keras瞎搞系列-从LeNet到SENet——卷积神经网络回顾
本文转自:https://zhuanlan.zhihu.com/p/33845247
keras瞎搞系列-从LeNet到SENet——卷积神经网络回顾
从1998年经典的LeNet,到2012年历史性的AlexNet,之后深度学习进入了蓬勃发展阶段,百花齐放,大放异彩,出现了各式各样的不同网络,包括LeNet、AlexNet、ZFNet、VGG、NiN、Inception v1到v4、Inception-ResNet、ResNet、WRN、FractalNet、Stochastic Depth、DenseNet、ResNeXt、Xception、SENet、SqueezeNet、NASNet、MobileNet v1和v2、ShuffleNet等等。
它们各有特点,也互相借鉴,在很多任务上不断取得突破。本文从最基本的分类任务的角度,从无人问津到ImageNet上超越人类,回顾了卷积神经网络的发展历史。
经典网络
经典网络包括LeNet、AlexNet以及VGG等。
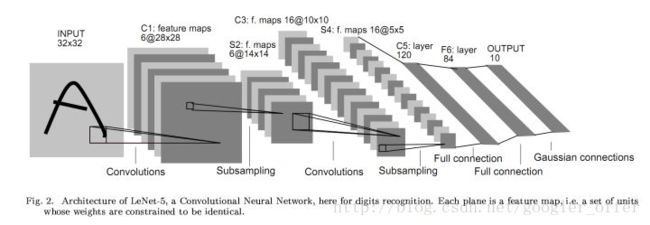
LeNet:1998,Gradient based learning applied to document recognition
用于手写数字识别,可以看到,卷积神经网络的基本框架已经有了,卷积、激活、池化和全连接,这几个基本组件都完备了。
但是,在1998年以后,深度学习并没有太多的突破。一直沉寂到2012年,AlexNet横空出世,将深度学习重新带入大家视线,并开启了深度学习的黄金时代。
为什么是2012年?一是数据,之前并没有大规模的数据进行充分的训练,应用于更广泛的任务,现在有ImageNet;二是计算,之前的硬件条件限制了,无法进行大规模的训练,而现在有了性能强大的GPU的加成;三就是AlexNet本身很优秀,给后来的网络奠定了一个很好的基础,让大家突然发现,原来还可以这样玩!
AlexNet:2012,ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Top5错误率:16.4%,而两年前非深度学习的方法的最好错误率是28.2%
AlexNet总体结构和LeNet相似,但是有极大改进:
- 由五层卷积和三层全连接组成,输入图像为三通道224x224大小,网络规模远大于LeNet
- 使用了ReLU激活函数
- 使用了Dropout,可以作为正则项防止过拟合,提升模型鲁棒性
- 一些很好的训练技巧,包括数据增广、学习率策略、weight decay等
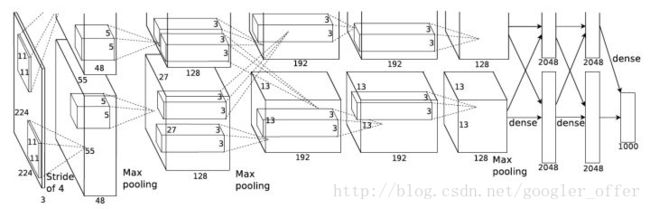
