基于python的网络爬虫---抓取p站图片
网络爬虫技术在网上非常流行,而使用python来编写网络爬虫程序非常的便利。笔者去年由于个人需要编写了一份用于抓取p站动漫图片的爬虫,如今想以它为实例把网络爬虫的编写方法向大家进行一次介绍。
主要使用的python库为urllib,python版本为3.5.2。另外使用的浏览器是火狐浏览器。
2017.3.22 更新 ----------- 上传了源码到github,有兴趣的可以自行下载。
进入p站首页,我们可以看到下面这样纷繁多姿的图片,可以在p站上在线阅览。有时候我们想把他们从p站上下载下来,等有空闲的时候再去观赏。笔者就有这样的想法,但是一张一张的下载保存实在是太慢了,所以想通过编写程序来实现这样一个过程。
首先,我们明确一下目标。爬取的目标定为出现在p站每天的日排行榜中的图片,因为在排行榜里的图片的质量一般较高。
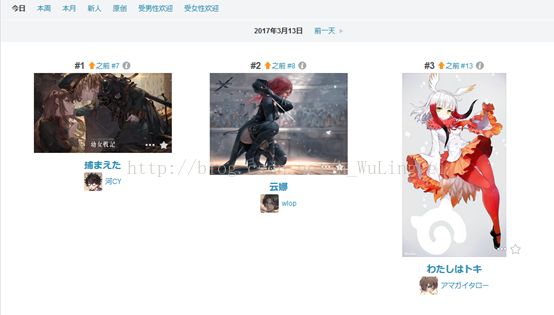
接着自然要明确我们需要抓取的页面的链接(url),既然要抓每日排行榜,链接便是http://www.pixiv.net/ranking.php?mode=daily。链接它之前我们先使用浏览器查看一下源代码,因为我们编写程序其实就是在模仿浏览器的操作。
在打开的页面上按下f12进入开发者模式,使用其中的选择页面元素的功能。这样我们可以明白某一个图片所在的div。

那我们想得到的图片的url藏在哪里呢?点击上图标识的按钮后再点击相应的图片,就可以找到它所在的div。
我们查看了第一张图,它的div如下图:

红线标识了这张图片在p站的源地址是http://i3.pixiv.net/c/240x480/img-master/img/2017/03/12/18/02/13/61873774_p0_master1200.jpg。
打开这个地址,果然我们看到了在排行榜上显示的图片。

但是有个问题,如果我们按照这个链接来下载的话会发现图很小。
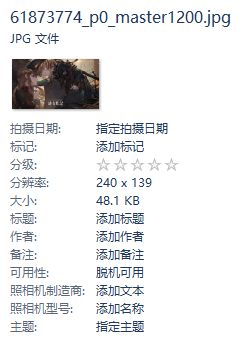
分辨率只有240*139,这显然不科学。这表示p站并没有直接引用原图,那原图在哪里呢?
在排行榜上直接点击后,会进入这张图的详情。

