强化学习之无模型方法二:时间差分
时间差分方法(TD)是强化学习中最核心的也是最新奇的方法,混合了动态规划(DP)和蒙特卡洛方法(MC)
- 和MC类似,TD从历史经验中学习
- 和MDP类似,使用后继状态的值函数更新当前状态的值函数
TD属于无模型方法,未知P和R,同时应用了采样和贝尔曼方程,可以从不完整的片段中学习,通过估计来更新估计
时间差分评价
时间差分策略评价算法
目的:给定策略 π π ,求其对应的值函数 vπ v π
增量式MC是从数据中重复采样,每得到一个路径更新一次回报值:
时间差分算法(Temporal-difference,TD)使用估计的回报值 Rt+1+γV(St+1) R t + 1 + γ V ( S t + 1 ) 去更新值函数 V(St)(TD(0)) V ( S t ) ( T D ( 0 ) )
其中 Rt+1+γV(St+1) R t + 1 + γ V ( S t + 1 ) 称为 TD目标, Rt+1+γV(St+1)−V(St) R t + 1 + γ V ( S t + 1 ) − V ( S t ) 称为 TD误差

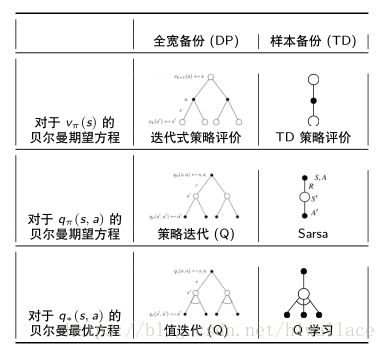
TD VS. DP
DP利用了贝尔曼方程,全宽概率分布求解,TD也利用了贝尔曼方程,主要做了几点改动:
全宽备份 → → 样本备份,并去掉了期望符号
V(S)←R+γV(S′) V ( S ) ← R + γ V ( S ′ )DP全宽备份 VS. TD样本备份


增加学习率,设置0-1的学习率,让更新步长不那么大,因为非全采样,可能会采样到不好的样本。
V(S)←V(S)+a(R+γV(S′)−V(S)) V ( S ) ← V ( S ) + a ( R + γ V ( S ′ ) − V ( S ) )
利用TD目标和当前值函数的差(时间查分),收敛后 V(S)=R+γV(S′) V ( S ) = R + γ V ( S ′ )TD VS. MC
【举例】Driving Home
如下图所示,


MC学习的是预测和实际的时间差,TD预测的是基于前序状态的偏差
优缺点对比:
TD算法在知道结果之前学习
- TD算法在每一步之后都能在线学习
- MC算法必须等待回报值得到之后才能学习
TD算法即便没有最终结果也能学习
- TD算法能够从不完整序列中学习,且适用于连续性片段和片段性任务
- MC算法仅仅能够从不完整序列中学习,仅仅适用于片段性任务
TD算法有多个驱动力
- TD算法有奖励值和状态转移作为更新的驱动力
- MC算法只有奖励值作为更新的驱动力
TD在偏差和方差上的平衡
在监督学习中,偏差和方差的另外理解为欠拟合和过拟合,偏差大(欠拟合),说明精度低,预测值与样本之间的偏差较大;方差大(过拟合),说明样本值之间的方差大,样本的置信度较差,学出的模型适用性差,不同的机器学习方法会在两者之间权衡。
在强化学习中:
1. 回报值 Gt=Rt+1+γRt+2+...+γT−t−1RT G t = R t + 1 + γ R t + 2 + . . . + γ T − t − 1 R T 是值函数 vπ(St) v π ( S t ) 的无偏估计
2. 真实的TD目标值 Rt+1+γvπ(St+1) R t + 1 + γ v π ( S t + 1 ) 是值函数 vπ(St) v π ( S t ) 的无偏估计
3. 使用的TD目标值(估计值) Rt+1+γV(St+1) R t + 1 + γ V ( S t + 1 ) 是值函数 vπ(St) v π ( S t ) 的有偏估计
4. TD目标值的方差要远小于回报值,因为回报值依赖于很多随机变量 At,St+1,Rt+1,At+1,St+2,Rt+2... A t , S t + 1 , R t + 1 , A t + 1 , S t + 2 , R t + 2 . . . ,TD目标值仅仅依赖于一个随机序列 At,St+1,Rt+1 A t , S t + 1 , R t + 1
MC有高方差,零偏差
- 收敛性较好
- 对初始值不太敏感
- 简单,容易理解和使用
- 随着样本数量的增加,方差逐渐减少,趋近于0
TD有低方差,和一些偏差
- 通常比MC效率更高
- 表格法下TD(0)收敛
- 对初始值敏感
- 随着样本数量的增加,偏差数量减少,趋近于0
确定性等价估计(Certainty Equivalence estimate)

