这篇文章要在GANs圈里C位出道了(内附源码与资源链接)
来源 | Google Brain
译者 | Linstancy
编辑 | Jane
出品 | 人工智能头条(公众号ID:AI_Thinker)
【导读】生成对抗网络(GANs) 是一类深度生成模型,旨在以无监督方式来学习目标的分布。虽然这类模型已成功应用并解决很多问题,但由于需要大量超参数微调、神经网络结构的设计及众多训练技巧等原因,导致GANs 的训练一直以来是个很大的挑战。为了解决GANs 的量化标准以及对其失败模式分析等问题,许多研究者提出了一系列损失函数、正则化方法、归一化及不同的网络结构来解决GANs 模型的量化标准问题并试图从其失败模式中找到有效的解决方案。本文中,我们将从实践的角度清醒地认识当前GANs 的研究现状。通过复现一些性能最佳的模型,来探索当前整个 GANs 的研究情况。此外,我们进一步讨论了GANs 模型一些常见的陷阱(pitfall) 及复现问题。最后,我们在GitHub 开源了本文的研究项目,并在TensorFlow Hub 上提供了预训练的模型。
前言
GANs 是一种深度生成模型,它主要以无监督的方式来学习目标的分布,并在多种应用中展示了巨大的潜力,特别在自然图像处理领域。GANs 模型可以看作是一种二人的博弈游戏,其中一个玩家(生成器)学习简单的输入分布(通常是标准的多变量高斯分布或均匀分布)并将其变换生成图像空间上的分布,而另一个玩家(判别器)尝试将真实分布和生成分布区分开来。二者在训练的过程互相对抗,互相博弈,它们都试图最小化各自的损失目标并最终达到纳什均衡。而这种框架通常可以通过最小化模型分布和真实分布之间的统计差异性来得到。
训练 GAN 的目的是尝试在生成器和判别器的参数空间上寻求一个极小极大问题。由于生成器和判别器通常都被参数化为深度卷积神经网络结构(CNNs),因此我们很难在实践中解决这个极小极大问题。对此,众多研究者提出一系列的损失函数、正则化方法、归一化及不同的模型结构。其中一些方法是从理论导的角度推导,而还有些是基于实践应用的考虑。
本文,我们的主要是对这些方法进行全面系统的总结和分析,帮助并引导领域的研究者和实践者开展相关的研究,将分别从以下几个方面进行分析:包括 GANs 的损失函数、正则化和归一化方法,及一些常用的模型结构等。随后,通过一些大规模的数据集,我们尝试利用超参数优化方法和高斯回归过程来探索模型的超参数空间,考量并验证模型的最佳超参数集合。我们得到如下结论:
对不同损失函数的影响分析表明非饱和损失在不同的数据集、模型结构和超参数组合中都能表现得足够稳定。
对不同正则化、正则化方法及模型结构的影响分析表明梯度惩罚(gradient clipping, GP)和光谱正则化(spectrum normalization, SN)方法能在深度生成对抗模型中发挥重要作用,二者同时使用能够进一步改善模型表现。
最后,我们还考虑了一些常见的 GANs 模型陷阱、复现问题和实践应用,并将研究项目开源在 Github,你也可以通过 TensorFlow Hub 来获取我们的预训练模型。
GANs 技术全景图(GAN Landscape)
这里,我们主要总结了 GANs 模型的各种变体结构,并从损失函数、正则化和归一化方法、网络模型结构、模型评估度量及数据集等方面来进一步讨论了 GANs 的研究进展。以下所涉及到的详细内容可以参见我们的原论文。
▌损失函数(Loss Function)
对于 GANs 的损失函数,我们比较了原始 GANs 中用到的 JS 距离、WGANs 中用到的 Wasserstein 距离和 LSGANs 中用到的最小二乘(Least Square, LS)损失函数。
▌归一化和正则化方法(Regularization and Normalization)
对于 GANs 中判别器的正则化方法,我们主要分析了梯度惩罚方法(gradient clipping, GP),这是 WGAN 中提出的一种用于对违反1-Lipschitzness 平滑的软惩罚技术。不仅如此,这种正则化技术还能使得模型根据数据流形(data manifold)来评估 GP,并在流形空间上进行分段线性正则化。
对于GANs 中判别器的归一化方法,我们主要分析了模型最优化与特征表征。好的归一化方法不仅能够获得更高效的梯度流与更稳点的优化过程,还能修正各权重矩阵的光谱结构(spectral structure)以便获得更丰富的层次特征。
▌模型结构(Generator and Discriminator Architecture)
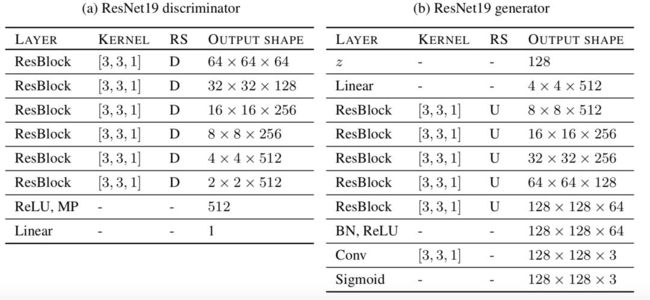
对于 GANs 中生成网络和对抗网络的结构,我们主要分析了包括深度卷积生成对抗网络和残差生成对抗网络两种结构。具体地说,深度卷积生成对抗网络中生成器和判别器分别采用 5 层卷积,并引入光谱正则化方法,这种变体我们称为 SNDCGAN。对于残差生成对抗网络中,我们采用 ResNet19 模型,在生成器中包含 5 个残差模块(ResNet block),而判别器包含 6 个残差模块。
▌评估标准(evaluation metric)
对于 GANs 的评估标准,我们主要分析了 Inception Score(IS)、Frechet Inception Distance(FID)、Kernel Inception distance(KID)和 Multi-scale Structural Similarity for Image Quality(MS-SSIM)等四种度量,这些都是模型的定量分析标准。
▌数据集(data sets)
对于 GANs 所使用的数据集,我们主要考虑了三种广泛使用的大规模数据集;CIFAR10、CELEBA-HQ-128 和 LSUN-BEDROOM,并分别在上面测试各种 GANs 模型的生成表现。