AlexNet使用3GB显存的GTX 580显卡(好古老),一块显卡不够用,所以如上图所示将模型分为两部分放到了两块显卡上并行运算。虽然这仅仅是单块显卡资源有限时的做法,但是后面的许多网络都进一步发扬了这种对卷积进行分组的思想(虽然动机不同)。
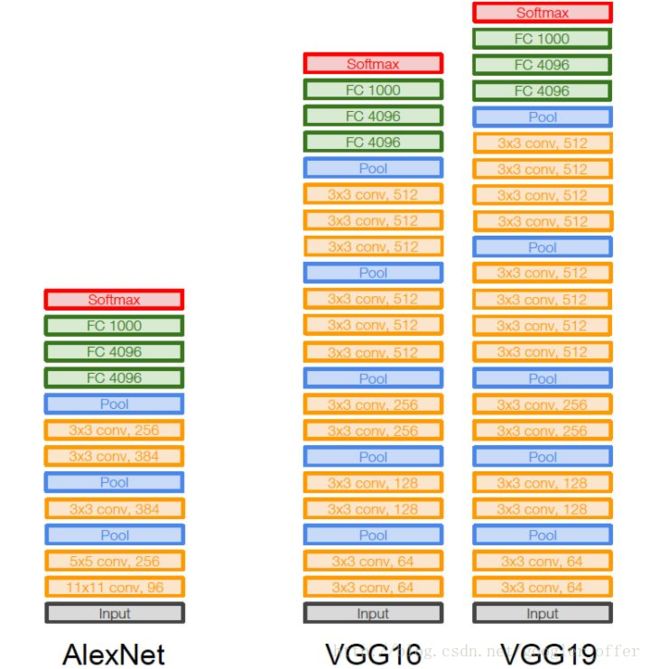
VGG:2014,Very deep convolutional networks for large-scale image recognition
在AlexNet之后,另一个提升很大的网络是VGG,ImageNet上Top5错误率减小到7.3%。
主要改进就是:深,更深!网络层数由AlexNet的8层增至16和19层,更深的网络意味着更强大的网络能力,也意味着需要更强大的计算力,还好,硬件发展也很快,显卡运算力也在快速增长,助推深度学习的快速发展。
同时只使用3x3的卷积核,因为两个3x3的感受野相当于一个5x5,同时参数量更少,之后的网络都基本遵循这个范式。
GoogLeNet和ResNet
一层一层卷积堆叠,VGG是集大成者,但是之后很难再进一步,继续简单增加网络层数会遇到问题,更深的网络更难训练同时参数量也在不断增长。
Inception v1(GoogLeNet):2015,Going deeper with convolutions
ImageNet Top5错误率6.7%
GoogLeNet则从另一个维度来增加网络能力,每单元有许多层并行计算,让网络更宽了,基本单元如下:
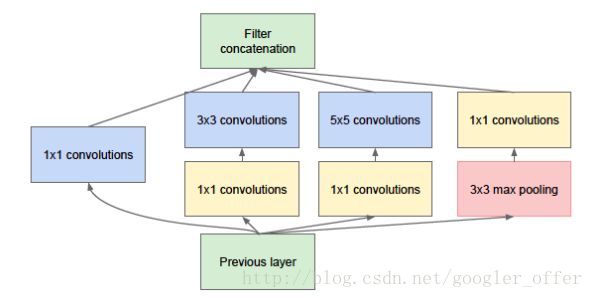
网络总体结构如下所示,包含多个上面的Inception模块,并添加了两个辅助分类分支补充梯度更好训练:
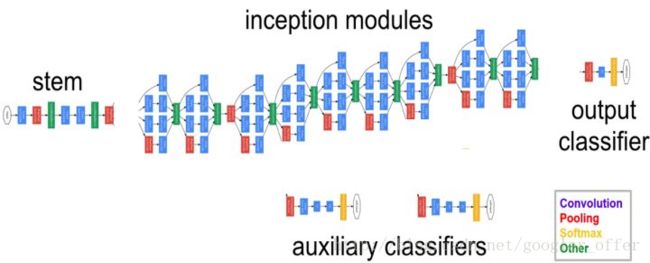
通过网络的水平排布,可以用较浅的网络得到很好的模型能力,并进行多特征融合,同时更容易训练,另外,为了减少计算量,使用了1x1卷积来先对特征通道进行降维。堆叠Inception模块而来就叫Inception网络,而GoogLeNet就是一个精心设计的性能良好的Inception网络(Inception v1)的实例,即GoogLeNet是Inception v1网络的一种。
但是,网络太深无法很好训练的问题还是没有解决,直到ResNet提出了residual connection。
ResNet:2016,Deep residual learning for image recognition
ImageNet Top5错误率3.57%
