一文读懂命名实体识别

本文对自然语言基础技术之命名实体识别进行了相对全面的介绍,包括定义、发展历史、常见方法、以及相关数据集,最后推荐一大波 Python 实战利器,并且包括工具的用法。
01
定义
先来看看维基百科上的定义:Named-entity recognition (NER) (also known as entity identification, entity chunking and entity extraction) is a subtask of information extraction that seeks to locate and classify named entity mentions in unstructured text into pre-defined categories such as the person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。简单的讲,就是识别自然文本中的实体指称的边界和类别。
02
发展历史
命名实体识别这个术语首次出现在 MUC-6(Message Understanding Conferences),这个会议关注的主要问题是信息抽取(Information Extraction),第六届 MUC 除了信息抽取评测任务还开设了新评测任务即命名实体识别任务。
除此之外,其他相关的评测会议包括CoNLL(Conference on Computational Natural Language Learning)、ACE(Automatic Content Extraction)和IEER(Information Extraction-Entity Recognition Evaluation)等。
在MUC-6之前,大家主要是关注人名、地名和组织机构名这三类专业名词的识别。自MUC-6起,后面有很多研究对类别进行了更细致的划分,比如地名被进一步细化为城市、州和国家,也有人将人名进一步细分为政治家、艺人等小类。
此外,一些评测还扩大了专业名词的范围,比如CoNLL某年组织的评测中包含了产品名的识别。一些研究也涉及电影名、书名、项目名、研究领域名称、电子邮件地址、电话号码以及生物信息学领域的专有名词(如蛋白质、DNA、RNA等)。甚至有一些工作不限定“实体”的类型,而是将其当做开放域的命名实体识别和分类。
03
常见方法
早期的命名实体识别方法基本都是基于规则的。之后由于基于大规模的语料库的统计方法在自然语言处理各个方面取得不错的效果之后,一大批机器学习的方法也出现在命名实体类识别任务。宗成庆老师在统计自然语言处理一书粗略的将这些基于机器学习的命名实体识别方法划分为以下几类:
有监督的学习方法:这一类方法需要利用大规模的已标注语料对模型进行参数训练。目前常用的模型或方法包括隐马尔可夫模型、语言模型、最大熵模型、支持向量机、决策树和条件随机场等。值得一提的是,基于条件随机场的方法是命名实体识别中最成功的方法。
半监督的学习方法:这一类方法利用标注的小数据集(种子数据)自举学习。
无监督的学习方法:这一类方法利用词汇资源(如 WordNet)等进行上下文聚类。
混合方法:几种模型相结合或利用统计方法和人工总结的知识库。
值得一提的是,由于深度学习在自然语言的广泛应用,基于深度学习的命名实体识别方法也展现出不错的效果,此类方法基本还是把命名实体识别当做序列标注任务来做,比较经典的方法是 LSTM+CRF、BiLSTM+CRF。
04
相关数据集
1. CCKS2017 开放的中文的电子病例测评相关的数据。
评测任务一:
https://biendata.com/competition/CCKS2017_1/
评测任务二:
https://biendata.com/competition/CCKS2017_2/
