第三章:优化神经网络的学习 tensorflow
http://www.tensorfly.cn/home/?p=90原文地址
《神经网络和深度学习》第三章:优化神经网络的学习
当一个高尔夫选手第一次学习怎么玩高尔夫,他们通常把大量时间花在基本的挥杆。只有逐步的学习他们才能在射击,learning to chip, draw and fade the ball上取得进步,并改善挥杆。同样的,我们目前为止把注意力放在理解后向传播算法。这是我们的“基本的挥杆”。学习的框架主要在神经网络。这章里我会解释一些技巧,帮助我们改善后向传播,同时改善网络学习的方法。
我们这章涉及的技术包括:损失函数更好的选择,known as the cross-entropy cost function;四个被称为“正则”方法,(L1 and L2 regularization, dropout, and artificial expansion of the training data),使我们的网络在训练数据基础上表现的更好;和一些列启发给网络选择更好的预置参数。同时也会概述一些浅显的其他技术。这些讨论大部分相互独立,所以你可以跳过一些。我们同时会用代码实现一些技术,帮助去改善第一章讲的手写分类问题。
当然,我们只涉及到许多知识的运用到神经网络的那一部分。讨论这些东西不仅可以帮助你掌握新知识,还可以帮助你理解你在使用神经网络时可能遇到的问题。可以帮助你需要学习其他知识做好准备。
The cross-entropy cost function交叉熵代价函数
我们大部分人在发现错误时是不高兴的。当开始学习钢琴时我给一位观众做了表演。我很紧张,把一个八度音弹的太低了。我很困惑不能继续下去了,直到有人指出了我的错误。我很尴尬。同时非常不高兴,但也非常快速的进步了。你可以想象我下次表演时,肯定不会把八度音弹错了。相反的,我们错误越来越少时,进步会越来越慢。
理想地说,我们希望神经网络能够快速地从错误中学习。实际上发生了什么?为了回答这个问题,我们看一个例子。这个例子包括只有一个输入的神经:

我们会训练这个神经做一个非常简单的事情:把输入1转换成输出0。当然,这是一个非常简单的问题我们可以自己手动找到适合的权重而不借助学习算法。但我们使用梯度下降学习发现这个合适的权重,这是一个启发性的发现。我们看下这个神经如何学习。
初始化时我设置权重0.6以及偏正0.9。 这是初始化的通常使用的数据,我没有有意的挑选它们。第一次的输出是0.82,在输出接近0之前,它需要一些学习。点击“Run”来看效果,这个动画效果不是预置的,是你的浏览器实际计算的。学习速率是0.15,这样就足够慢帮助我们学习。

你可以看到,这个神经元逐渐学习了使权重和偏正趋向输出等于0.09. 这不是非常理想但足够好了。假设我们设置初始权重和偏正为2.0。在这个例子初始输出为0.98,这是非常错误的。我们看下神经元如何学习使输出为0,点击“Run”

尽管这个例子使用相同的学习速率0.15,我们能够看到学习开始很慢。实际上,在前150次学习中,权重和偏正变化的非常少。然后突然加快到,接近我们第一个例子的结果那样,输出接近0
这个行为很奇怪和人类的学习差别很大。像我说的在学习的开始,我们通常会从错误中学习的非常快。但我们的人工智能神经貌似在有很大错误时学习的非常困难,相比很小的错误来讲。更多是这个行为不仅表现在我们的模型,也在其他通用模型中发现。为什么一开始很慢?我们是否可以找到一个方法避免?
为了理解问题的起源,假设我们的神经元通过损失函数,∂C/∂w and ∂C/∂b来表示对权重和偏正的修改。那么“学习很慢”也意味着这个值很小。挑战是理解为什么他们很小。为了理解,我们计算部分偏正。想起我们使用的二次损失函数,
这里a是神经元的输出,当输入x=1时,y=0是希望的输出。recall that a=σ(z),where z=wx+b.
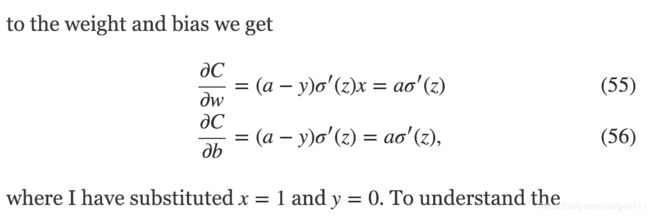
我们看一下σ function

