爬虫原理与会话保持(cookies、session)详解--python实现
-
- 一、爬虫原理
- 1、HTTP原理
- 2、HTTP请求
- 2.1 HTTP request
- 2.2、HTTP response
- 二、Session和Cookies
-
- 1,无状态HTTP
- 2、session与cookies
- 3,会话维持
-
- 三、代码实现
- 一、爬虫原理
一、爬虫原理
我们知道互联网是由大量计算机和网络构成的复杂系统,我们可以将其形象的比喻成一张蜘蛛网。网络的节点是计算机,计算机中储存着大量的数据。爬虫程序就是通过网络去采集指定计算机中数据的工具。一般来说,我们采集的数据大多是网页上的数据,也就是我们平时可以在浏览器软件上浏览互联网上的web,因此爬虫程序的道理也很简单,就是模仿浏览器去获取指定站点的网页,通过机器来看我们需要采集数据的网页,并把我们需要的数据的保存起来。
1、HTTP原理
互联网在传输数据的时候需要遵循一定的规范格式,其中我们在使用浏览器浏览网页的时候就需要遵循HTTP协议,中文名称为超文本传输协议。HTTP协议主要用来传输超文本(网页等)数据。类似的协议还有ftp(主要用来传输文件)等
我们需要采集指定计算机中的数据,那么我们怎么才能找到这台计算机呢? HTTP协议使用URL来定位计算机和计算机中的数据资源。例如https://www.blog.csdn.net/hfutzhouyonghang就是一个URL,在浏览器上输入这串字符,就可以找到我的博客了。https表示协议的名称,https是http协议的加密版本。www.blog.csdn.net表示服务器的域名,通过转换可以变成ip地址,可以通过域名在茫茫互联网上定位到csdn的服务器。最后/hfutzhouyonghang该服务器web站点下的资源。
2、HTTP请求
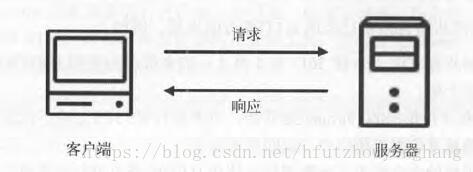
我们在浏览器上输入一个URL,按下回车之后很快就看到了页面的内容,这其中包含了很复杂的过程,我们需要了解的是,我们的浏览器向URL指向的服务器发出了http请求request,服务器处理请求之后,返回响应response。浏览器根据response中的源代码等内容进行解析,渲染之后我们就可以在浏览器上看到丰富多彩的内容了。其模型如下:
2.1 HTTP request
打开浏览器的检查元素,选择一个请求:
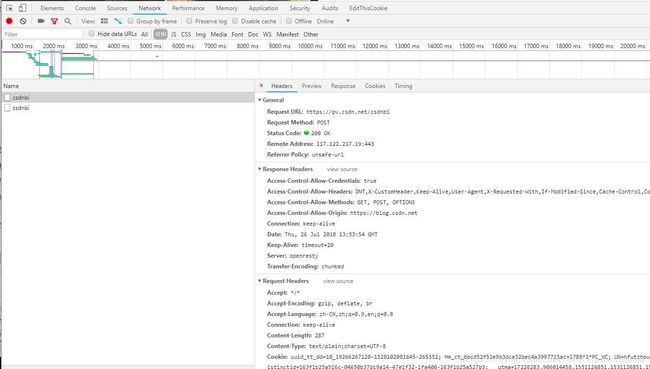
我们可有看到reques主要t由一下部分组成:
- Request URL:即我们的请求地址。
- Request Method:常用请求方法有两种,一种是GET方法,其请求的参数会以明文形式加 在URL后面,因此具有一定的长度限制。一种POST方法,POST方法会将请求中的参数(例如,用户名和密码)加密后传到服务器。
- Request Header:header是比较重要的一部分,header携带了大量重要的信息,我们在写爬虫程序时要格外注意,其中header包含的部分如下:
- Accept: 用于浏览器可以接受哪些类型的图片。
- Accept-Lang:用于指定浏览器可有接受哪些语言。
- Accept-Encoding:用于指定浏览器可以接受的内容编码。
- Host:用于指定请求资源的主机IP地址和端口号。
- Cookie:用于维持用户当前的会话,通常会有多个cookie。
- Referer:表示请求从那个页面发过来的
- User-Agent:它为服务器提供当前请求来自的客户端的信息,包括系统类型、浏览器信息等。这个字段内容在爬虫程序种非常重要,我们通常可以使用它来伪装我们的爬虫程序,如果不携带这个字段,服务器可能直接拒绝我们的请求。
- Content-Type:用来表示具体请求中媒体类型信息,text/html 表示HTML格式,image/gif表示GIF图片,application/json表示json数据等,更过的类型大家可以去百度上搜下。
- request body:请求体中放的内容时POST请求的表单数据,GET请求没有请求体。
2.2、HTTP response
服务器处理好用户提交的请求后,向用户返回响应,响应主要由一下三个部分组成:
