【笔记】OpenCV3 Haar级联 人脸检测
-
CascadeClassifier 检测分类器
opencv的文件中提供了很多分类器,load这些分类器,就可以用来检测
摘抄一段大致的分类器的原理说明:
xml中存放的是训练后的特征池,特征size大小根据训练时的参数而定,检测的时候可以简单理解为就是将每个固定size特征(检测窗口)与输入图像的同样大小区域比较,如果匹配那么就记录这个矩形区域的位置,然后滑动窗口,检测图像的另一个区域,重复操作。由于输入的图像中特征大小不定,比如在输入图像中眼睛是50x50的区域,而训练时的是25x25,那么只有当输入图像缩小到一半的时候,才能匹配上,所以这里还有一个逐步缩小图像,也就是制作图像金字塔的流程
- 插个tip 关于haarcascade相关文件的路径,Anaconda里面是可以找到的。。
-
detectMultiScale函数
def detectMultiScale(self, image, scaleFactor=None, minNeighbors=None, flags=None, minSize=None, maxSize=None)
参数:
image:–待检测图片,一般为灰度图像加快检测速度;
scaleFactor:–表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1即每次搜索窗口依次扩大10%;
minNeighbors:–表示构成检测目标的相邻矩形的最小个数(默认为3个);
minSize和maxSize :用来限制得到的目标区域的范围。如果视频中误检到很多无用的小方框,那么就把minSize的尺寸改大一些,默认的为30*30
用个例子试试
import cv2
file_name = 'img/wei.jpg'
def detect(filename):
face_cascade = cv2.CascadeClassifier('./cascades/haarcascade_frontalface_default.xml')
img = cv2.imread(filename)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.1, 3)
for (x,y,w,h) in faces:
img = cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
cv2.namedWindow('face')
cv2.imshow('face', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == "__main__":
detect(file_name)default的分类器,有些误差。。

