ML:非监督学习 之 3 层次聚类Hierarchical Clustering with Python and Scikit-learn
by Usman Malik 《Hierarchical Clustering with Python and Scikit-learn》
层次聚类是用于无标签数据聚类的一种非监督学习算法。在某些情况下,层次聚类和KMeans的结果非常相似。在用Scikit-Learn实现层次聚类之前,有必要先了解其理论基础。
层次聚类的理论依据
层次聚类有2种:合并法和分类法,通常使用的是合并法。
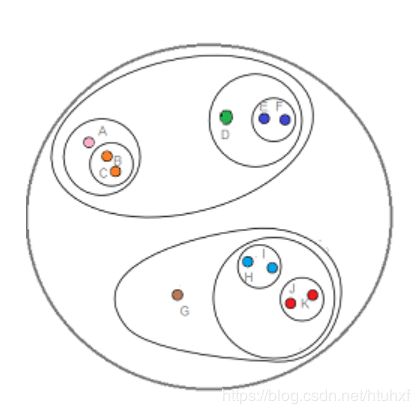
如图:合并法是从内而外、分类法是从外而内。本文也选择由内而外的合并法。
实现层次聚类的步骤
- 首先,把每个样本点作为一类,因此含有n个样本点的数据集就有n个cluster,即n类;
- 通过把相距最近的2个cluster归为1个,数据集变为n-1类;
- 重复以上步骤,把相距最近的2个cluster归为1个,数据集变为n-2类;
- 一直到数据集合并成1个类;
- 最后,根据实际需要,分成k个所需要的类;
目前有好几种测量cluster之间距离的方法,常见的是欧氏距离和曼哈顿距离。测量2个cluster距离时可以
- 使用2个cluster中最近2个样本点的距离
- 使用2个cluster中最远2个样本点的距离
- 使用2个cluster中心的距离
- 使用2个cluster中所有样本点组合距离的均值距离
树图对于层次聚类的作用
一旦我们使用合并法,迭代到只有1个(整体)cluster的时候,我们就用树图来把数据集划分为合理的k个(子)cluster。举个栗子:
我们有如下样本集
import numpy as np
X = np.array([[5, 3],
[10, 15],
[15, 12],
[24, 10],
[30, 30],
[85, 70],
[71, 80],
[60, 78],
[70, 55],
[80, 91]])
让我们把它画到图上看看:
import matplotlib.pyplot as plt
labels = range(1, 11)
plt.figure(figsize=(10, 7))
plt.scatter(X[:, 0], X[:, 1])
for label, x, y in zip(labels, X[:, 0], X[:, 1]):
plt.annotate(label,
xy=(x, y), # 要注释的点(坐标)
xytext=(-3, 3), # 要把注释放到点(x,y)的相对位置, 默认是挨着点(x,y),一般和textcoords搭配。
textcoords='offset points',
ha='right', # ha 和 va 设定点相对点的位置;
va='bottom')
plt.show()
结果如下:
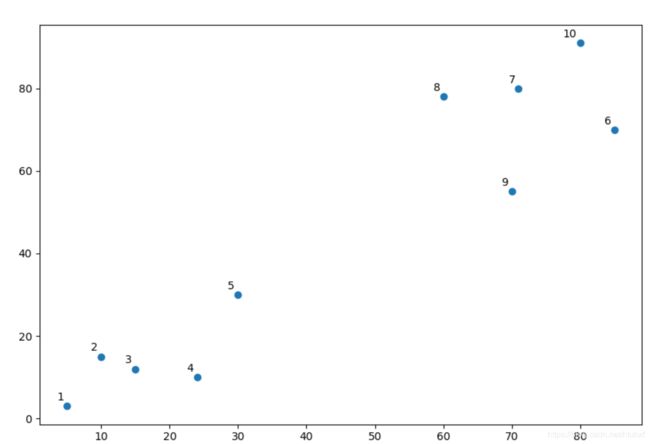
我们不妨把图命名为Graph1。一眼就能看出来,从1到5是1个cluster,从6到10是另1个cluster。
