题目:用于语义分割的全卷积网络
![[译] 用于语义分割的全卷积网络FCN(UC Berkeley)_第1张图片](http://img.e-com-net.com/image/info10/ceacc7e9eb8a44a48ce7b946aa7ed899.jpg)
- 文章链接:《Fully Convolutional Networks for Semantic Segmentation》arXiv:1411.4038
(转载请注明出处:[译] 用于语义分割的全卷积网络(UC Berkeley) (zhwhong))
摘要
卷积网络在特征分层领域是非常强大的视觉模型。我们证明了经过端到端、像素到像素训练的卷积网络超过语义分割中最先进的技术。我们的核心观点是建立“全卷积”网络,输入任意尺寸,经过有效的推理和学习产生相应尺寸的输出。我们定义并指定全卷积网络的空间,解释它们在空间范围内dense prediction任务(预测每个像素所属的类别)和获取与先验模型联系的应用。我们改编当前的分类网络(AlexNet [22],the VGG net [34], and GoogLeNet [35])到完全卷积网络和通过微调[5]传递它们的学习表现到分割任务中。然后我们定义了一个跳跃式的架构,结合来自深、粗层的语义信息和来自浅、细层的表征信息来产生准确和精细的分割。我们的完全卷积网络成为了在PASCAL VOC最出色的分割方式(在2012年相对62.2%的平均IU提高了20%),NYUDv2,和SIFT Flow,对一个典型图像推理只需要花费不到0.2秒的时间。
1. 引言
卷积网络在识别领域前进势头很猛。卷积网不仅全图式的分类上有所提高[22,34,35],也在结构化输出的局部任务上取得了进步。包括在目标检测边界框 [32,12,19]、部分和关键点预测[42,26]和局部通信[26,10]的进步。
在从粗糙到精细推理的进展中下一步自然是对每一个像素进行预测。早前的方法已经将卷积网络用于语义分割[30,3,9,31,17,15,11],其中每个像素被标记为其封闭对象或区域的类别,但是有个缺点就是这项工作addresses。
![[译] 用于语义分割的全卷积网络FCN(UC Berkeley)_第2张图片](http://img.e-com-net.com/image/info10/fb8575a949c14e218406c54cf93afdd3.jpg)
我们证明了经过端到端、像素到像素训练的的卷积网络超过语义分割中没有further machinery的最先进的技术。我们认为,这是第一次训练端到端(1)的FCN在像素级别的预测,而且来自监督式预处理(2)。全卷积在现有的网络基础上从任意尺寸的输入预测密集输出。学习和推理能在全图通过密集的前馈计算和反向传播一次执行。网内上采样层能在像素级别预测和通过下采样池化学习。
这种方法非常有效,无论是渐进地还是完全地,消除了在其他方法中的并发问题。Patchwise训练是常见的 [30, 3, 9, 31, 11],但是缺少了全卷积训练的有效性。我们的方法不是利用预处理或者后期处理解决并发问题,包括超像素[9,17],proposals[17,15],或者对通过随机域事后细化或者局部分类[9,17]。我们的模型通过重新解释分类网到全卷积网络和微调它们的学习表现将最近在分类上的成功[22,34,35]移植到dense prediction。与此相反,先前的工作应用的是小规模、没有超像素预处理的卷积网。
语义分割面临在语义和位置的内在张力问题:全局信息解决的“是什么”,而局部信息解决的是“在哪里”。深层特征通过非线性的局部到全局金字塔编码了位置和语义信息。我们在4.2节(见图3)定义了一种利用集合了深、粗层的语义信息和浅、细层的表征信息的特征谱的跨层架构。
在下一节,我们回顾深层分类网、FCNs和最近一些利用卷积网解决语义分割的相关工作。接下来的章节将解释FCN设计和密集预测权衡,介绍我们的网内上采样和多层结合架构,描述我们的实验框架。最后,我们展示了最先进技术在PASCAL VOC 2011-2, NYUDv2, 和SIFT Flow上的实验结果。
2. 相关工作
