生成对抗网络(九)----------ACGAN
一、ACGAN的介绍
使用有标签的数据集应用在生成对抗网络可以有效的增强现有的生成模型。形成了两种优化的思路。
第一种是cGAN中使用了辅助的标签信息来增强原始GAN,对生成器和判别器均使用标签数据来训练。实现了生成模型具备特定条件数据的能力。同时也有研究表明,cGAN的生成图像质量比传统的方式更优,当标签信息更丰富的时候。效果也随之升高。
第二种是SGAN从另一个方向利用辅助标签信息。利用判别器或分类器一端来重建标签信息,从而提升GAN的生成效果。研究发现,当让模型处理额外信息时,反而会让模型本来的生成任务完成的更好。优化后的分类器可以有效提升图像的综合质量。
上面是从两个角度思考标签数据对于GAN的优化,将这两种思想结合就可以建立辅助分类GAN。我们称之为ACGAN。通过对结构的改造将上面的两个优势结合在一起,利用辅助标签信息产生更高质量的生成样本。
ACGAN的结构如如下:
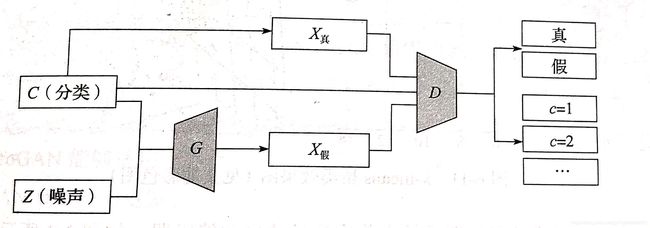
对于生成器有两个输入,一个是标签分类C,另一个是随机数据z,得到生成数据![]() ,对于判别器分别要判断数据源是否为真实数据的概率分布P(S|X)以及数据源对于分裂标签的概率分布P(C|X)。ACGAN的目标函数包含两部分,第一部分面向数据真实与否的代价函数,第二部分面向数据分类准确性的代价函数。公式如下:
,对于判别器分别要判断数据源是否为真实数据的概率分布P(S|X)以及数据源对于分裂标签的概率分布P(C|X)。ACGAN的目标函数包含两部分,第一部分面向数据真实与否的代价函数,第二部分面向数据分类准确性的代价函数。公式如下:
![]()
![]()
训练过程中,优化的方向是希望训练判别器D能够使得![]() 最大,生成G使得
最大,生成G使得![]() 最小。物理意义为判别器能够尽可能地区分真实数据和生成数据并且能够有效地进行分类。对于判别器能够生成数据被尽可能地认为是真实数据且数据都能够被有效分类。
最小。物理意义为判别器能够尽可能地区分真实数据和生成数据并且能够有效地进行分类。对于判别器能够生成数据被尽可能地认为是真实数据且数据都能够被有效分类。
二、ACGAN的代码实现
1. 导包
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout, multiply
from keras.layers import BatchNormalization, Activation, Embedding, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
# 动态申请显卡内存
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config)2. 初始化
class ACGAN():
def __init__(self):
# 图像形状参数
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.num_classes = 10
self.latent_dim = 100
# 优化方法
optimizer = Adam(0.0002, 0.5)
losses = ['binary_crossentropy', 'sparse_categorical_crossentropy']
# 建造编译判别器
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss=losses,
optimizer=optimizer,
metrics=['accuracy'])
# 建造生成器
self.generator = self.build_generator()
# 噪声和目标标签作为输入,生成对应标签的数字
noise = Input(shape=(self.latent_dim,))
label = Input(shape=(1,))
img = self.generator([noise, label])
# 固定判别器
self.discriminator.trainable = False
# 生成图像作为判别器输入,得到标签和验证
valid, target_label = self.discriminator(img)
# 组合模型,生成器和判别器的堆叠,训练生成器去愚弄判别器
self.combined = Model([noise, label], [valid, target_label])
self.combined.compile(loss=losses,
optimizer=optimizer)
3. 构建生成器
def build_generator(self):
model = Sequential()
model.add(Dense(128 * 7 * 7, activation='relu', input_dim=self.latent_dim))
model.add(Reshape((7, 7, 128)))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding='same'))
model.add(Activation('relu'))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=3, padding='same'))
model.add(Activation('relu'))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(self.channels, kernel_size=3, padding='same'))
model.add(Activation('tanh'))
model.summary()
noise = Input(shape=(self.latent_dim,))
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(self.num_classes, 100)(label))
model_input = multiply([noise, label_embedding])
img = model(model_input)
return Model([noise, label], img)4. 构建判别器
def build_discriminator(self):
model = Sequential()
model.add(Conv2D(16, kernel_size=3, strides=2, input_shape=self.img_shape, padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(32, kernel_size=3, strides=2, padding='same'))
model.add(ZeroPadding2D(padding=((0, 1), (0, 1))))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(64, kernel_size=3, strides=2, padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(128, kernel_size=3, strides=1, padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Flatten())
model.summary()
img = Input(shape=self.img_shape)
features = model(img)
validity = Dense(1, activation='sigmoid')(features)
label = Dense(self.num_classes + 1, activation='softmax')(features)
return Model(img, [validity, label])
5. 训练模型
def train(self, epochs, batch_size=128, sample_interval=50):
# 加载数据
(X_train, y_train), (_, _) = mnist.load_data()
# 配置输入
X_train = (X_train.astype(np.float32) / 127.5) / 127.5
X_train = np.expand_dims(X_train, axis=3)
y_train = y_train.reshape(-1, 1)
# 真实值
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
'''训练判别器'''
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
# 噪声样本
noise = np.random.normal(0, 1, (batch_size, 100))
# 数字的标签,生成器尝试创建图像的表示
sampled_labels = np.random.randint(0, 10, (batch_size, 1))
# 生成图像
gen_imgs = self.generator.predict([noise, sampled_labels])
# 图像标签
img_labels = y_train[idx]
fake_labels = 10 * np.ones(img_labels.shape)
# 训练判别器
d_loss_real = self.discriminator.train_on_batch(imgs, [valid, img_labels])
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, [fake, fake_labels])
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
'''训练生成器'''
g_loss = self.combined.train_on_batch([noise, sampled_labels], [valid, sampled_labels])
print("%d [D loss: %f, acc.: %.2f%%, op_acc: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100 * d_loss[3], 100 * d_loss[4], g_loss[0]))
if epoch % sample_interval == 0:
self.save_model()
self.sample_images(epoch)6. 显示数据
def sample_images(self, epoch):
r, c = 10, 10
noise = np.random.normal(0, 1, (r * c, 100))
sampled_labels = np.array([num for _ in range(r) for num in range(c)])
gen_imgs = self.generator.predict([noise, sampled_labels])
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i, j].imshow(gen_imgs[cnt, :, :, 0], cmap='gray')
axs[i, j].axis('off')
cnt += 1
fig.savefig("images/%d.png" % epoch)
plt.close()
7. 保存模型
def save_model(self):
def save(model, model_name):
model_path = "saved_model/%s.json" % model_name
weights_path = "saved_model/%s_weights.hdf5" % model_name
options = {"file_arch": model_path,
"file_weights": weights_path}
json_string = model.to_json()
open(options['file_arch'], 'w').write(json_string)
model.save_weights(options['file_weights'])
save(self.generator, "generator")
save(self.discriminator, 'discriminator')
8. 运行代码
if __name__ == '__main__':
acgan = ACGAN()
acgan.train(epochs=20000, batch_size=128, sample_interval=200)结果:
