DensePose:Dense Human Pose Estimation In The Wild 论文阅读笔记

一、本文主要是Facebook AI 和INRIA 联合出品,基于RCNN架构,以及Mask RCNN的多任务结构,开源http://densepose.org
二、主要工作分为三点
1:标注了一个新的数据集,基于coco数据集,增加了uv标注,该数据集开源。
2:设计了一个框架可以用于输出uv坐标。
3、设计了一个“teacher”结构的监督网络训练方式。
三:数据集介绍:
1、名称“COCO-Densepose-dataset”。
2、图片来源于MSCOCO,挑选了50K个人,标注了近5百万的标注点。测试集“1.5k images,2.3k humans”,训练集“48k humans”
3、文章中还介绍了,他们的标注系统,以及标注采集方式,同时也点了下对标注进行评估。他们在对2D图像进行标注的时候,主要是去标注“人体表面的一些‘顶点’”比如右鼻孔外侧的左下角.2D与3D体表模型点对应关系如下图中task2所示。“标注的时候让标注者 假设透视衣服”,对标注者标注每个部位的时候提供6个参考示意图。
4、该数据集还包含了人体部位分割。
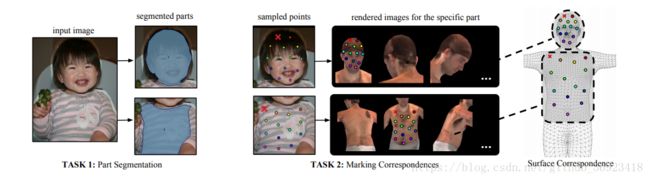


5、标注上了UV坐标之后,可以将一个3D人物的表面经过变换投影到2D图像上,并且会根据2D图像中人物的姿态做适当的变换,从而使得3D模型的表面可以做到紧贴2D人物。

![]()
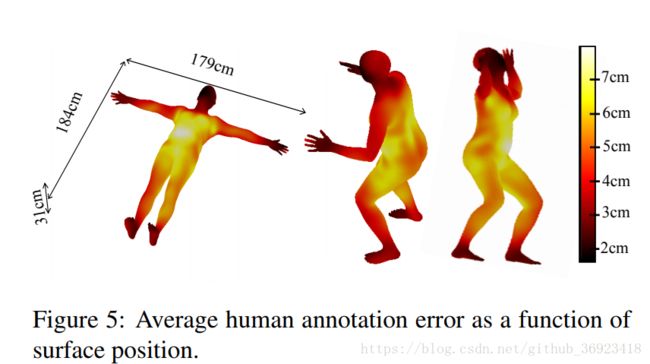
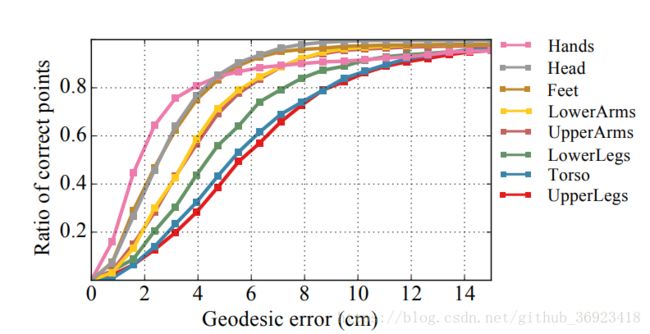
这张图主要告诉我们,人类标注者标注的平均误差,以及误差大小的分布情况。
三、Densepose Evaluation
Pointwise evaluation:
这个内容主要适用于计算在整个图片样本域上的ratio of correct point(RCP),通过设定阈值,如果估计点与gt点的geodesic distance小于阈值就记为正确。同时也计算AUC,分为AUC10,AUC30,AUC10在单人和多人中都有使用。
Per-instance evaluation:
类似于OKS(object keypoint similarity):本文采用了geodesic point similarity(GPS)用于匹配点的打分。
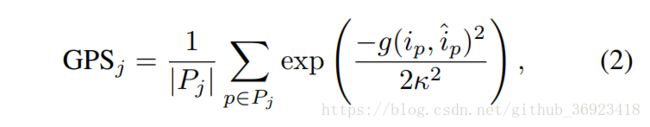
上面公式中,Pj是gt集合对应于每一个人,ip是对于每一个点的估计的位置,k=0.255.
会使用AP以及AR,设定阈值从0.5到0.95,代表了距离大约是0~30cm。
数据集介绍这部分还不是很清楚,等我用过之后,会更新一下。
三、框架
该模型是基于caffe2框架的。
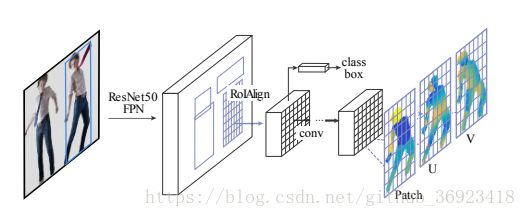
1、输出三个内容 身体部位分割,U 以及 V
其实就是去将2D图像中人的表面的像素投影到3D人体表面上,也可以在估计出图像中人体的UV之后,将3Dmodel通过变换,将空间坐标转换为UV坐标之后,贴到图像上。
截至到这里,基本的densepose也就这样了,在第一阶段获得了ROI之后,经过ROIAlign之后,去回归三个部分。
a.首先本文给出了人类标注的错误分布情况图,也是为了能让大家意识到数据集存在着一些不可避免地错误,也是为了能跟后面的model的结果作比较。
b.正如网络结构图所示,在densepose这部分采用了FCN结构,这一点也是因为以前有人证明过卷积核拥有着不错的分类功能。在网络的细节上,采用了局部化处理回归,首先进行二分类,得出前景与背景,然后将前景再进行细分成各个不同的身体部位进行分别回归,因此也会建立局部的二维坐标系。
其实他回归这些UV坐标也是分了两个步骤的,第一个步骤先要去进行身体部位的回归分类,分为了24+1类,然后再对每一个去回归出U,V两个feature maps。
c、
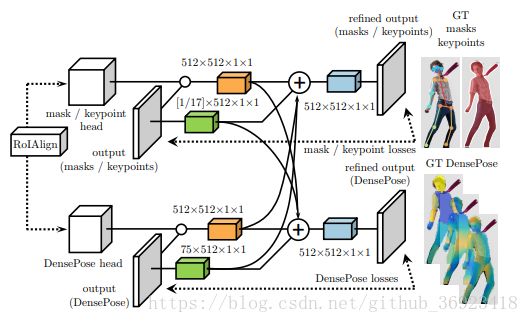
利用了多任务的Multi-task cascaded architectures结构,将 mask 和 keypoint的输出特征 与 densepose 的特征 互相融合训练。而且也可以看出来使用了多stage的思想,进行“中继监督”训练。
d、“teacher net” 对整体进行辅助训
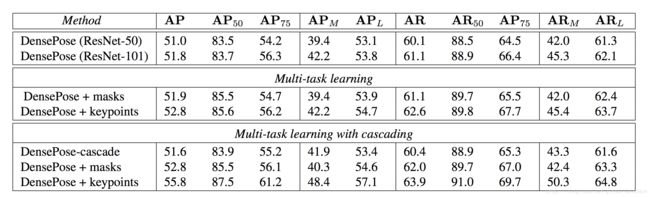
五、实验结果