深度树学习用于Zero-shot人脸的反欺诈(文末论文)
【导读】今天我们主要讲解零次学习及深度树学习用于人脸发欺诈技术。今天主要会讲解13种欺骗攻击中的ZSFA(Zero-Shot Face Anti-spoofing)问题,包括打印、重放、3D掩码等,利用新的深度树网络(DTN),以无监督的方式将欺骗样本划分为语义子组。当数据样本到达、已知或未知攻击时,DTN将其划分到最相似的欺骗集群,并做出二进制决策。最后实验表明,达到了ZSFA多个测试协议的最新水平。

人脸反欺骗设计是为了防止人脸识别系统将假面孔识别为真正的用户。在发展先进的人脸反欺骗方法的同时,新型的欺骗攻击也在被创造,并成为对所有现有系统的威胁。
为了解决更广泛的ZSFA问题,本次就讲解新的深度树网络(DTN)。假设在不同的欺骗类型之间有相同的特性,并且在每种欺骗类型中都有不同的特征,那么一个类似树的模型非常适合处理这种情况:学习早期树节点中的同构特征,在后面的树节点中学习不同的特征。在没有欺骗类型的任何辅助标签的情况下,DTN学会以一种无监督的方式对数据进行分区。在每个树节点,分区沿着最大数据变化的方向执行。最后,它在叶层将数据聚成几个子组,并学习独立地检测每个子组的欺骗攻击,如下图所示。在测试过程中,一个数据样本被路由到最相似的叶节点,以生成一个live VS spoof的二进制决策。