- 响应状态码:状态码表示服务器的响应状态,例如200代表服务器正常响应,404表示页面未找到,500表示服务器内部错误等,具体可有在百度上查。
- 响应头:响应头包含了服务器对请求的应答信息,常见字段如下:
- Data:表示产生响应的时间。
- Last-Modified:表示获得的资源最后的修改时间。
- Server:包含服务器信息,比如名称、版本号等。
- Content-Type:表示返回的数据类型是什么。比如text/html 表示返回html文档。
- Set-Cookie:告诉浏览器下次请求时需要带上该字段中的Cookie,这个非常重要,是服务器识别用户和维持会话的重要手段。
- Expires:指定响应的过期时间,可以是代理服务器或者浏览器将加载的内容更新到缓存中,如果再次访问,就可以从缓存中加载,缩短加载时间。
- 响应体:响应体的内容非常重要,如果说响应状态码、响应头是包裹上的快递单信息,那么响应体就是包裹里的东西了。我们需要解析的就是响应体。我们在请求网页时,其响应体就是html代码,请求一张图片时,响应体内容就是图片的二进制数据。
二、Session和Cookies
在浏览一些网站,比如购物的时候,我们常常需要先登陆,登陆过后我们可以连续访问网站,并且可以将我们需要的购买的东西加入购物车。但是有时候我们中途过了一段时间没有操作就需要重新登陆。还有某些网站,打开网页之后就已经登陆了。这些功能看起来来很神奇,其实都是Session和Cookie在发挥作用。
1,无状态HTTP
Http有个特点,即无状态。什么叫无状态呢。Http无状态是指Http协议对事务处理没有记忆能力,当我们向服务器发送请求后,服务器处理请求之后返回结果。这是一个独立的过程,再次向服务器发出请求,服务器做出响应又是一次独立的过程。不会有一条网线一直连着你的电脑和服务器来完成你的所有请求。因此,服务器并不知道收到的两次请求是否来自同一个用户。这种效果并不是我们想要的。为了保持前后的状态,我们需要将前面所有请求中的数据再重传一次,这是非常麻烦和浪费资源的。为了解决这个问题,用于保持HTTP连接状态的Session和Cookies就出现了。
2、session与cookies
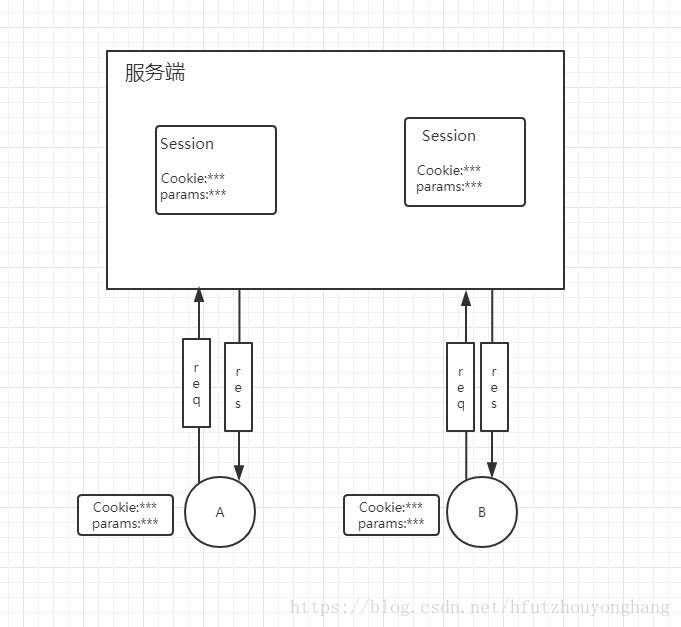
session是指从我们打开一个网站开始至我们关闭浏览器一系列的请求过程。比如我们打开淘宝网站,淘宝网站的服务器就会为我们创建并保存一个会话对象,会话对象里有用户的一些信息,比如我们登陆之后,会话中就保存着我们的账号信息。会话有一定的生命周期,当我们长时间(超过会话有效期)没有访问该网站或者关闭浏览器,服务器就会删掉该会话对象。
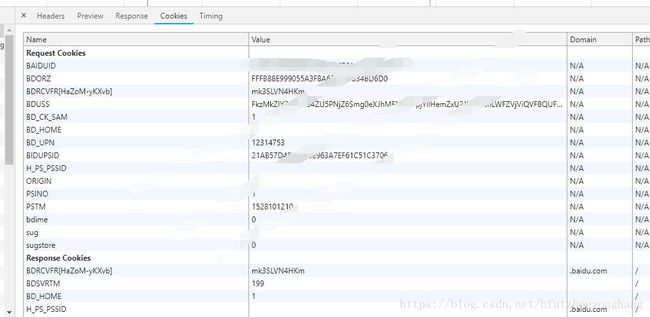
cookies是指网站为了辨别用户身份,进行会话跟踪而储存在本地终端的数据,cookies一般再电脑中的文件里以文本形式储存。cookies其实是有键值对组成的,如下图所示:
3,会话维持
当客户端浏览器第一次请求服务器时,服务器会再response中设置一个Set-Cookies的字段,用来标记用户的身份,客户端浏览器会把cookies保存起来,cookies中保存的有Session的id信息。当客户端浏览器再次请求该网站时,会把Cookies放在请求头中一起提交给服务器,服务器检查该Cookies即可找到对应的会话是什么,再通过判断会话来辨认用户的状态。
当我们成功登陆网站时,网站会告诉客户端应该设置哪些Cookies信息,以保持登陆状态。如果客户端浏览器传给服务器的cookies无效或者会话过期,可能就会收到错误的响应或者跳转到登陆页面重新登陆。
三、代码实现
我们以登陆豆瓣网为例,来看一下如何处理cookies数据,我们使用了Resquests第三方库。
1. 首先我们构造一个header,并将header带入请求中。
import requests
headers = {'Host': 'www.douban.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive'
}
res = requests.get("https://www.douban.com/accounts/login",headers=headers)
