Python3爬虫实践--网易科技滚动新闻爬取
背景需求
完成作业的同时练习爬虫,利用Xpath匹配出需要爬取的内容;
需要爬取的新闻界面
需要爬取的信息

实现代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/3/13 13:08
# @Author : cunyu
# @Site : cunyu1943.github.io
# @File : NetaseNewsSpider.py
# @Software: PyCharm
import requests
from lxml import etree
import xlwt
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36"
}
# 根据url获取刚网页中的新闻详情页的网址列表
def getNewsDetailUrlList(url):
"""
:param url: 每页的URL
:return newDetailList:每页包含的新闻详情URL
"""
response = requests.get(url, headers=headers)
html = response.content.decode('gbk')
selector = etree.HTML(html)
newsDetailList = selector.xpath('//ul[@id="news-flow-content"]//li//div[@class="titleBar clearfix"]//h3//a/@href')
return newsDetailList
# 获取新闻标题
def getNewsTitle(detailUrl):
"""
:param detailUrl:新闻详情url
:return newsTitle:新闻标题
"""
response = requests.get(detailUrl, headers=headers)
html = response.content.decode('gbk')
selector = etree.HTML(html)
newsTitle = selector.xpath('//div[@class="post_content_main"]//h1/text()')
return newsTitle
# 获取新闻详情内容
def getNewsContent(detailUrl):
"""
:param detailUrl: 新闻详情url
:return newsContent: 新闻内容详情
"""
response = requests.get(detailUrl, headers=headers)
html = response.content.decode('gbk')
selector = etree.HTML(html)
newsContent = selector.xpath('//div[@class="post_text"]//p/text()')
return newsContent
# 将新闻标题和内容写入文件
TODO
# 获取翻页网址列表
def getUrlList(baseUrl, num):
"""
:param baseUrl:基础网址
:param num: 翻到第几页
:return urlList: 翻页网址列表
"""
urlList = []
urlList.append(baseUrl)
for i in range(2, num+1):
urlList.append(baseUrl + "_" + str(i).zfill(2))
return urlList
if __name__ == '__main__':
baseUrl = "http://tech.163.com/special/gd2016"
num = int(input('输入你要爬取的页数: '))
urlList = getUrlList(baseUrl, num)
print(urlList)
detailUrl = []
for url in urlList:
for i in getNewsDetailUrlList(url):
detailUrl.append(i)
print(detailUrl)
print(getNewsTitle(detailUrl[0]))
print(getNewsContent(detailUrl[0]))
# # 将爬取的文本存入文本文件
# with open('news.txt', 'w', encoding='utf-8') as f, open('newsTitle.txt', 'w', encoding='utf-8') as titleFile,\
# open('newsContent.txt', 'w', encoding='utf-8') as contentFile:
# print('正在爬取中。。。')
# for i in detailUrl:
# f.write(''.join(getNewsTitle(i)))
# f.write('\n')
# f.write(''.join(getNewsContent(i)))
# f.write('\n')
#
# titleFile.write(''.join(getNewsTitle(i)))
# titleFile.write('\n')
#
# contentFile.write(''.join(getNewsContent(i)))
# contentFile.write('\n')
#
# print('文件写入成功')
# 将爬取得文本存入excel文件
# 创建一个Excel文件
workbook = xlwt.Workbook(encoding='utf-8')
news_sheet = workbook.add_sheet('news')
news_sheet.write(0, 0, 'Title')
news_sheet.write(0, 1, 'Content')
print('正在爬取中。。。')
for i in range(len(detailUrl)):
# print(detailUrl[i])
news_sheet.write(i + 1, 0, getNewsTitle(detailUrl[i]))
news_sheet.write(i + 1, 1, getNewsContent(detailUrl[i]))
# 将写入操作保存到指定Excel文件中
workbook.save('网易新闻.xls')
print('文件写入成功')
结果
-
代码运行结果
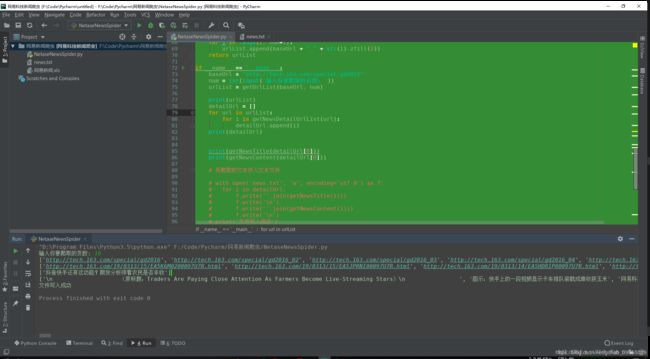
-
保存的文件
总结
总体来说比较简单,代码也存在需要改进的地方,后续会改进更新,有其他想法的也可以相互交流!