在详情页在点击之后,我们发现呈现在我们面前的就是一张作者提交的原始图片了。

那这张图的url是什么呢?同样的继续使用f12进入调试模式,查看它的url。
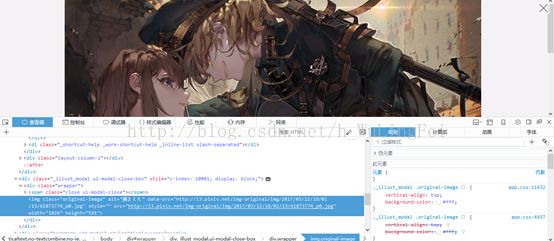
地址显而易见。
![]()
使用这个url下载的结果很正常。
这个地址和我们直接从排行榜那获取的有什么不一样呢?我们把它们拿过来进行比较。
排行榜上的链接:http://i3.pixiv.net/c/240x480/img-master/img/2017/03/12/18/02/13/61873774_p0_master1200.jpg。
原始链接:http://i3.pixiv.net/img-original/img/2017/03/12/18/02/13/61873774_p0.jpg。
很明显,p站把原图放到了这个img-original文件夹下,在排行榜上显示的是处理过的图片。通过多张图片的分析,我们发现对于大多数图片这两个链接是有联系的。
首先它们的域名是一样的,p站有很多个服务器,但是这两张图片基本上是放在同一个服务器上。接着它们的前缀只是“/c/240x480/img-master/”和“/img-original/”有差别,后缀只是在p0后面一个还有值,一个并没有。除此之外,大部分图片的排行榜链接是以jpg为后缀的,而有的图片的原始链接并不是jpg,而是png。也就是说原始链接分jpg和png两种,但是排行榜上的图片只有jpg一种格式。
这样一分析,我们就明白我们该干什么了。对字符串进行改造,从获取的排行榜上的链接拼凑出原始链接。
好,开干了。这里介绍一下urllib库。这是python3中的一个用于网络连接的库,python2.7里的名字是urllib2。
urllib.request.urlopen函数接受一个url参数,模拟打开这个网页并将接受到的数据返回。通过返回值的read函数可以得到返回数据的字符串,一般是二进制编码的,可以用decode解码成utf8的格式。
利用urllib库给服务器发请求,获得相应的html文件。写成一个函数getHtml
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read().decode('utf-8')
return html
之后利用正则表达式来获取页面中的图片链接。在这里就要使用浏览器的查看源代码的功能来对html进行分析。

这就是查看到的源代码。利用关键词查找,可以发现链接全写在第353行。
第一张图的源码为
r'data-filter="thumbnail-filterlazy-image"data-src="(.+?\.jpg)"data-type'之后使用python的正则表达式功能,便能获取到该html中的所有需要的图片链接。
拿到这个连接之后,接下来该干的事情就是对它进行改造。使用str的replace功能,进行如下的替换:
url=url.replace('c/240x480/img-master','img-original')
url=url.replace('_master1200','')
这里就是重头戏了,将图片下载到本地。
由于原始链接可能是png和jpg格式,所以要做两手准备。首先使用jpg的版本请求图片资源,如果失败再尝试使用png的版本去请求,这样就不会出现问题了。
try:
req = urllib.request.Request(url, None, Headers)
res = urllib.request.urlopen(req, timeout=1)
res.close()
except urllib.error.HTTPError:
url = url.replace('.jpg', '.png')
req = urllib.request.Request(url, None, Headers)
res = urllib.request.urlopen(req, timeout=1)
res.close()
另外这里面有一个referer的问题,在向服务器请求图片的时候p站为了防止盗链,如果在请求头里面的referer不对的话是会请求失败的。所以需要在请求的时候再请求头里加入一个Referer。它的格式是”http://www.pixiv.net/member_illust.php?mode=manga_big&illust_id=”加上图片的id号再加上” &page=0”。其实也就是在我们点击查看原图之前的那个链接。构造了一个getReferer函数来处理这个问题。
def getReferer(url):
reference = "http://www.pixiv.net/member_illust.php?mode=manga_big&illust_id="
reg = r'.+/(\d+)_p0'
return reference + re.findall(reg,url)[0] + "&page=0"
循环这样的工作,便可以下载当天排行榜里的所有图片。
另外也可以选择爬取不同日期的排行榜的数据。p站在主服务器里存储了这些数据,并且可以访问。主要是通过链接中的date参数来识别到底是请求哪一天的数据。
例如这个http://www.pixiv.net/ranking.php?mode=daily&date=20170312便是请求2017年3月12日的数据。其余的操作和上面讲的类似,只是换一下链接罢了,而这个链接也可以通过自己构造的方式来获得。这样我们就可以获取任意天数的p站图片数据了。
最后总结一下,我在这篇文章中只是大致介绍了爬虫的基本思想以及实现的基本方法,通过爬取p站图片为例来讲解。当然这里讲解的内容其实比较简陋,有些东西并没有深入去展开,例如爬取图片的时候可以使用多进程技术来增加效率,爬取的时候可以根据不同的需要来获取不同的图片。