大数据学习笔记-------------------(30)
第30章 HBASE架构与安装
30.1 HBase架构
在HBase中,表分割成区域并由区域服务器提供服务。 区域被列族垂直划分为"Stores"。 Stores保存为HDFS中的文件。下面显示的是HBase的架构。
Note:术语"store"用于区域以解释存储结构
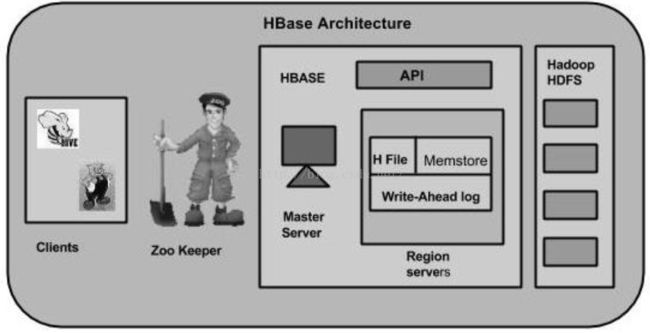
HBase有三个主要组件:客服端库(Client Library)、主服务器(Master Server)、区域服务器(Region Server)。可以根据需要添加或删除区域服务器。
30.1.1主服务器(MasterServer)
主服务器功能如下:
1.将区域分配给区域服务器,并获得Apache ZooKeeper对此任务的帮助
2.处理区域服务器之间的区域负载平衡。它卸载繁忙的服务器并将区域转移到占用较少的服务器
3. 通过协商负载平衡来维护集群的状态
4.负责模式更改和其他元数据操作,如创建表和列族
30.1.2 分区及分区服务器
区域只是分割并分布在区域服务器上的表。区域服务器有如下类型的区域:
Ø 与客户端通信并处理与数据相关的操作
Ø 处理对其下所有区域的读取和写入请求
Ø 按照区域大小阈值确定区域的大小
当深入研究区域服务器时,它包含区域和商店(Stores),如下所示:
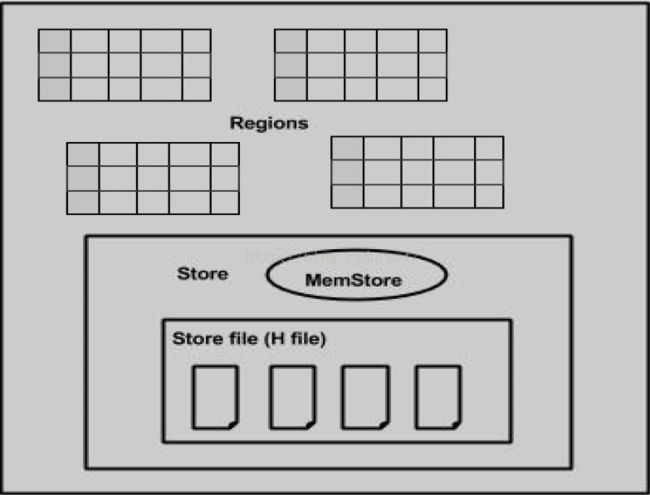
Store包含内存Store和HFiles。Memstore就像一个缓存。任何输入到HBase的东西都存储在这里。 随后,数据将作为块传输并保存在Hfiles中,并刷新memstore。
30.1.3 Zookeeper
Ø Zookeeper是一个开源项目,提供诸如维护配置信息、命名、提供分布式同步等服务。
Ø Zookeeper具有表示不同区域服务器的临时节点。 主服务器使用这些节点来发现可用的服务器。
Ø 除可用性之外,节点还用于跟踪服务器故障或网络分区。
Ø 客户端通过zookeeper与区域服务器通信。
Ø 在伪和独立模式下,HBase本身将负责zookeeper
30.2 HBase安装
由于在第四部分,已经安装并配置好JAVA、Hadoop环境。基于第四部分配置好的环境,配置并安装HBase的步骤如下:
Step_1:以单独模式安装HBase
在链接: http://mirrors.cnnic.cn/apache/hbase/stable/ 使用"wget"命令下载最新稳定版本的HBase。进入到下载文件路径下,解压下载的HBase文件,执行操作的命令如下:
$su -
password: enter your password here
$cd /usr/local
$wget http://mirrors.cnnic.cn/apache/hbase/stable/hbase-1.2.3-bin.tar.gz
$tar -zxvf hbase-1.2.3-bin.tar.gz
$mv hbase-1.2.3-bin hbase执行结果如下:

Step_2:以单独模式配置HBase
在启动HBase之前,需要配置如下文件。
1.hbase-env.sh
打开hbase-env.sh文件,在文件中配置JAVA_HOME路径,执行命令如下:
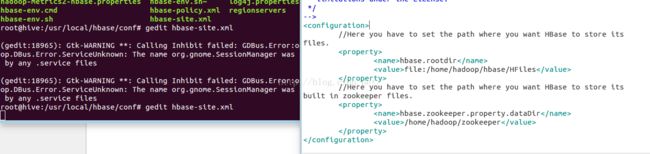
2.hbase-site.xml
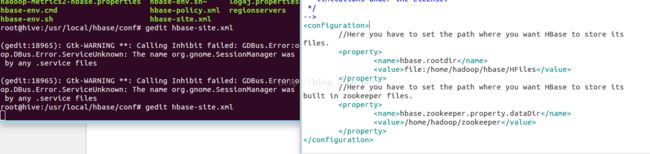
进入到文件所在路径,打开文件,在文件中添加如下信息:
//Here you have to set the path where you want HBase to store its files.
