深度学习目标检测(一)——YOLOV2论文细节理解
0. 写作目的
好记性不如烂笔头。说实话,YOLO的论文真心难明白,文献[2]中解释的很到位。
1. Better
与Fast R-CNN相比,YOLOv1 的错误分析显示:YOLOv1有较低的召回率和回归框的错误。因此YOLOv2目的在于保持分类精度的同时,提高召回率和回归框的精度。保持运行速度快的特点。
YOLOv2没有通过放大YOLOv1的网络(基于GoogleNet)去提高精度,采用了一系列的方法来提高精度。
1.1 使用BN
使用BN能提高收敛且降低对其他类型的正则化依赖。
通过添加BN,提高2%的mAP。通过BN,作者丢弃了Dropout,仍没有过拟合。
1.2 Higher Resolution Classifier
YOLOv1训练分类网络在224 * 224, YOLOv2增加到448 * 448.
YOLOv2在ImageNet上以448 * 448进行finetune 分类网络10 epoch,然后在detection任务上进行finetune。高分辨率分类网络能提高近4%的mAP。
1.3 Convolutional With Anchor Boxes
YOLOv1直接采用全连接预测bounding boxes的坐标。Faster R-CNN使用hand-picked priors来预测bounding boxes。Faster R-CNN中的RPN只使用卷积层预测anchor boxes的offsets and confidences 。由于使用卷积层来预测,RPN在feature map的每一个位置预测offsets。预测offsets比预测坐标简化了问题,而且更网络更容易训练。
YOLOv2中移除了全连接层,并使用anchor boxes。首先,YOLOv2减少一层pooling层,使得网络的输出分辨率更高(为13 * 13,在YOLOv1中为7*7),将网络的输入调整为416 * 416而不是上面提到的448 * 448,这样做的目的是为了在feature map中得到奇数的位置(416 / 32 = 13)。由于物体,尤其是很大的物体,趋向于占据图像的中心,因此一个在中心的位置预测比四个周围的位置预测要好。
YOLOv2仍采用YOLOv1中的预测分类和目标。目标预测阶段仍预测提取的box和Ground True的IOU,类别预测阶段仍预测是否存在物体。
不使用anchor boxes,能达到69.5的mAP和81%的召回率,使用后达到69.2的mAP和88%的召回率。尽管mAP下降了,但是召回率增加了,这意味着模型有提高的空间。
1.4 Dimension Clusters
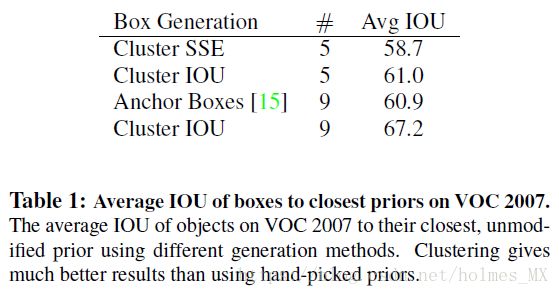
在YOLO中使用anchor存在两个问题。(问题二在1.5节中。)使用 Dimension Cluster提高了5%mAP.