2. CCKS2018 开放的音乐领域的实体识别任务。
评测任务:
https://biendata.com/competition/CCKS2018_2/
3. (CoNLL 2002)Annotated Corpus for Named Entity Recognition。
地址:
https://www.kaggle.com/abhinavwalia95/entity-annotated-corpus
4. NLPCC2018 开放的任务型对话系统中的口语理解评测。
地址:
http://tcci.ccf.org.cn/conference/2018/taskdata.php
5. 一家公司提供的数据集,包含人名、地名、机构名、专有名词。
下载地址:
https://bosonnlp.com/dev/resource
05
工具推荐
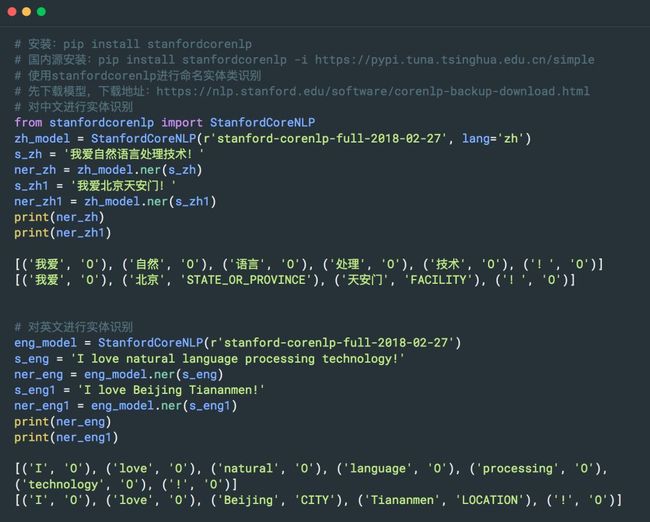
1. Stanford NER
斯坦福大学开发的基于条件随机场的命名实体识别系统,该系统参数是基于 CoNLL、MUC-6、MUC-7 和 ACE 命名实体语料训练出来的。
地址:
https://nlp.stanford.edu/software/CRF-NER.shtml
Python 实现的 Github 地址:
https://github.com/Lynten/stanford-corenlp
2 .MALLET
麻省大学开发的一个统计自然语言处理的开源包,其序列标注工具的应用中能够实现命名实体识别。
官方地址:
http://mallet.cs.umass.edu/
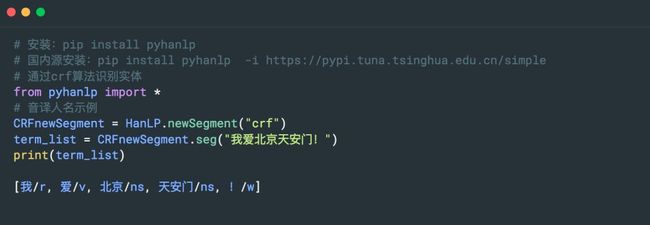
3. Hanlp
HanLP 是一系列模型与算法组成的 NLP 工具包,由大快搜索主导并完全开源,目标是普及自然语言处理在生产环境中的应用。支持命名实体识别。
Github 地址:
https://github.com/hankcs/pyhanlp
官网:
http://hanlp.linrunsoft.com/
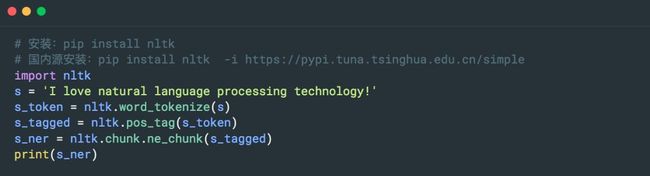
4. NLTK
NLTK 是一个高效的 Python 构建的平台,用来处理人类自然语言数据。
Github 地址:
https://github.com/nltk/nltk
官网:
http://www.nltk.org/
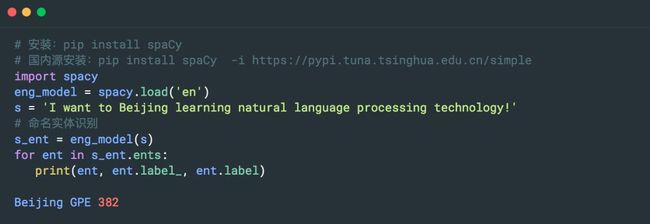
5. SpaCy
工业级的自然语言处理工具,遗憾的是不支持中文。
Gihub 地址:
https://github.com/explosion/spaCy
官网:https://spacy.io/
6. Crfsuite
可以载入自己的数据集去训练 CRF 实体识别模型。
文档地址:
https://sklearn-crfsuite.readthedocs.io/en/latest/?badge=latest
代码已上传:
https://github.com/yuquanle/StudyForNLP/blob/master/NLPbasic/NER.ipynb
参考:
1. 统计自然语言处理
2. 中文信息处理报告-2016
相关阅读:
NLP 入门 (1)| 一篇小文入门 Python
NLP 入门 (2)| 快速入门 Numpy
NLP 入门 (3)| NLP 分词的那些事儿
NLP 入门 (4)| 一起来看看词性标注

作者简介
乐雨泉 (yuquanle),湖南大学在读硕士,研究方向机器学习与自然语言处理。曾在IJCAI、TASLP等会议/期刊发表文章多篇。欢迎志同道合的朋友和我在公众号"AI小白入门"一起交流学习,探讨成长。