GANs在 CELEBA-HQ-128 数据集上的生成示例

GANs在 LSUN-BEDROOM 数据集上的生成示例

GANs在 CIFAR10 数据集上的生成示例
资源链接:
https://github.com/tkarras/progressive_growing_of_gans.
▌GANs 的搜索空间
由于不用的损失函数,正则化和归一化方法以及模型结构的组合选择过多,超参数的搜索空间可能会超出模型的容量,因此我们在三个数据集中主要实验并分析了以下一些重要的组合,如下表。

本研究中所使用的组合方案、超参数范围。带固定值的笛卡尔乘积(Cartesian product)能够反映出未包含的结果。高斯优化过程中 bandit 设置被用于在特定范围中筛选中更好的超参数设置。



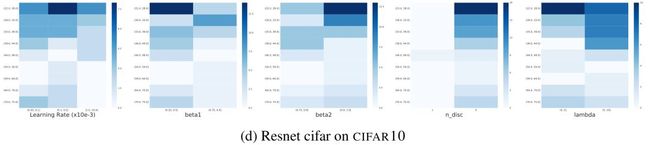
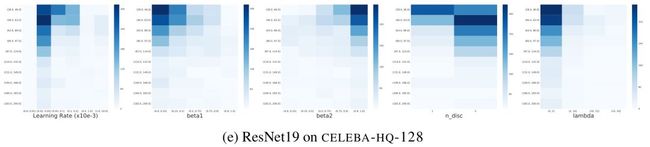

对每个框架和数据集组合的超参数进行热图
结果和讨论
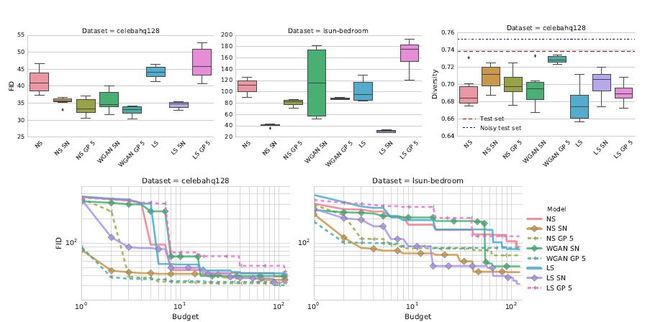
对于每个数据集,我们采用控制实验的方式来开展我们的探索过程,即固定某种因素的影响,通过改变其他因素的条件来得到分析结果。每组实验中,我们重点分析已训练模型的 top 5% FID 分布、对应的样本多样性分数以及计算成本(即训练的模型数量)与 FID 度量(模型生成质量)之间的权衡,并得到以下分析结果。
▌损失函数的影响
我们实验分析了非饱和损失函数(NS),最小二乘损失函数(LS) 以及Wasserstein 损失函数(WGAN)。实验中采用 ResNet19 作为生成器和判别器的模型结构。
参考链接:
https://github.com/ pfnet-research/sngan_projection
这里我们主要讨论梯度惩罚(GP) 和光谱正则化(SN)方法,并在CELEBA-HQ-128 和 LSUN-BEDROOM 数据集上进行实验,实验结果如下图。