- MC收敛到最小均方误差的解
- 对样本回报值的最佳拟合
-

上图例子中,V(A)=0
- TD(0)收敛到最大似然马尔可夫模型中的解
- 对马尔可夫链的最佳拟合,假设了数据是来自P,R

- 对马尔可夫链的最佳拟合,假设了数据是来自P,R
上图例子中,V(A)=0+V(B)=0.75
TD利用了马尔可夫性,一般来说TD在马尔科夫环境中更有效
MC没有利用马尔可夫性,一般对非马尔可夫环境更有效
自举和采样
自举:使用随机变量的估计去更新,DP和TD都有自举,MC没有自举
采样:通过样本估计期望,MC和TD采样,是样本备份,DP不采样,是全宽备份

时间差分优化
TD的优化
TD的策略迭代:
- 策略评价:TD策略评价, Q=qπ Q = q π
- 策略提升:e-贪婪策略提升
注:策略评价和策略提升的策略更新方式相同即为在线策略,反之离线策略
TD优化相比MC优点是:低方差,在线更新,不完整序列
在线策略TD优化 — Sarsa
SARSA的备份如下:


SARSA在每个时间步骤进行迭代,策略评价 Sarsa, Q≈qπ Q ≈ q π ,策略提升 e-贪婪策略提升

SARSA评价函数用到时Q函数,且是在策略(执行的动作A来自于当前Q值下的e-贪婪策略,构建TD目标值是动作 A′ A ′ 来自于当前Q值下的e-贪婪策略,二者是同一个策略)
【Sarsa收敛性定理】
在满足一下条件时,Sarsa算法收敛到最优的状态动作值函数 Q(s,a)→q∗(s,a) Q ( s , a ) → q ∗ ( s , a )
- 策略序列 πt(a|s) π t ( a | s ) 满足GLIE
- 步长序列 at a t 是一个Robbins-Monro序列
∑t=1∞at=∞ ∑t=1∞a2t<∞ ∑ t = 1 ∞ a t = ∞ ∑ t = 1 ∞ a t 2 < ∞
- GLIE保证了
- 充分的探索
- 策略最终收敛到贪婪的策略
- Robbins-Monro保证了
- 步长足够大,足以客服任意初始值
- 步长足够小,最终收敛(常量步长不满足)

如上图所示,期望Sarsa:
- 减少了由于 A′ A ′ 的选择带来的方差
- 在相同更新步数时,期望Sarsa比Sarsa 的通用性更好
- 可以在在策略和离策略中切换
- 在策略:TD目标值中的策略和采样的策略是同一个策略
- 离策略:TD目标值中的策略和采样的策略是不同的策略
- 一种特殊情况,TD目标值中的策略选择贪婪策略,采样的策略选用e-贪婪策略–Q学习
离线策略TD优化 — Q-Learning
【离策略TD】
- 使用行为策略 μ μ 生成样本,然后评价目标策略 π π
- 需要利用重要性采样对TD目标值 R+γV(S′) R + γ V ( S ′ ) 进行加权
- 跟MC算法不同,仅仅只需要一次重要性采样率去矫正偏差
V(St)←V(St)+a(π(At|St)μ(At|St)(Rt+1+γV(St+1))−V(St)) V ( S t ) ← V ( S t ) + a ( π ( A t | S t ) μ ( A t | S t ) ( R t + 1 + γ V ( S t + 1 ) ) − V ( S t ) ) - 比MC的重要性采样方差小得多
思考:
离策略的TD算法对比MC算法,重要性采样率的因子数减小到1,能够减少到0?
答案是可以,可以对Q函数进行离策略学习,不需要考虑重要性采样率。因此就产生了Q学习算法:
- 目标策略选择Q(s,a)下的贪婪策略
π(St+1)=argmaxa′Q(St+1,a′) π ( S t + 1 ) = a r g m a x a ′ Q ( S t + 1 , a ′ ) - 行为策略 μ μ 选择Q(s,a)下的e-贪婪策略
- Q学习的TD目标值会得到简化:
Rt+1+γQ(St+1,A′) =Rt+1+γQ(St+1,argmaxa′Q(St+1,a′)) =Rt+1+maxa′γQ(St+1,a′) R t + 1 + γ Q ( S t + 1 , A ′ ) = R t + 1 + γ Q ( S t + 1 , a r g m a x a ′ Q ( S t + 1 , a ′ ) ) = R t + 1 + m a x a ′ γ Q ( S t + 1 , a ′ )

Q学习优化算法会收敛到最优的状态动作值函数, Q(s,a)→q∗(s,a) Q ( s , a ) → q ∗ ( s , a )

算法小结
DP Vs. TD