hbase.rootdir
file:/home/hadoop/HBase/HFiles
//Here you have to set the path where you want HBase to store its built in zookeeper files.
hbase.zookeeper.property.dataDir
/home/hadoop/zookeeper
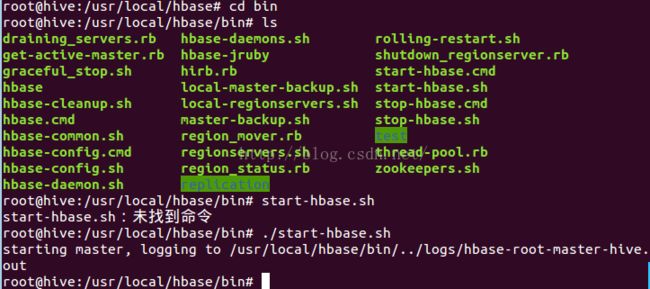
到这,HBase安装和配置部分已经配置成功。到hbase文件夹中的bin文件下,运行shell脚本"start-hbase.sh"启动HBase服务,如果配置信息都正确,当运行HBase启动脚本命令时,将会给出如下图所示的响应信息。执行命令如下所示:
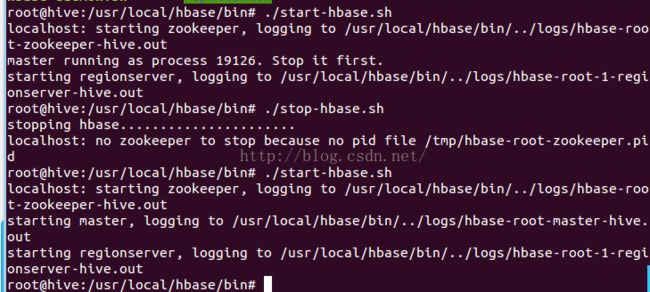
Step_2:以伪分布式模式安装HBase
在启动HBase时,配置Hadoop和本地系统或远程系统的HDFS并确保hadoop和hdfs正在运行。如果HBase正在运行,停止HBase。
hbase-site.xml
在文件中添加如下属性
hbase.cluster.distributed
true
hbase.rootdir
hdfs://localhost:8030/hbase
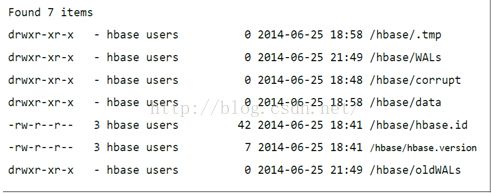
Ø 检查HDFS下的HBase路径
HBase创建它在HDFS中的路径。执行命令"hadoop fs -ls /hbase",查看创建的路径。如果存在或者路径下有文件。格式类似如下:
Step_3:启动和停止Master服务
进入hbase文件夹下的bin,使用"local-master-backup.sh",最多可以启动10服务器。启动的命令如下:"
$/usr/local/hbase/bin/local-master-backup.sh 2 4如果想关闭一个backup Master,需要知道该进程id,把id存进一个名为"/tmp/hbase-USER-X-master.pid",执行命令关闭backup master服务:
$cat /tmp/hbase-user-1-master.pid |xargs kill -9 Step_4:启动和关闭分区服务器(Region Servers)
执行如下命令:
$/usr/local/hbase/bin/local-regionservers.sh start 2 3$/usr/local/hbase/bin/local-regionservers.sh stop 3Step_5:启动HBase Shell
按照如下序列,启动HBaseShell。打开终端,切换到超级用户。
1. 启动Hadoop文件系统
执行命令启动hadoop文件系统:
2. 启动HBase
进入到hbase文件夹下的bin文件,执行命令"./start-hbase.sh",启动HBase
3. 启动HBase Master Server
进入到hbase文件夹下的bin文件,执行命令"./ local-master-backup.sh start2",启动Master Server
4. 启动 Region Server
进入到hbase文件夹下的bin文件,执行命令"./ local-regionservers.sh start2",启动Region Server
5. 启动HBase Shell
进入到hbase文件夹下的bin文件,执行命令"./hbase shell",执行成功,会弹出如下对话框:
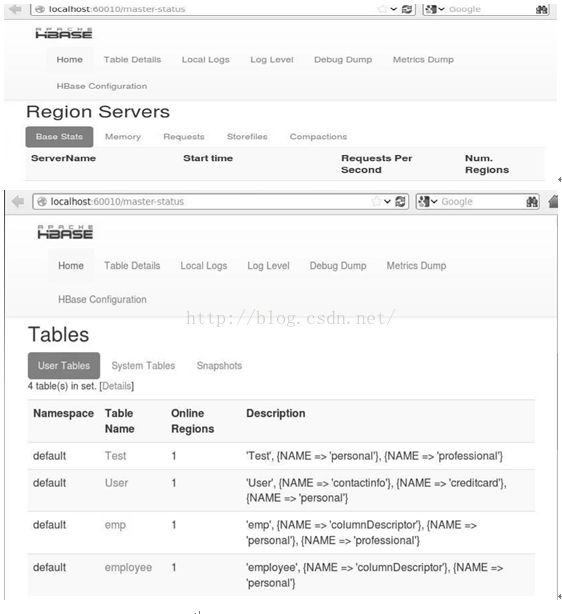
Step_6:HBaseWeb接口
点击打开链接