我们可以看到神经输出约接近1,曲线越平坦,所以σ′(z)变得非常小。Equations (55) and (56) then tell us that ∂C/∂w and ∂C/∂b get very small。这就是开始学习非常慢的原因。这也是其他通用网络也有的现象。
Introducing the cross-entropy cost function
我们如何解决学习速率的下降?似乎我们换一个二次损失函数,比如缓存cost function交叉熵代价函数。为了理解cross-entropy cost function,我们先不考虑之前的联系模型。我们假设正在训练一个有多个输入变量的神经元,x1,x2…w1,w2…和一个偏正b:
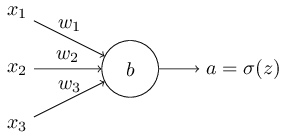
我们定义cross-entropy cost function如下:

这里n是训练数据的总数,加和是所有训练数据的输入,y是希望的输出。
表达式57并没有明显的解释学习速率下降的问题。坦白的说,它都没有理由被称为损失函数!我们先来看看为什么cross-entropy是损失函数。
两个特征来解释:1,它是非负的,就是说C>0。注意到:a,所有的个体单元在57中是负的,因为所有数字的对数范围在0-1,b,前面有一个负号。
2,如果神经元的输出非常接近理想输出时,cross-entropy会接近0. 为了证明这点,我们假设y=0和a约等于0. 这是一个特例,假设神经元对输入处理的非常理想。since y=0, while the second term is just −ln(1−a)≈0. 同样的在y=1和a约等于1时也是这个结果。在输出结果很接近理想结果时损失会很小。
总结来说,cross-entropy的值是正数,并且会在结果越来越好时趋向于0,这是我们要的损失函数所具备的条件。这两个条件实际上在二次损失函数quadratic cost中也符合。但是cross-entropy的优点是,不像quadratic cost,它解决了学习速率低的问题。为了证明这点,我们计算cross-entropy的偏正对应它的权重。我们在(57)中替代a=σ(z) ,求个导。

提取一个相同的分母我们得到:

使用sigmoid函数,σ(z)=1/(1+e−z) , and a little algebra we can show that σ′(z)=σ(z)(1−σ(z)). 我会让你验证这个在下面的一个练习中。现在我们先这样用。我们发现 σ′(z) and σ(z)(1−σ(z))消除了分母。式子就变成了:

这是一个优美的表达式。它告诉我们权重改变的速率是由σ(z)−y 控制的,被输出的错误影响。错误越大,神经元学习越快。这是我们期望的。特别的,它消除了二次损失函数式子(55)由于 σ′(z) 影响的学习速率低的问题。我们使用cross-entropy, σ′(z)被约掉了,所以不必担心它变小的问题了。这很神奇。当然这也不是巧合,我们后面会讲到cross-entropy是如何抵消的。
相同的,我们对b求导,我们不再详细讲述,但你可以验证

同样的,他消除了σ′(z) 在式子(56)带来的问题。
Exercise
验证σ′(z)=σ(z)(1−σ(z)).
我们用cross-entropy替换之前的二次损失函数,设置权重0.6偏正0.9,点击“Run”看一下效果

和想的意义,神经元学习的很好,我们设置权重和偏正都是2.0:
很棒。这次学习的很快,和我们期望的一样。你可以看到斜坡更陡了。cross-entropy帮助我们减少错误很大时快速学习的障碍。
开始的二次损失函数,我们使用学习速率η=0.15. 在新的例子中,我们是否应该用相同的学习速率?实际上,因为损失函数换了,很难确定一个“相同”的学习速率;就像把苹果和橘子对比一样。在使用两个损失函数时,我只是用了一个可以看到现象的学习速率。如果你非要问,我这个例子使用了 η=0.005
你可能认为学习速率在上面的图表中没有什么意义。没有人关心神经元学习的有多快,实际上这个图表不关注学习有多快,而是学习速率变化了。使用cross-entropy时即使神经元错误很大时依旧学习很快。这和设置学习率没有关系。
我们已经学习了cross-entropy在单个神经元。然而,这和容易通过多个神经元生成网络。通过y=y1,y2…是希望的输出值,a1L,a2L…是实际的输出值。我们定义cross-entropy为:

这和我们之前的表达式(57)一样,假设我们把所有神经元输出叠加了。式子(63)在大多数神经网络中避免了学习速率下降的问题。如果你有兴趣,可以通过下面问题的偏导证明。
什么时候我们需要使用cross-entropy代替quadratic cost二次损失函数?实际上,大多数情况cross-entropy是更好的选择,在输出神经元是sigmoid时。看下为什么是这样,考虑到我们初始的权重和偏正都是随机的,开始设置正好是理想输出相反的情况,就如希望输出是0,而第一次输出是1的情况,二次损失函数会学习的非常慢。
Exercises
有个问题是我们很难记住这个式子,很容易搞混到底是−[ylna+(1−y)ln(1−a)] or −[alny+(1−a)ln(1−y)]. 当第二个式子里y=0或者1时是怎样的?这个对第一印象有没有用?为什么?
前面我说cross-entropy很小如果σ(z)≈y,在y等于0或者1时。只有在在分类问题时这是正确的。在其他问题比如回归问题时y可以0-1之间的任何值。
Problems问题
多层多元神经网络在上章提到了,二次损失函数对权重的偏导是

式子σ′(zLj) 会导致学习速率下降无论何时只有有一个输出神经元误差很大的情况。假设输出误差δL在一个单一训练例子中

用这个式子表示权重的偏导为:
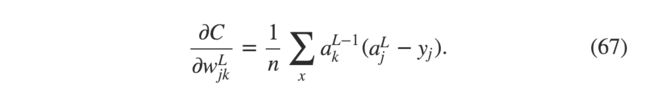
σ′(zLj) 这个式子消失了,所以cross-entropy 避免了学习速率下降,不仅仅对一个神经元来说,对整个多层多元网络也是这样。
使用二次损失函数在一个线性神经输出层:假设最后一层所有神经元的输出都是线性的,意味着sigmoid函数没有运作,输出都是 aLj=zLj.

和前面的问题很像,偏导为:

表示如果所有输出神经元都是线性的那么二次损失函数不会有学习速率下降的问题。这个就是正确使用quadratic cost的例子。
使用cross-entropy分类MNIST数据
cross-entropy很容易在学习使用梯度下降和后向传播问题中运用。我们会在后面介绍,开发一个之前程序的改进版本,分类MNIST手写数据,network.py. 新的程序是network2.py,不仅加入了cross-entropy,还有一些其他技术。我们看下新程序如何分类MNIST数据。和第一章的例子一样,我们用30层隐藏神经元,最小mini-batch size of 10,设置学习率 η=0.5* 然后训练30个周期。network2.py的接口和network.py有些不同,但是足够了解如何工作的。你可以使用documentation about network2.py's interface by using commands such as help(network2.Network.SGD) in a Python shell.
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()
>>> import network2
>>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost)
>>> net.large_weight_initializer()
>>> net.SGD(training_data, 30, 10, 0.5, evaluation_data=test_data,
... monitor_evaluation_accuracy=True)
注意,net.large_weight_initializer()是初始化权重和偏正用的。之后我们会替换这个方法。上面实验的结果是95.49正确率。和第一章使用quadratic cost的95.42正确率相似。
我们再看一下使用100个隐藏神经元,使用cross-entropy,其他参数一样的情况。这次我们得到96.82正确率。和第一章这种情况的96.59正确率相比提高了。错误率从3.41下降到了3.18,我们认为是很好的进步。
cross-entropy表现比quadratic cost表现好我们很兴奋。但这不能结论性的证明cross-entropy更好。因为我们只用了特定的学习率,mini-batch size。我会应该优化这些假设的参数去确认。结论是cross-entropy确实更好。
到这里我们实现了发现问题,研究新技术优化结果的一个过程。这非常好,但往往这个过程很困难。如果我们对所有参数都做一个证明过程会更具说服力。但这是一个耗时的过程,我们不会做如此耗时的投入。你只需记得这些测试使争论的声音变小了。
为什么如此费力只为了使MNIST结果好了一点点?之后我们会讨论regularization正则化,会使它有大大的改善。那么为什么如此关注cross-entropy?部分原因是它在损失函数中被广泛使用,所以我们要好好学习它。更重要的原因是神经元饱和在神经网络中是一个大问题。所以我借助cross-entropy帮助更好的理解神经元饱和问题。
cross-entropy意味着什么?它来自哪里?
我们对cross-entropy的关注在算法分析和实际应用。它很有用,但也留下了问题比如:cross-entropy到底是什么意思?有什么直观的解释关于cross-entropy?我们对cross-entropy第一印象是什么?
我们从最后一个问题开始:我们对cross-entropy第一印象是什么?假设我们发现了之前说的学习速率下降,并且理解起源是σ′(z)在式子(55)和(56)中。我们会想是否有一个损失函数使得 σ′(z)消失?这样可以获得:

如果我们能够选择一个损失函数cost function使得这个等式成立,我们就可以直观的看到初始错误越大,神经元的学习速率越快。同样消除了学习速率下降的问题。从这个等式开始我们能够获得cross-entropy的图表,通过我们的数学式。

这是一个神经元的例子,对于整个损失函数我们取平均:

这里的常数是每个训练例子中常数的平均。我们看到式子(71)和(72)决定了cross-entropy的值,以一个常数的形式。cross-entropy不是凭空产生的。是我们能够用一种简单方式发现的。
我们对cross-entropy第一印象是什么?我们如何看它?为了解释这个会走的很远,但是值得一提的是通过信息理论可以用一种标准的方式解释。粗鲁地说,cross-entropy令人惊讶。我们神经元尝试去计算x→y=y(x),但是实际上在计算x→a=a(x). 后面说cross-entropy是测量我们的“惊讶”程度的,如果结果是我们期望的,我们获得小惊讶,和我们期望的不一样,就是大惊讶。就是信息可以猜测到的概率。如果要深入理解,看information theory by Cover and Thomas.
Problem
我们已经讨论过了,用二次损失函数去训练,当神经元输出饱和就会有学习速率下降。另一个原因是在式子(61)中的xj。因为这个变量,当输入接近0,权重会学习的非常慢。解释一下为什么不能用一个更好的损失函数消除xj带来的影响。
Softmax
在这章,我们主要使用cross-entropy cost去解决学习速率下降的问题。然而,我想简单介绍另一种方法解决这个问题,被称为神经元层中的softmax。我们实际上不使用softmax在这章中,如果你很急着了解,可以跳过到下一部分。然而,softmax仍然值得去学习,不仅因为很有趣,并且我们会在第6章中使用到,之后的深层神经网络。
softmax的思想是为我们的神经网络定义一个新的输出层。就像使用sigmoid层一样,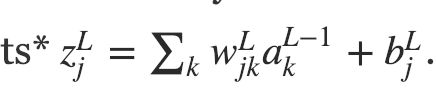
但是我们不用sigmoid函数去得到输出。
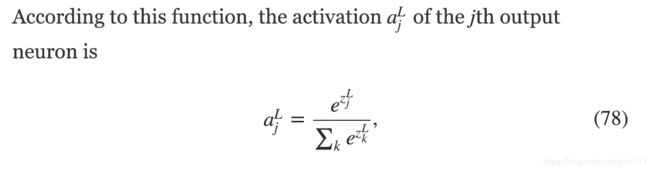
这里分母中我们把所有的输出神经元叠加了。
如果你对softmax函数不熟,等式(78)可能很难理解。这可能不明显为什么我们使用这个函数。而且不明显它可以帮助我们定位学习速率下降的问题。为了更好的理解(78),假设我们有一个4个输出神经元的网络,和4个相应权重的输入,zL1,zL2,zL3, and zL4.下面是四个值的滑动条,和一个相应输出的图表。
当你增加zL4时,你可以看到相应输出激活aL4也增加了。相应的,降低中zL4会减少aL4,并且其他所有输出会增加。你自己看会发现其他激活正好补偿了aL4的变化。因为输出激活要保证加和为1,我们可以用式子(78)和代数证明:

如果aL4增加了,其他输出激活必须下降相应数量,保证加和保持1。其他激活也一样如此。
式子(78)同样暗示输出激活都为正数,因为指数函数是正数。我们发现softmax的输出层是很多相加为1的正数。换句话说,softmax层的输出可以看成概率的分布。
softmax输出一个概率分布是令人愉悦的。在很多问题中把aLj理解成预计的正确的可能性,j是正确输出。所以在MNIST分类问题中,我们可以理解成aLj是网络预计正确的可能性,正确的值是j。
相反的,如果输出是sigmoid层,就不能看成是概率分布。我不会详细的证明这个了,但是sigmoid层不能形成概率分布是合理的。同时如果使用sigmoid就没有那么简单了。
Exercise
构造一个例子,在一个sigmoid输出层的网络中,输出激活aLj不会永远加起来是1.
我们开始建立一些softmax的印象和表现。回顾一下我们讲到哪里了:在(78)式子中的指数保证了所有输出激活是正数。然后分母的加和在式子(78)保证softmax输出加和是1. 这样就不那么神秘了:这是一个很自然的方式保证了输出是一个概率分布。你可以认为softmax是zLj的转换,然后把它们压缩成概率分布。
Exercise
Monotonicity of softmax 表明 ∂aLj/∂zLk是正数在j=k的时候,如果 j≠k则是负数。因此,增加zLj会使输出增加aLj,时其他输出激活减少。我们从滑动条上可以看出来,但这是一个严格的证明。
Non-locality of softmax 一个关于sigmoid层,aLj是关于权重输入的函数,aLj=σ(zLj) 。解释为什么这不是softmax层的例子:任何输出激活aLj依赖所有权重输入。
Problem
Inverting the softmax layer 倒置softmax层。假设我们有一个神经网络有softmax输出层,激活aLj是知道的,证明输入权重zLj=lnaLj+C,常数C和j不相干。
学习速率下降问题:我们已经对softmax足够熟悉了。但是我们还没有看到softmax如何解决学习速率下降问题。为了理解这个,我们定义对数似然损失函数。我们会使用x代表网络的输入,y代表理想的输出。所以函数为:
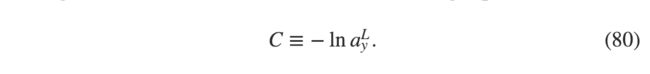
那么,举个例子,如果我们训练MNIST图像,放入一个图像7,那么对数似然损失函数是−lnaL7 .可以直观的发现,如果网络工作的好,输入肯定是7. 所以输出aL7会接近1,那么 −lnaL7会很小。相反的,网络工作的不那么好,aL7会很小,损失函数 −lnaL7会很大。所以对数似然损失函数符合我们需要的损失函数的特征。
那么怎么看学习速率下降问题?为了分析这个,记得学习速率是由∂C/∂wLjk and ∂C/∂bLj 影响的。

这个式子和之前 cross-entropy中获得的表达式一样。式子(82)和式子(67)。是同一个等式。实际上这很有用,把softmax输出层的对数似然损失函数log-likelihood cost和sigmoid的输出cross-entropy损失函数对比。
那么你知道该用sigmoid输出层的cross-entropy还是softmax输出层的对数似然损失函数?实际上,大部分情况这两者都能用。这章我们使用第一种,第6章使用第二种。这样是为了使我们之后的网络和一些学术论文中提到的更接近。更重要的原则是,softmax plus log-likelihood在任何理解输出激活的问题中都值得研究。
Problems
获得式子(81)和(82)
softmax这个名字来自哪里?如果我们对softmax做一些转变:

C是一个正的常数。注意c=1时是标准的softmax函数。但是如果我们对c使用别的值,也是和softmax相似的函数。假设我们使c变得很大,c趋向无穷大。aLj的极限是什么?理解了这个你就可以理解为什么c=1时是“softened”版本,这是softmax的初始版本。
Backpropagation with softmax and the log-likelihood cost 在上一章我们获得后向传播网络,包含sigmoid层。我们需要一个式子表示δLj≡∂C/∂zLj 在网络的最后一层。
这个表达式可以运用到网络的后向传播算法,在使用softmax output layer and the log-likelihood cost.时候
Overfitting and regularization过度拟合和归一化
诺贝尔物理学家获得者Enrico Fermi被问过一个问题,他怎么看一些大学提出的,用数学模型解决重要的物理问题。这个模型在实验中很好的表现,但是Enrico Fermi表示怀疑。他问在这个模型有多少参数可以设置。“4”个。Enrico Fermi说,我记得我的朋友Johnny von Neumann说过,4个参数我可以定义一个大象,5个参数我可以让他的腿抬起来。
这表示一个模型如果有足够多的自由参数可以设置,那么它可以表现出惊人的现象。即时可以处理那么多数据的模型也不一定是足够好的模型。因为对新情况它可能表现没那么好。主要还看模型能否对没有遇到过的新情况做出好的相应。
Fermi and von Neumann都对4个参数的模型表示怀疑。我们分类MNIST数据的网络有30个隐层,接近24000个参数!那是相当多的数量,100个隐层就有80000个参数。有些深度网络有百万甚至亿万级参数。我们可以相信这些结果吗?
我们把这个问题缩减到:我们的网络对新的环境响应如何?我们会使用30个隐层的网络,23860个参数。但是我们不会用所有的50000个MNIST图像去训练。我们只使用前1000个训练图像。用那么严格的设置可以使问题更明显。和之前类似一样训练,使用学习速率0.5,最小batch size 10. 我们会训练400个周期,比之前稍微多些,因为我们训练数据少了很多。我们用network2看输出损失函数的变化:
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()
>>> import network2
>>> net = network2.Network([784, 30, 10], cost=network2.CrossEntropyCost)
>>> net.large_weight_initializer()
>>> net.SGD(training_data[:1000], 400, 10, 0.5, evaluation_data=test_data,
... monitor_evaluation_accuracy=True, monitor_training_cost=True)