先前的技术工作
Face Anti-spoofing
基于图像的人脸反欺骗是指人脸防欺诈技术,仅将RGB图像作为输入而不需要诸如深度之类的额外信息。在早期的几年里,研究人员利用了liveness线索,例如眨眼和头部运动,以检测打印攻击。然而,当遇到unknown攻击时,例如具有眼睛部分切割的图片和视频重放,这些方法遭受了所有的失败。
随后,研究移动到更一般的纹理分析,并且解决打印和重放攻击。研究人员主要利用人工制作的特征,例如LBP,HOG,SIFT和SURF与传统分类器,例如,支持向量机(SVM)和线性回归算法(LR),进行二元决策。这些方法对来自同一数据库的测试数据进行良好的测试,然而在改变测试条件的同时,照明和背景,它们通常具有很大的性能下降,这可以看作是一个过拟合的问题。此外,它们还显示处理3D掩模的攻击。
为了克服这一过拟合的问题,研究者们做了各种各样的尝试。Boulkenafet等人提取HSV+YCbCR空间中的欺骗特征(Z. Boulkenafet, J. Komulainen, and A. Hadid. Face antispoofing based on color texture analysis. In ICIP, 2015)。还有些工作研究考虑了时间域的特征。最近的工作通过使用图像补丁来增加数据,并将从补丁到单个决策的分数进行融合。对于3D掩模攻击,估计心率来区分三维掩模和真实人脸。在深度学习的时代,研究人员提出了一些CNN作品,这些作品都优于传统的方法。
Zero-shot learning and unknown spoof attacks
Zero-shot目标识别,或者更广泛地说,是零次学习,目的是识别未知类中的对象,即训练中看不到的对象类。总的思想是通过语义嵌入将已知和未知的类关联起来,其嵌入空间可以是属性、字向量、文本描述和人类凝视。
未知欺骗攻击的零次学习,即ZSFA,是一个相对较新的具有独特性质的课题。首先,与Zero-shot目标识别不同,ZSFA强调欺骗攻击的检测,而不是识别特定的欺骗类型;其次,与具有丰富语义嵌入的对象不同,欺骗模式没有明确定义的语义嵌入。如SEC所述:1)以前的ZSFA工作只通过手工制作的特性和标准的生成模型来模拟活数据,有几个缺点。在最新的工作中,提出了一个深度树网络来不受监督地学习已知欺骗攻击的语义嵌入。数据的划分自然地将某些语义属性与子组相关联。在测试过程中,将未知攻击映射到嵌入中,以寻找最接近的欺骗检测属性。
*接下来我们来详细说说零次学习(Zero-shot)
零次学习
先举一个例子:
假设小明和他爸爸到了动物园,看到了马,然后爸爸告诉他,这就是马;之后,又看到了老虎,告诉他:“看,这种身上有条纹的动物就是老虎。”最后,又带他去看了熊猫,对他说:“你看这熊猫是黑白色的。”然后,爸爸给小明安排了一个任务,让他在动物园里找一种他从没见过的动物,叫斑马,并告诉了小明有关于斑马的信息:“斑马有着马的轮廓,身上有像老虎一样的条纹,而且它像熊猫一样是黑白色的。”最后,小明根据爸爸的提示,在动物园里找到了斑马。
上述例子中包含了一个人类的推理过程,就是利用过去的知识(马,老虎,熊猫和斑马的描述),在脑海中推理出新对象的具体形态,从而能对新对象进行辨认。如下图所示ZSL就是希望能够模仿人类的这个推理过程,使得计算机具有识别新事物的能力。
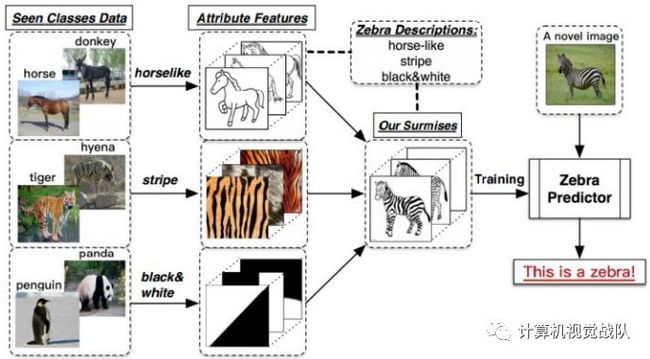
如今深度学习非常火热,使得纯监督学习在很多任务上都达到了让人惊叹的结果,但其限制是:往往需要足够多的样本才能训练出足够好的模型,并且利用猫狗训练出来的分类器,就只能对猫狗进行分类,其他的物种它都无法识别。这样的模型显然并不符合我们对人工智能的终极想象,我们希望机器能够像上文中的小明一样,具有通过推理,识别新类别的能力。
ZSL就是希望我们的模型能够对其从没见过的类别进行分类,让机器具有推理能力,实现真正的智能。其中零次(Zero-shot)是指对于要分类的类别对象,一次也不学习。这样的能力听上去很具有吸引力,那么到底是怎么实现的呢?
假设我们的模型已经能够识别马,老虎和熊猫了,现在需要该模型也识别斑马,那么我们需要像爸爸一样告诉模型,怎样的对象才是斑马,但是并不能直接让模型看见斑马。所以模型需要知道的信息是马的样本、老虎的样本、熊猫的样本和样本的标签,以及关于前三种动物和斑马的描述。
将其转换为常规的机器学习,这里我们只讨论一般的图片分类问题:
(1)训练集数据 及其标签 ,包含了模型需要学习的类别(马、老虎和熊猫),这里和传统的监督学习中的定义一致;
(2)测试集数据 及其标签 ,包含了模型需要辨识的类别(斑马),这里和传统的监督学习中也定义一样;
(3)训练集类别的描述 ,以及测试集类别的描述 ;
我们将每一个类别 ,都表示成一个语义向量 的形式,而这个语义向量的每一个维度都表示一种高级的属性,比如“黑白色”、“有尾巴”、“有羽毛”等,当这个类别包含这种属性时,那在其维度上被设置为非零值。对于一个数据集来说,语义向量的维度是固定的,它包含了能够较充分描述数据集中类别的属性。
在ZSL中,我们希望利用 和 来训练模型,而模型能够具有识别 的能力,因此模型需要知道所有类别的描述 和 。ZSL这样的设置其实就是上文中小明识别斑马的过程中,爸爸为他提供的条件。
目前的研究方式 ,在上文中提到,要实现ZSL功能似乎需要解决两个部分的问题:第一个问题是获取合适的类别描述A;第二个问题是建立一个合适的分类模型。 目前大部分工作都集中在第二个问题上,而第一个问题的研究进展比较缓慢。个人认为的原因是, 目前A的获取主要集中于一些NLP的方法,而且难度较大;而第二个问题能够用的方法较多,比较容易出成果。 因此,接下来的算法部分,也只介绍研究分类模型的方法。
基础算法
在此具体介绍最简单的方法。我们面对的是一个图片分类问题,即对测试集的样本进行分类,而我们分类时需要借助类别的描述 ,由于每一个类别 ,都对应一个语义向量,因此我们现在可以忘掉,直接使用 。我们把(利用深度网络提取的图片特征,比如GoogleNet提取为1024维)称为特征空间,把类别的语义表示称为语义空间。我们要做的其实就是建立特征空间与语义空间之间的映射。
对于分类,我们能想到的最简单的形式就是岭回归(ridge regression),俗称均方误差加范数约束,具体形式为:
其中, 通常为2范数约束,为超参,对求导,并让导为0,即可求出的值。测试时,利用将投影到语义空间中,并在该空间中寻找到离它最近的,则样本的类别为所对应的标签。
感谢大家对“计算机视觉战队”微信公众号的关注与支持,我们后期会持续为大家带来更好的干活及实践应用。
今天我们就先说到这里,下一期我们好好为大家带来“深度树网络”及无监督树学习的方式。
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。
我们开创一段时间的“计算机视觉协会”知识星球,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。

微信学习讨论群也可以加入,我们会第一时间在该些群里预告!
论文链接:http://openaccess.thecvf.com/content_CVPR_2019/papers/Liu_Deep_Tree_Learning_for_Zero-Shot_Face_Anti-Spoofing_CVPR_2019_paper.pdf