ResNet通过引入shortcut直连来解决这个问题:
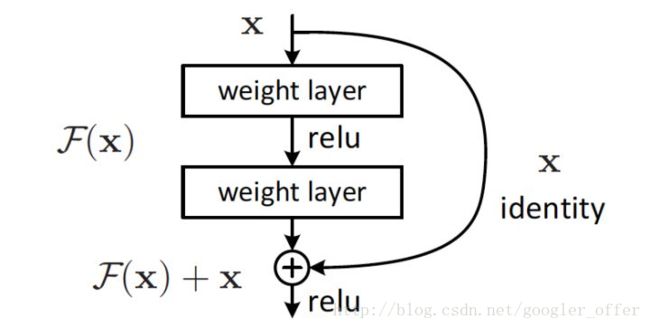
通过引入直连,原来需要学习完全的重构映射,从头创建输出,并不容易,而引入直连之后,只需要学习输出和原来输入的差值即可,绝对量变相对量,容易很多,所以叫残差网络。并且,通过引入残差,identity恒等映射,相当于一个梯度高速通道,可以容易地训练避免梯度消失的问题,所以可以得到很深的网络,网络层数由GoogLeNet的22层到了ResNet的152层。
ResNet-34的网络结构如下所示:
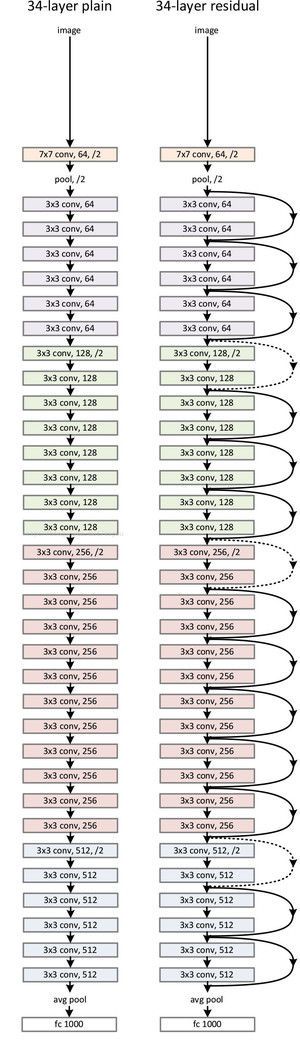
如果说LeNet、AlexNet、VGG奠定了经典神经网络的基础,Inception和ResNet则展示了神经网络的新范式,在这两个范式的基础上,发展创新并相互借鉴,有了Inception流派的Inception v2到v4、Inception-ResNet v1和v2,以及ResNet流派的ResNeXt、DenseNet和Xception等。
Inception流派
Inception流派,核心就是Inception模块,出现了各种变种,包括Inception v2到v4以及Inception-ResNet v1和v2等。
Inception v2(BN-Inception):2015,Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
ImageNet Top5错误率:4.8%
(PS:按照Inception系列四篇论文中的第三篇论文的划分,类似于Inception v3的一个网络称之为v2,但是按照第四篇论文的划分,BN-Inception称之为v2,这里采用第四篇论文的划分,Inception v2指BN-Inception)
主要是增加了Batch Normalization,之前神经网络很依赖于良好的初始化,并且网络太深会梯度弥散,这两个问题都是因为网络中间的激活的分布不理想,那既然我们想要一个理想的分布,就手动把它转换为理想的分布好了。所以在每一层输出后面加上了归一化变换,减去每个训练batch的每个特征的均值再除以标准差,得到0均值1标准差的输出分布,这样,就可以很好地训练了,梯度也不容易弥散。
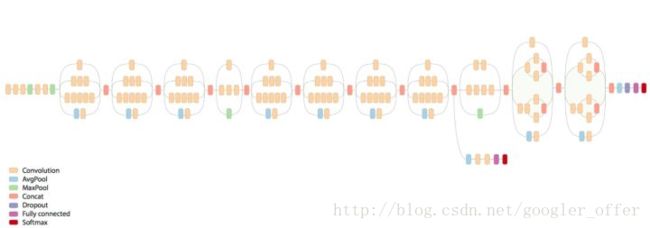
Inception v3:2015,Rethinking the Inception Architecture for Computer Vision
ImageNet Top5错误率:3.5%
卷积进一步分解,5x5用两个3x3卷积替换,7x7用三个3x3卷积替换,一个3x3卷积核可以进一步用1x3的卷积核和3x1的卷积核组合来替换,进一步减少计算量:
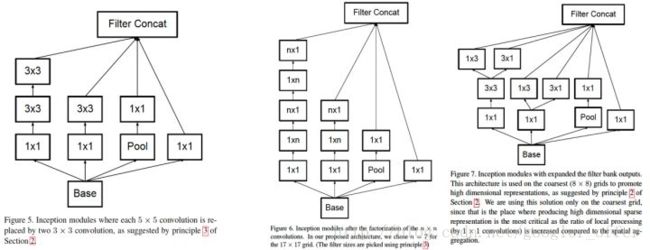
总体地网络结构如下所示:
Inception v4、Inception-ResNet v1和v2:2016,Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
ImageNet Top5错误率:3.08%
Inception v1到v3,可以看到很明显的人工设计的痕迹,不同卷积核的和网络结构的安排,很特殊,并不知道为什么要这样安排,实验确定的。作者称由于以前受硬件软件的限制,有太多的历史包袱,而现在有了TensorFlow(论文里怒打一波广告),网络可以按照理想的设计来实现了,于是很规范地设计了一个Inception v4网络,类似于Inception v3,但是没有很多特殊的不一致的设计。
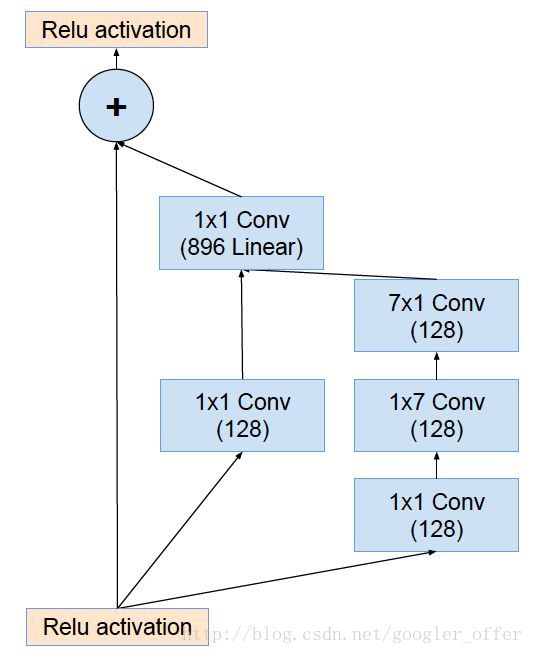
同时,ResNet的成功,也说明了residual connection的有效性,所以为Inception模块引入了residual connection,得到Inception-ResNet v1和Inception-ResNet-v2,前者规模较小,和Inception v3相当,后者规模较大,和Inception v4规模相当。residual结构地Inception模块如下所示:
ResNet流派
ResNet流派是另一个主流分支,包括WRN、DenseNet、DPN、ResNeXt以及Xception等。
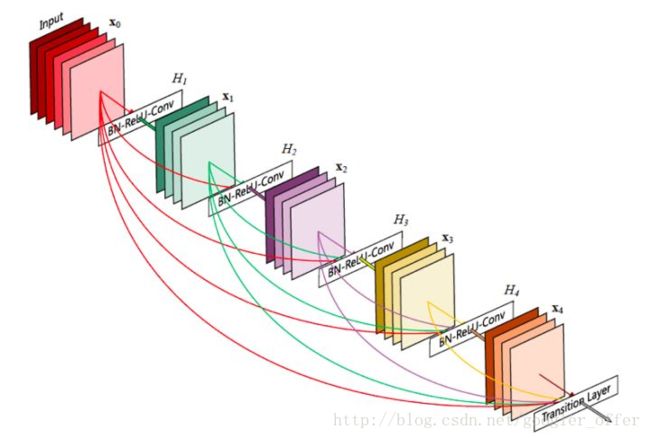
DenseNet:2016,Densely Connected Convolutional Networks
DenseNet将residual connection发挥到极致,每一层输出都直连到后面的所有层,可以更好地复用特征,每一层都比较浅,融合了来自前面所有层的所有特征,并且很容易训练。缺点是显存占用更大并且反向传播计算更复杂一点。网络结构如下所示:
ResNeXt:2017,Aggregated Residual Transformations for Deep Neural Networks
ImageNet Top5错误率:3.03%
Inception借鉴ResNet得到Inception-ResNet,而ResNet借鉴Inception得到了ResNeXt,对于每一个ResNet的每一个基本单元,横向扩展,将输入分为几组,使用相同的变换,进行卷积:
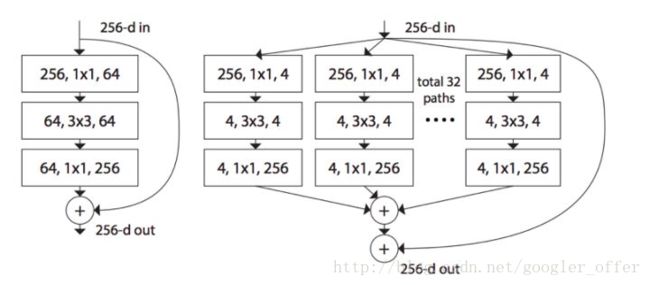
上面左边是ResNet,右边是ResNeXt,通过在通道上对输入进行拆分,进行分组卷积,每个卷积核不用扩展到所有通道,可以得到更多更轻量的卷积核,并且,卷积核之间减少了耦合,用相同的计算量,可以得到更高的精度。
Xception:2016,Xception: Deep Learning with Depthwise Separable Convolutions
Xception则把分组卷积的思想发挥到了极致,每一个通道单独分为一组。利用了depthwise separable convolution,如下图所示,J个输入通道,每个通道用一个单独的空间卷积核卷积(比如3x3),J个卷积核得到J个输出通道,然后再用K个卷积核对上一步得到的J个输出通道进行1x1的普通卷积,得到K个最终的输出:
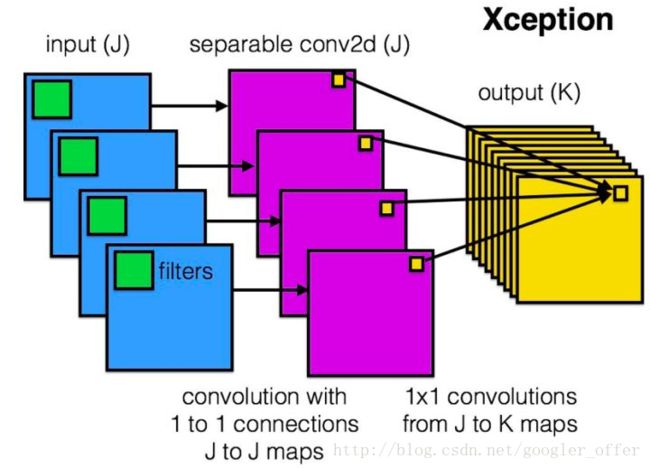
Xception基于一个假设,水平和竖直方向的空间卷积(比如第一步的3x3卷积)和深度方向的通道卷积(比如第二步的1x1卷积)可以完全独立进行,这样减少了不同操作间的耦合,可以有效利用计算力。实验证明,相同的计算量,精度有明显的提升。(不过现在对于分组卷积的底层支持还不够好,实际速度并没有理论计算的那么好,需要底层库进行更好的支持)
移动端
除了主流的ResNet流派和Inception流派不断追求更高的准确率,移动端的应用也是一大方向,比如SqueezeNet、MobileNet v1和v2、ShuffleNet等。
MobileNet v1:2017,MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
和Xception类似,通过depthwise separable convolution来减少计算量,设计了一个适用于移动端的,取得性能和效率间很好平衡的一个网络。
MobileNet v2:2018,Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation
使用了ReLU6(即对ReLU输出的结果进行Clip,使得输出的最大值为6)适配移动设备更好量化,然后提出了一种新的Inverted Residuals and Linear Bottleneck,即ResNet基本结构中间使用了depthwise卷积,一个通道一个卷积核,减少计算量,中间的通道数比两头还多(ResNet像漏斗,MobileNet v2像柳叶),并且全去掉了最后输出的ReLU。具体的基本结构如下图右侧所示:
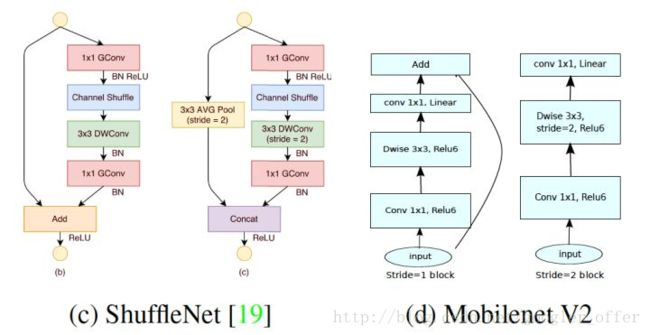
ShuffleNet:2017,ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
Xception已经做得很好了,但是1x1那里太耗时间了成了计算的瓶颈,那就分组啦较少计算量,但是分组了,组和组之间信息隔离了,那就重排shuffle一下,强行让信息流动。具体的网络结构如上图左侧所示。channel shuffle就是对通道进行重排,将每组卷积的输出分配到下一次卷积的不同的组去:
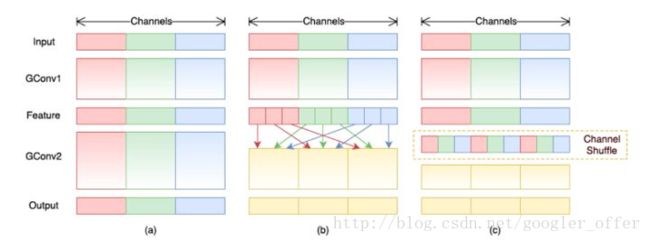
上图的a是没有shuffle,效果很差,b和c则是等价的有shuffle的。ShuffleNet可以达到和AlexNet相同的精度,并且实际速度快13倍(理论上快18倍)。
SENet
除了上面介绍的久经考验的网络以外,还有各种各样的新的网络,比如NASNet、SENet、MSDNet等等。其中,SENet的Squeeze-Excitation模块在普通的卷积(单层卷积或复合卷积)由输入X得到输出U以后,对U的每个通道进行全局平均池化得到通道描述子(Squeeze),再利用两层FC得到每个通道的权重值,对U按通道进行重新加权得到最终输出(Excitation),这个过程称之为feature recalibration,通过引入attention重新加权,可以得到抑制无效特征,提升有效特征的权重,并很容易地和现有网络结合,提升现有网络性能,而计算量不会增加太多。
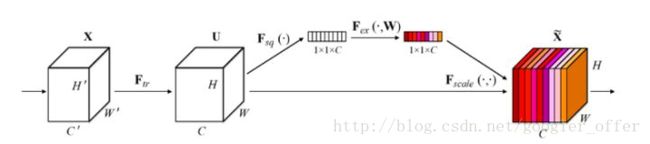
SE module是一个很通用的模块,可以很好地和现有网络集成,提升现有效果。
总结
最后,一个ImageNet上的Top5准确率总结表如下图,可以看到,ImageNet上的分类错误率逐年降低,并且已经低于人类的错误率(5.1%)。
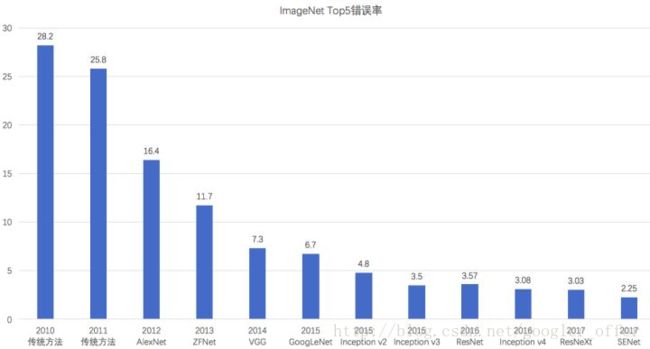
有这么多网络,具体的使用中到底选哪个呢?个人的使用参考建议是:
- 普通网络:推荐ResNet-50或Xception或Inception v3
- 大网络高精度:推荐ResNeXt-101(64x4d)或Inception-ResNet v2或DPN
- 移动端小网络:推荐ShuffleNet或MobileNet v2
还可以额外添加SENet模块到现有网络,基本都能进一步提高精度,计算量略有增加。另外也可以尝试一下NASNet。
强烈推荐该作者的知乎专栏:https://zhuanlan.zhihu.com/xfanplus