损失函数影响分析结果。非饱和损失(NS)在两种数据集上的表现都很稳定的。梯度惩罚(GP)和光谱正则化(SN)方法能够进一步提高了模型质量。但从计算成本的角度而言,光谱正则化和梯度惩罚的表现优于基准模型,但前者的效率更高。
▌归一化和正则化的影响
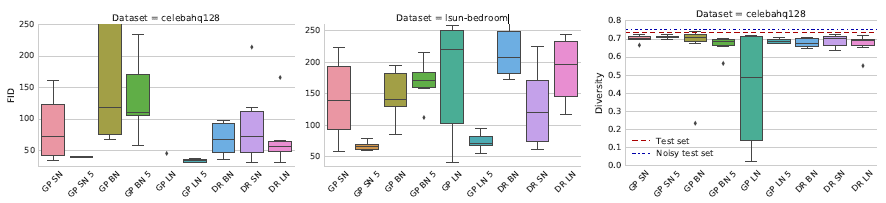
我们实验分析了各种正则化与归一化方法的表现,并展示了批归一化(BN)、层归一化(LN)、谱归一化(SN)、梯度惩罚(GP)、Dragan 惩罚(DR)或者 L2 正则化的实验结果,如下图。结果表明批归一化(BN)不利于判别器的最终表现;而梯度惩罚正则化方法能够产生更好的模型表现,但不利于训练稳定性。
如下图,梯度惩罚(GP)和光谱正则化(SN)的实验结果。二者都有良好的性能表现,而 SN 的表现更加高效。但是,无论哪一种方法都无法完全地解决训练不稳定问题。

同时使用归一化和正则化方法的实验结果(梯度惩罚 GP + 光谱正则化 SN /层正则化 LN)。从下图中可以看到,二者同时使用能够大大改善基准模型的表现。
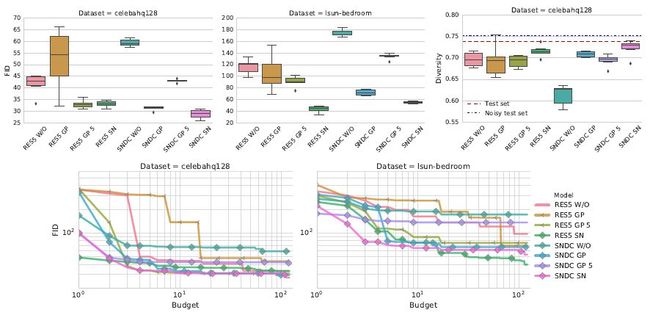
▌生成器和判别器结构的影响
我们采用非饱和 GAN 损失、梯度惩罚(GP)和光谱正则化(SN)方法的实验设置,分析了 DCGAN 结构的影响,结果如下图。
判别器和生成器结构对非饱和 GAN 损失函数的影响。可以看到,光谱正则化(SN)和梯度惩罚(GP)方法都有助于改善非正则化的基线表现。
GANs 中常见的陷阱(pitfalls)
这里我们将重点介绍在 GANs 结果复现过程中遇到的几个常见陷阱,包括评价标准的选择(FID 分数、MS-SSIM 分数等)、神经网络结构的细则、数据以及实现细节等,详情可参见我们的原论文。
结论
在这项工作中,我们分析总结了 GANs 当前的研究现状,包括损失函数,正则化和归一化方法,以及神经网络结构等问题,并采用三个数据集、在不同的评估标准下分别进行实验分析了各种因素组合的影响。总的来说,梯度惩罚(GP)和光谱正则化(SN)方法对于 GANs 的性能表现有很大的提升,特别是 SN。对于模型结构选择而言,DCGAN 是研究中的一种默认选择结构,而 ResNet 风格的模型结构虽然能够取得不错的性能,但其需要高额的计算成本,不利于实践应用。此外,我们还将进一步讨论了 GANs 中一些常见的陷阱,包括评价标准的选择(FID 分数、MS-SSIM 分数等)、神经网络结构的细则、数据以及实现细节等。我们希望这项研究工作、开源项目及预训练模型能够为未来 GANs 的研究奠定一个基线。
原文链接:
https://arxiv.org/abs/1807.04720
colab 地址:
https://colab.research.google.com/github/google/compare_gan/blob/master/compare_gan/src/tfhub_models.ipynb
GitHub 地址:
http://www.github.com/google/compare_gan.
TensorFlow 链接:
http://www.tensorflow.org/hub.
*本文由人工智能头条整理编译,转载请联系编辑(微信1092722531)
在线公开课NLP专场
◆
精彩继续
◆
时间:7月26日 20:00-21:00
扫描海报二维码,免费报名
添加微信csdnai,备注:公开课,加入课程交流群

点击| 阅读原文 |免费报名