#查看状态码
>>>res.status_code
200
#查看headers,注意第一次请求豆瓣,响应体中的Set-Cookies字段
>>>res.headers
{'Date': 'Sat, 28 Jul 2018 14:47:46 GMT', 'Content-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Keep-Alive': 'timeout=30', 'Vary': 'Accept-Encoding', 'X-Xss-Protection': '1; mode=block', 'X-Douban-Mobileapp': '0', 'Expires': 'Sun, 1 Jan 2006 01:00:00 GMT', 'Pragma': 'no-cache', 'Cache-Control': 'must-revalidate, no-cache, private', 'X-Frame-Options': 'SAMEORIGIN', 'Set-Cookie': 'bid=NURXfALBCrM; Expires=Sun, 28-Jul-19 14:47:46 GMT; Domain=.douban.com; Path=/', 'X-DOUBAN-NEWBID': 'NURXfALBCrM', 'X-DAE-Node': 'brand56', 'X-DAE-App': 'accounts', 'Server': 'dae', 'Strict-Transport-Security': 'max-age=15552000;', 'Content-Encoding': 'gzip'}
#查看cookie,直接获取cookie,将会获取到cookieJar对象,事实上requests中就是用该对象储存cookies的
>>>res.cookies
0, name='bid', value='NURXfALBCrM', port=None, port_specified=False, domain='.douban.com', domain_specified=True, domain_initial_dot=True, path='/', path_specified=True, secure=False, expires=1564325266, discard=False, comment=None, comment_url=None, rest={}, rfc2109=False)]>
>>>for cookie in res.cookies:
print(cookie.name+"\t"+cookie.value)
bid NURXfALBCrM
#我们可以将第一次请求的响应中的Set-cookies添加进来,事实上requests库会自动帮我们做这些
>>>cookieJar = requests.cookies.RequestsCookieJar()
>>>for cookie in res.cookies:
cookieJar.set(cookie.name,cookie.value)
>>>cookieJar
0, name='bid', value='NURXfALBCrM', port=None, port_specified=False, domain='', domain_specified=False, domain_initial_dot=False, path='/', path_specified=True, secure=False, expires=None, discard=True, comment=None, comment_url=None, rest={'HttpOnly': None}, rfc2109=False)]>
>>>for cookie in res.headers['Set-Cookie'].split(";"):
key=cookie.split('=')[0]
value=cookie.split('=')[1]
cookieJar.set(key,value)
#看一下现在cookieJar中内容