问题一:手动选择box dimensions
尽管网络可以学习如何合适地调整boxes,但是如果我们能为网络选择好的先验知识,将会使得网络的更加简单地学习到如何预测好的检测结果。
相比使用人工选择先验知识,作者采用K-means来自动选择好的先验知识。如果K-means使用欧式距离,较大的框的错误比较小的框多。因此作者选择与IOU相关的距离来解决这个问题,即最大化IOU。具体公式如下:
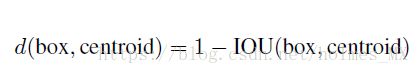
作者对不同的k值进行了探究,在速度和精度之间做一个trade-off,选择了k = 5。
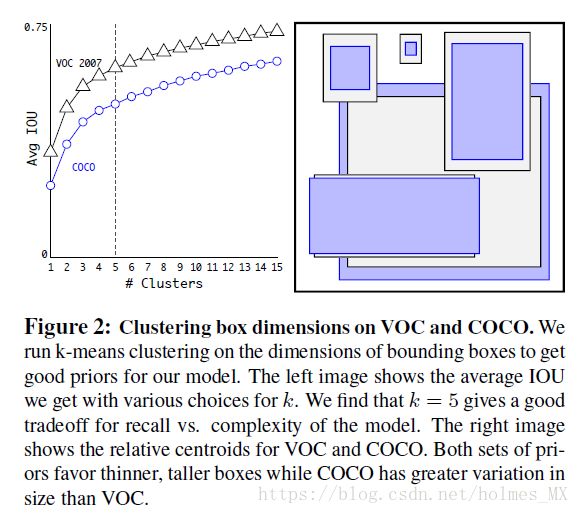
作者对k-means选择的结果和人工选择的anchor进行了对比,结果如下。结论是k-means选择的结果要比人工选择的anchor效果好。
1.5 Direct location prediction
当使用anchor后存在的第二个问题——模型的不稳定,尤其是在训练的初期。
大多数的不稳定来自于box的中心点的预测。基于RPN的预测缺乏约束,导致任意anchor box可能出现在图像的任意一点,而不考虑预测的box的位置。 这种带有随机初始化的模型花费很长一段时间去稳定合理的offsets。
YOLOv2继续YOLOv1的预测方法——预测相对于grid cell位置(即13 * 13)的位置坐标。这限制了Ground Truth落在0到1之间。作者使用logistic 激活函数来约束网络的输出落在这个范围内。
在输出的feature map(13 * 13)中,网络预测每一个cell的5个 bounding boxes,对于每个bounding boxes预测5个坐标,分别是tx, ty, tw, th 和to。
tx:预测的中心坐标x偏移量,
ty: 预测的中心坐标y偏移量,
tw:预测的宽度偏移量
th: 预测的高度偏移量,
to: 是具体某个物体类别的概率
Pr(object): 是否存在物体类别的概率
IOU(b, object): 参考[2]中给出的是:最高的分类结果概率。

1.6 Fine-Grained Features
提高1%的mAP。
YOLOv2调整为在13 * 13的feature map上预测(相比YOLOv1为7 * 7)。虽然对目标有好处,但是由于输出了更细致的feature因此对于小目标的定位也许有一定的帮助。 Faster R-CNN和SSD都在多样的分辨率feature map上运行。作者采用了一个不同的方法:简单地将之前26 * 26的特征通过 passthrough layer加到输出层(13 * 13)。
passthrough layer: 将之前的26 * 26 *512 转变为 13 * 13 * 2048。具体例子如下图:

然后将之前输出的13 * 13的feature map与passthrough之后的进行concate,实际上YOLOv2先将26 * 26 * 512的feature map进行1 * 1的卷积进行降低维度(26 * 26 * 64),然后再passthrough(13 * 13 * 256),最后在与原来的13 * 13 * 1024 feature map进行concate( 13 * 13 * 1280)。然后再次进行3 * 3 的conv进行缓冲一下(13 * 13 * 1024),然后采用1 * 1的卷积得到最终的输出:13 * 13 * 425((5 + 80)* 5)。(5个坐标 + 80类别(COCO)) * 5 个anchor。
1.7 Multi-Scale Training
作者希望YOLOv2在不同尺寸的图像上运行都很鲁棒,因此作者采用了多尺度训练。