换alt

换alt2 (快速的Haar),效果还可以哦

换 haarcascade_frontalface_alt_tree,一个也没了,尴尬了。。

-
加上眼睛的分类器
tip:在绘制眼睛的时候,返回的坐标是人脸内的坐标,所以加上人脸的X,Y
不同的图片,眼睛的大小有点差异,所以要调整minSize参数,不然容易把鼻子、嘴巴也误检测。。
haarcascade_eye_tree_eyeglasses.xml准确性还可以,但是容易漏掉
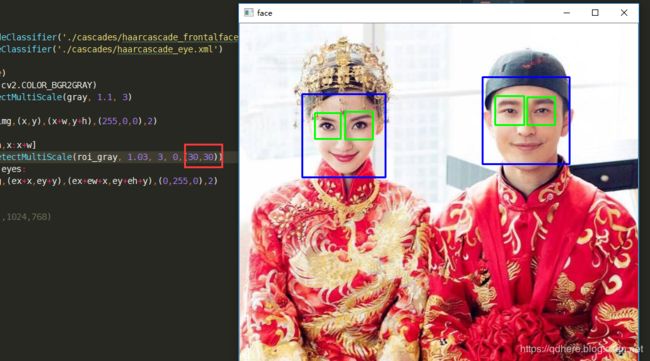
import cv2
file_name = r"img\Lena.jpg"
def detect(filename):
face_cascade = cv2.CascadeClassifier('./cascades/haarcascade_frontalface_alt2.xml')
eye_cascade = cv2.CascadeClassifier('./cascades/haarcascade_eye.xml')
img = cv2.imread(filename)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.1, 3)
for (x,y,w,h) in faces:
img = cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h,x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray, 1.03, 3, 0,(30,30))
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(img,(ex+x,ey+y),(ex+ew+x,ey+eh+y),(0,255,0),2)
cv2.namedWindow('face')
cv2.imshow('face', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == "__main__":
detect(file_name)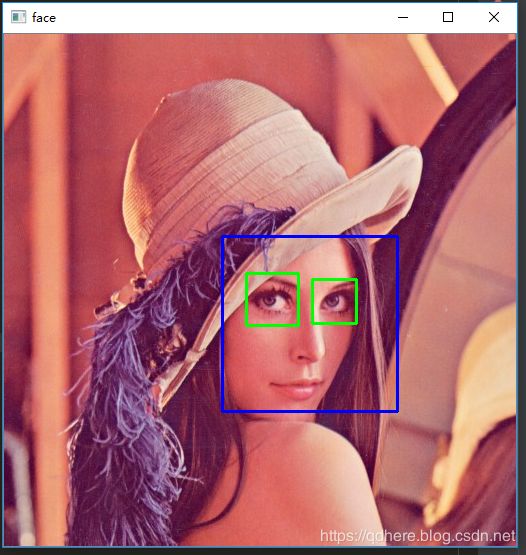
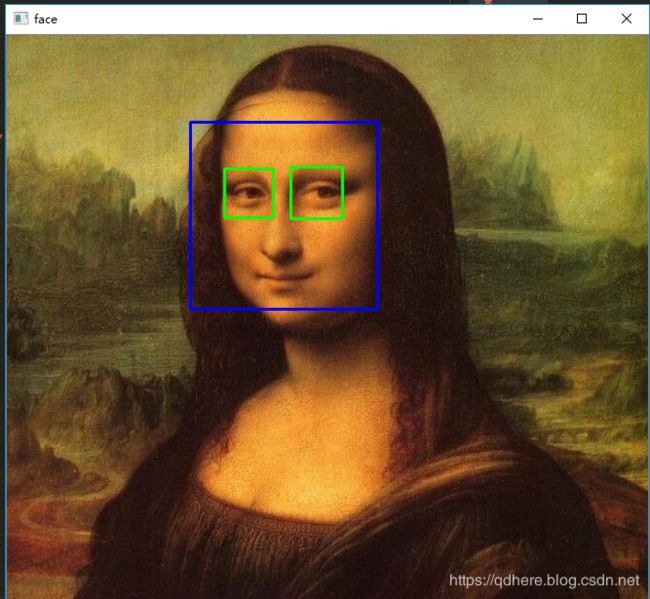
-
加上笑容检测
smile_Cascade = cv2.CascadeClassifier('./cascades/haarcascade_smile.xml')
smile = smile_Cascade.detectMultiScale(roi_gray, 1.2, 7, 0, minSize=(5, 5))
for (x2, y2, w2, h2) in smile:
cv2.rectangle(roi_color, (x2, y2), (x2 + w2, y2 + h2), (0, 0, 255), 1)
cv2.putText(img, 'Smile', (x, y - 7), 2, 1, (0, 255, 0), 2, cv2.LINE_AA)
-
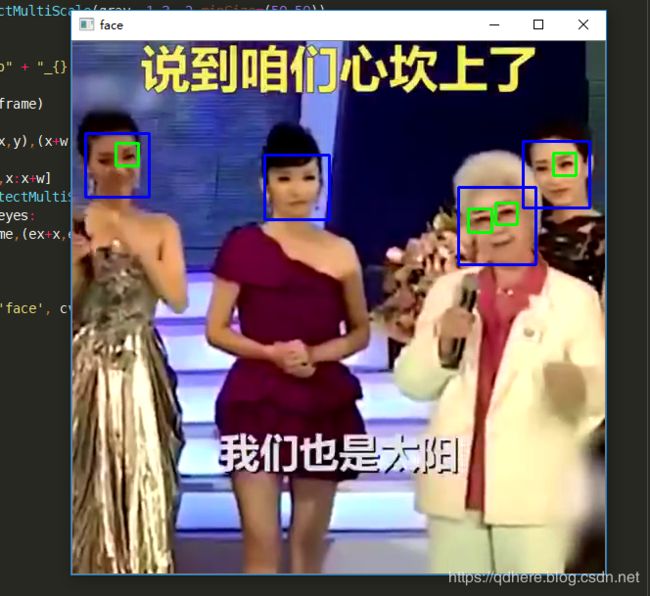
从视频中读取
稍微改造下,将视频一帧一帧读取出来,每一帧的图片就可以重复上面图片检测测步骤
添加新的函数,def detectFromVideo(filename),当filename传入0时,就可以从摄像头获取,当传入视频文件时,就会读取视频文件
def detectFromVideo(filename):
face_cascade = cv2.CascadeClassifier('./cascades/haarcascade_frontalface_alt2.xml')
eye_cascade = cv2.CascadeClassifier('./cascades/haarcascade_eye.xml')
camera = cv2.VideoCapture(filename)
isopen = camera.isOpened()
if not isopen:
print('打开摄像头失败...')
camera.set(3, 1280)
camera.set(4, 720)
cv2.namedWindow('face')
while isopen:
ret, frame = camera.read()
if ret:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5,minSize=(50,50),maxSize=(300,300))
if len(faces) > 1:
picfile = "./out/video" + "_{}.jpg".format(time.time())
cv2.imwrite(picfile, frame)
for (x,y,w,h) in faces:
cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h,x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray, 1.03, 5, 0,(15,15),(60,60))
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(frame,(ex+x,ey+y),(ex+ew+x,ey+eh+y),(0,255,0),2)
cv2.imshow('face', frame)
pressKey = cv2.waitKey(1)
if cv2.getWindowProperty('face', cv2.WND_PROP_AUTOSIZE) < 1:
break
if pressKey == 27: # ESC
print('退出。。。。。')
break
else:
break
camera.release()
cv2.destroyAllWindows()眼睛的识别不是很准确。。