虽然想抓取的是数据师职位的情况,但得到的是和数据分析相关的职位,自己还是要在获取数据、数据清理方面多下功夫啊。
不管怎样我们还是能够得出来,观察北上广深的数据分析师职位数量,还是北京力压群雄啊。
- 公司所处行业领域词云图分析
import re #re模块提供了对正则表达式的支持
import jieba as jb
from wordcloud import WordCloud
word_str = ','.join(df_clean['industryField']) # 以','为分隔符,将所有的元素合并成一个新的字符串,注意:csv文件中,单元格之间有逗号。
#对文本进行分词
word_split = jb.cut(word_str) #精确模式
#使用|作为分隔符
word_split1 = "|".join(word_split)
pattern=re.compile("移动|互联网|其他|金融|企业|服务|电子商务|O2O|数据|服务|医疗健康|游戏|社交网络|招聘|生活服务|文化娱乐|旅游|广告营销|教育|硬件|信息安全")
#匹配所有文本字符;pattern 我们可以理解为一个匹配模式,用re.compile()方法来获得这个模式
word_w=pattern.findall(word_split1) #搜索word_split1,以列表形式返回全部能匹配的子串
word_s = str(word_w)
my_wordcloud = WordCloud(font_path="C:\\WINDOWS\\Fonts\\simsun.ttc",width=900,height=400,background_color="white").generate(word_s)
plt.imshow(my_wordcloud)
plt.axis("off") #取出坐标轴
plt.show()

如果仔细看得出来的这张云图有些怪怪的,怎么都有重复的词汇呢?我想着应该是分词的问题,一时半会没有解决,就暂时用了BDP个人版制作云图了。效果如下,但也不是太理想,所以接下来也要仔细研究下制作云图了。

如图所示:对于数据分析这一职位需求量大的主要是在互联网、移动互联网、金融、电子商务这些方面,所以找工作的话去这几个领域获得职位的几率估计是比较大的。我想这可能还有另一方面的原因:拉勾网本身主要关注的就是互联网领域,等自己技术成熟了,要爬虫获得一份包含所有行业的数据进行一次分析。
分析结论
从总体薪酬分布情况上,数据分析这一职业工资普遍较高的,大多人是在10k-25之间每月,但这只是拉勾网显示的工资,具体的就不太清楚了。
从不同城市薪资分布情况得出,在北京工作的数据分析师工资中位数在20k左右,全国之首。其次是上海、杭州、深圳,如果要发展的话,还是北、上、深、杭比较好啊。
从不同学历薪资情况得出,学历越高发展所获得工资是越高,其中专科生略有劣势,我想的是数据分析应该对数学有一定要求,毕竟大学是学了数理统计、高等数学还线性代数的。
根据北京上海工作经验不同薪酬分布情况,得出如果有些工作经验去北京比上海获得的工资要高一些。
分析北上广深的数据分析师职位需求数量,北京以238个获得最高。
根据公司所处行业领域词云图分析,对于数据分析师需求量大的行业主要是互联网、电子商务、金融等领域。
思考总结
今天这篇文章进行了更新,主要是用爬虫获得了数据分析师职位信息,其实是多亏了猴哥昨天说"可以学会爬虫",我当时在想,猴哥可能认为我能做到,哈哈,自恋了。这篇文章的制作云图方面,出现了云图上的字有重复现象,接下来还是要弄清楚jieba分词原理和使用。在分析问题方面,还没有做到维度细分,分析思路方面还有很大欠缺,接下来要看一些分析报告。对于这篇文章,大家发现了问题,要多多指教啊,肯定及时更正。
福利1:如果爬虫没有实现的话,可暂时用这份数据进行 练习
福利2:numpy、pandas、matplotlib的使用