不过现实中,数据集往往很大,并且维度往往高于2,我们无法直观地进行分类,此时我们可以采用层次聚类自动进行聚类。
让我们同样使用刚才的数据,做出树图:
from scipy.cluster.hierarchy import dendrogram, linkage
import matplotlib.pyplot as plt
linked = linkage(X, 'single')
labellist = range(1, 11)
plt.figure(figsize=(10, 7))
dendrogram(linked,
orientation='top',
labels=labellist,
distance_sort='descending',
show_leaf_counts=True)
plt.show()
结果如下:
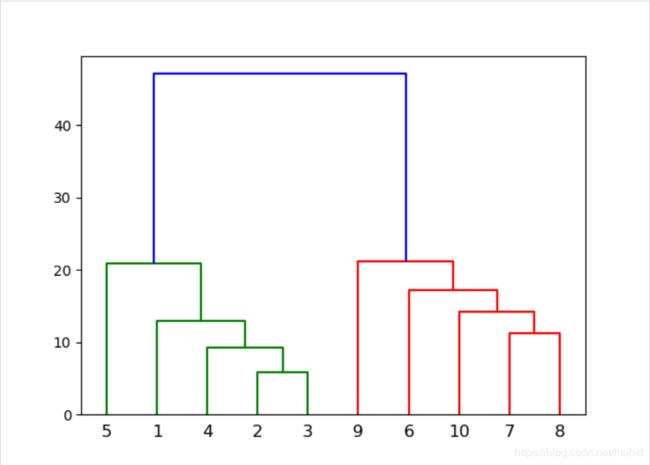
我们不妨把它命名为Graph2。回头看Graph1,可以看到样本点2和3最近,同时样本点7和8最近,因此cluster从这里开始,这从我们的Graph2上也能看到。样本点8和7、2和3先连线,连线的垂直高度代表2个点/cluster之间的欧氏距离。接下来就是以这2个cluster为生长点,不断把最近的点一个一个的聚合在一块形成一个大到的cluster,一直聚合到留下一个cluster。
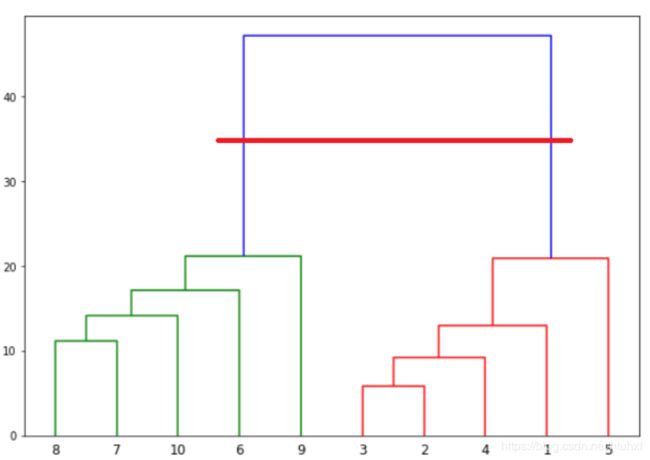
上图添加的红色横线,表示我们把数据集分成了2类,2个交点的距离就是分类的阀值,有k条垂直的连接线穿过红色横线就k类。
通过Scikit-Learn实现层次聚类
栗子1
import matplotlib.pyplot as plt
import numpy as np
X = np.array([[5, 3],
[10, 15],
[15, 12],
[24, 10],
[30, 30],
[85, 70],
[71, 80],
[60, 78],
[70, 55],
[80, 91]])
from sklearn.cluster import AgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters=2,
affinity='euclidean',
linkage='ward')
cluster.fit_predict(X)
print(cluster.labels_)
# 结果如下
[1 1 1 1 1 0 0 0 0 0]
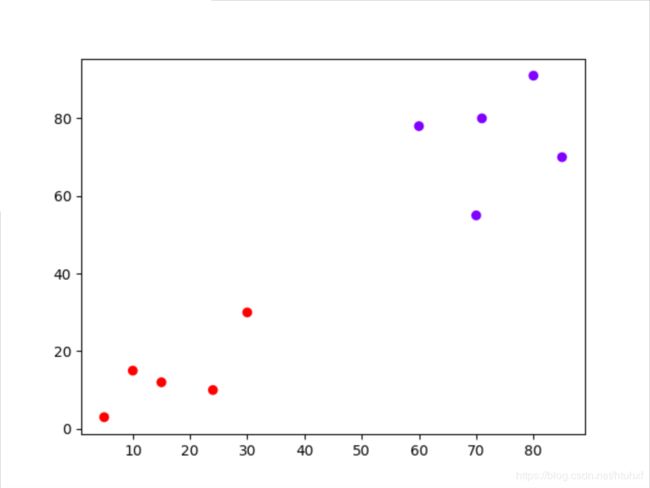
以上结果很清楚的表明,前5个样本点被归为1类;后5个样本点是1类。(注:结果中的数字1和0仅仅用于区分类别)
把结果放到图上:
plt.scatter(X[:, 0], X[:, 1], c=cluster.labels_, cmap='rainbow')
plt.show()
结果如下:
栗子2
结论
聚类方法简直就是为无标签数据而生的。实际中我们遇到的大部分数据都是无标签的,如果直接去打标签做注释、工作量将会是非常大的。