作者每10个batch随机选择一个新的图像尺寸。由于作者的模型采用32倍的下采样,作者采用如下的尺寸:{320(32 * 10), 352(32 * 11), ..., 608(32 * 19)}。这种策略迫使网络学习预测不同的输入维度。意味着这个网络可以预测不同的输出分辨率。这个网络在运行较小尺寸是很快,所以YOLOv2提高了一个在精度和速度之间的trade-off版本。
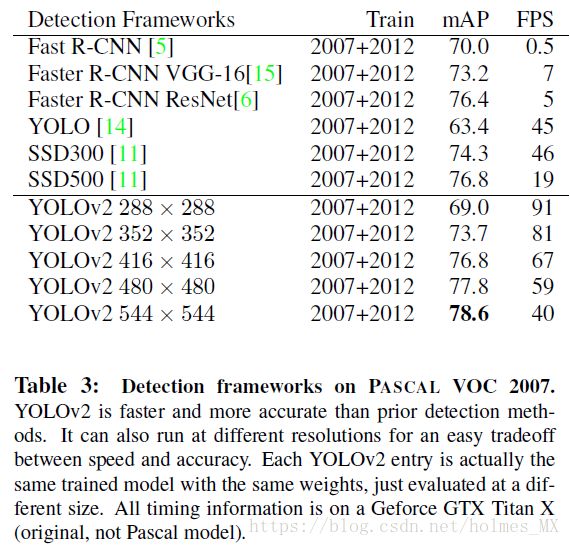
在288 * 288分辨率,YOLOv2运行超过90 FPS(Frames Per Second),同时mAP和Fast R-CNN一样。
在高分辨率下,YOLOv2有着最高的mAP78.6 on VOC2007数据集上,而且速度接近实时。
2. Faster
YOLOv1采用的是GoogleNet的框架,虽然比VGG16运行速度快,但是精度比VGG16差一些。对于single-scop来说,在ImageNet上的top-5精度上,VGG16是90.0%,而YOLOv1中的分类模型是88.0%。
因此作者采用了Darknet-19
2.1 DarkNet-19
借鉴先前建立网络的知识。
1) 借鉴VGG的网络:绝大多数采用3 * 3的卷积,每一次pooling 之后增加一倍chanel。
2) 借鉴Network in Network: 采用全局平均pooling进行预测和 在 3 * 3 卷积之间加入1 * 1的卷积降低特征表示(channel)。
3) 采用BN让训练更稳定、加速收敛、正则化模型。
VGG16需要 30.69 billion 浮点操作,YOLOv1需要 8.52 billion 浮点操作, 而Darknet-19只需要5.58 billion浮点操作,而且在ImageNet上top-1 acc 为72.9%, top-5 acc为 91.2% 。
网络为:
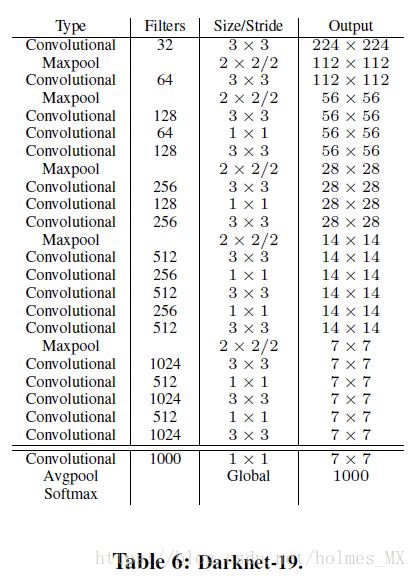
2.2 Darknet-19分类训练
SGD + momentum(0.9) 初始学习率0.1, 学习率多项式衰退,多项式指数为4。224 * 224 大概训练160个epoch。
loss: weight decay(0.0005)
data Augmentation: random crops , rotates, hue, saturation, exposure shifts。
在448 * 448 上finetune, learning rate = 1e-3,训练10个epoch。精度为top-1 76.5%, top-5 93.3%。
2.3 训练检测
对于分类网络,移除最后的卷积,然后加上3层 3 * 3 * 1024的卷积,然后加入passthrough(上面1.6中红色字体部分)。
训练参数:learning rate = 1e-3, 在60epoch和90epoch时,降低学习率为原来的1/10。共训练160个epoch。
weight decay 0.0005 + momentum(0.9)。
数据增广: 类似于 YOLOv1 + SSD的 random crops, color shifting。
在COCO和VOC的数据上使用相同的训练方式。
There may be some mistakes in this blog. So, any suggestions and comments are welcome!
注:本文的图片来自YOLOv2的paper。
[Reference]
[1] YOLOv2 paper: https://arxiv.org/abs/1612.08242
[2] YOLOv2 理解参考blog: http://machinethink.net/blog/object-detection/