我们看到损失下降很平滑,和我们期望的一样。注意图表只是200个周期,一共是399个。我故意这么做为了后面的分析更直观。
我们再看下分类的精确度随时间的变化:

再一次,我稍微放大了一下。前200个周期(图上没有画)精确度在82%以下。学习速率逐渐下降了。最后,在大约280个周期开始时,几乎停止进步了。精确度在280个周期的值上下随机波动。和前一个表不同的是,前一个表的损失还在持续下降。如果我们只看cost,似乎模型还在持续变好。但是准确率结果表明这个改善是假的。就像Fermi否认这个模型一样,280个周期后,我们的网络不再学习。后面的学习是没有用的。我们说网络已经过度拟合了overfitting或它在280个周期后过度拟合。
你可能好奇如果我们可以看下损失函数关羽分类精确度的函数图表。换句话说,可能我们在把苹果和橘子做对比了。我们这个对比是否在相同计量标准下进行的?或者我们需要把分类精确度和训练数据以及测试数据同时对比?实际上无论是哪种结果都一样。只有小细节有所改变。我们看下测试数据的图表:

我们看到测试数据的损失在15个周期后才有所改善,但是后面却变得更差了,尽管训练数据持续编号。这是我们模型过度拟合的另一种表现。我们很疑惑应该用第15个周期还是280个周期作为过度拟合的点?我们真正关心的是提高测试数据的准确度,然而损失函数只是一部分。所以我们用第280个epoch作为过度拟合点。
另一种过度拟合表现在训练数据中如下:

准确度提升到百分之100。那表明我们网络正确分类了所有1000张图片!同时,我们测试数据准确度在82.27%。那么我们的网络只是学到了训练数据的特例,并不是真的认识数字。或者说没有足够好的理解数字。
过度拟合在神经网络中是一个大问题。在当今有大量权重和偏正的网络中很普遍。为了有效地训练,我们需要一种方式检测过度拟合从哪里开始,后面就不用计算了。并且我们希望有一个技术去减少过度拟合的影响。
最明显的检测过度拟合的方式是用上面的方法,持续监控测试数据的准确度。如果我们看到准确率不再提高,name我们停止。当然,严格地说,这不是一个严格地特征。准确率在测试数据和训练数据可能同时停止改善。
实际上,我们使用一个变量。记得我们载入MNIST数据时载入了三个设置:
>>> import mnist_loader
>>> training_data, validation_data, test_data = \
... mnist_loader.load_data_wrapper()
目前为止我们使用了training_data and test_data,没有使用validation_data。 validation_data包含了10000张数字图像,和50000张训练图像以及10000张测试图像不同。替代使用test_data去组织过度拟合,我们使用validation_data。我们使用之前相似的策略。具体地说,我们会计算validation_data在每个周期的准确度。一旦分类准确度饱和了,我们停止训练。这个策略叫early stopping. 当然,实际上我们不会马上知道饱和了。我们会多运行一会确保我们找到饱和点了。
为什么去使用validation_data组织过度拟合呢,而不是test_data?实际上,这是一个很通用的策略,我们使用这个评估去找到好的参数值。
当然,这还没有回答为什么使用validation_data组织过度拟合的问题。就是说我们希望我们之后用测试数据测试时能体现我们确实找到了一个饱和点,而不是用测试数据去找到饱和点再用测试数据去验证,这样就没有说服力了。这个方法称为hold out method。因为validation_data从training_data "held out"或分离了。
现在我们尝试用另一种方法-可能是不同的网络结构-去找到新的参数。我们会使用training_data, validation_data, and test_data, as described above.
我们只使用了1000个训练图像。如果我们使用50000个图像会怎样?我们保持其他参数一样(30个隐层,学习速率0.5,mini-batch size of 10)训练所有50000个图像用30个周期。下面图表是一个test数据和训练数据对比:

可以看到,准确率在测试和训练数据更加接近,和之前使用1000个训练数据时对比。训练数据97.86的准确率和测试数据95.33准确率相比,只剩1.53的差距了。我们之前是17.73. 过度拟合还是有,但是大大减少了。我们的网络比之前的更好了。通常情况下,增加训练数据是减少过度拟合很好的方法。有足够多的训练数据过度拟合就很小了。但是坏消息是,训练数据的收集很花成本,这个方法就不是很实际。