>>>cookieJar
0, name=' Domain', value='.douban.com', port=None, port_specified=False, domain='', domain_specified=False, domain_initial_dot=False, path='/', path_specified=True, secure=False, expires=None, discard=True, comment=None, comment_url=None, rest={'HttpOnly': None}, rfc2109=False), Cookie(version=0, name=' Expires', value='Sun, 28-Jul-19 14:47:46 GMT', port=None, port_specified=False, domain='', domain_specified=False, domain_initial_dot=False, path='/', path_specified=True, secure=False, expires=None, discard=True, comment=None, comment_url=None, rest={'HttpOnly': None}, rfc2109=False), Cookie(version=0, name=' Path', value='/', port=None, port_specified=False, domain='', domain_specified=False, domain_initial_dot=False, path='/', path_specified=True, secure=False, expires=None, discard=True, comment=None, comment_url=None, rest={'HttpOnly': None}, rfc2109=False), Cookie(version=0, name='bid', value='NURXfALBCrM', port=None, port_specified=False, domain='', domain_specified=False, domain_initial_dot=False, path='/', path_specified=True, secure=False, expires=None, discard=True, comment=None, comment_url=None, rest={'HttpOnly': None}, rfc2109=False)]>
#模拟登陆
>>>data = {
'source':'None',
'redir':'https://movie.douban.com/',
'form_email':'*****',
'form_password':'****'
}
#使用Session对象提交请求,相当于在浏览器中连续操作网页,而如果直接使用```request.post()```,则相当没提交一次请求,则打开一个浏览器,我们在实际使用浏览器的经验告诉我们,这样是不行的。
>>>session = requests.Session()
>>>res =session.post('https://www.douban.com/accounts/login',headers=headers,cookies=cookieJar,data=data)
>>>res.status_code
200
#此时,如果实在浏览器的话,我们应该可以看到已经登陆成功,并且跳转到了https://movie.douban.com/,页面,使用这个Session直接访问的我的账号,检查一下,是否是我的账号在登录状态。
>>>res = session.get('https://www.douban.com/accounts')
>>>res.text
'\n\n \n \n \n \n \n \n smart_hang的帐号\n \n 我们看到已经成功登陆豆瓣网,并使用Cookie和Session保持登录状态,这样我们就可以更好的采集数据啦!