我们的方法是基于最近深层网络在图像分类上的成功[22,34,35]和转移学习。转移第一次被证明在各种视觉识别任务[5,41],然后是检测,不仅在实例还有融合proposal-classification模型的语义分割[12,17,15]。我们现在重新构建和微调直接的、dense prediction语义分割的分类网。在这个框架里我们绘制FCNs的空间并将过去的或是最近的先验模型置于其中。
全卷积网络 据我们所知,第一次将卷积网扩展到任意尺寸的输入的是Matan等人[28],它将经典的LeNet[23]扩展到识别字符串的位数。因为他们的网络结构限制在一维的输入串,Matan等人利用译码器译码获得输出。Wolf和Platt[40]将卷积网输出扩展到来检测邮政地址块的四角得分的二维图。这些先前工作做的是推理和用于检测的全卷积式学习。Ning等人[30]定义了一种卷积网络用于秀丽线虫组织的粗糙的、多分类分割,基于全卷积推理。
全卷积计算也被用在现在的一些多层次的网络结构中。Sermanet等人的滑动窗口检测[32],Pinherio 和Collobert的语义分割[31],Eigen等人的图像修复[6]都做了全卷积式推理。全卷积训练很少,但是被Tompson等人[38]用来学习一种端到端的局部检测和姿态估计的空间模型非常有效,尽管他们没有解释或者分析这种方法。
此外,He等人[19]在特征提取时丢弃了分类网的无卷积部分。他们结合proposals和空间金字塔池来产生一个局部的、固定长度的特征用于分类。尽管快速且有效,但是这种混合模型不能进行端到端的学习。
基于卷积网的dense prediction 近期的一些工作已经将卷积网应用于dense prediction问题,包括Ning等人的语义分割[30],Farabet等人[9]以及Pinheiro和Collobert [31];Ciresan等人的电子显微镜边界预测[3]以及Ganin和Lempitsky[11]的通过混合卷积网和最邻近模型的处理自然场景图像;还有Eigen等人[6,7]的图像修复和深度估计。这些方法的相同点包括如下:
- 限制容量和接收域的小模型
- patchwise训练
[30,3,9,31,11] - 超像素投影的预处理,随机场正则化、滤波或局部分类
[9,3,11] - 输入移位和dense输出的隔行交错输出
[32,31,11] - 多尺度金字塔处理
[9,31,11] - 饱和双曲线正切非线性
[9,6,31] - 集成
[3,11]
然而我们的方法确实没有这种机制。但是我们研究了patchwise训练 (3.4节)和从FCNs的角度出发的“shift-and-stitch”dense输出(3.2节)。我们也讨论了网内上采样(3.3节),其中Eigen等人[7]的全连接预测是一个特例。
和这些现有的方法不同的是,我们改编和扩展了深度分类架构,使用图像分类作为监督预处理,和从全部图像的输入和ground truths(用于有监督训练的训练集的分类准确性)通过全卷积微调进行简单且高效的学习。
Hariharan等人[17]和Gupta等人[15]也改编深度分类网到语义分割,但是也在混合proposal-classifier模型中这么做了。这些方法通过采样边界框和region proposal进行微调了R-CNN系统[12],用于检测、语义分割和实例分割。这两种办法都不能进行端到端的学习。他们分别在PASCAL VOC和NYUDv2实现了最好的分割效果,所以在第5节中我们直接将我们的独立的、端到端的FCN和他们的语义分割结果进行比较。
我们通过跨层和融合特征来定义一种非线性的局部到整体的表述用来协调端到端。在现今的工作中Hariharan等人[18]也在语义分割的混合模型中使用了多层。
3. 全卷积网络
卷积网的每层数据是一个h*w*d的三维数组,其中h和w是空间维度,d是特征或通道维数。第一层是像素尺寸为h*w、颜色通道数为d的图像。高层中的locations和图像中它们连通的locations相对应,被称为接收域。
卷积网是以平移不变形作为基础的。其基本组成部分(卷积,池化和激励函数)作用在局部输入域,只依赖相对空间坐标。在特定层记X_ij为在坐标(i,j)的数据向量,在following layer有Y_ij,Y_ij的计算公式如下:

其中k为卷积核尺寸,s是步长或下采样因素,f_ks决定了层的类型:一个卷积的矩阵乘或者是平均池化,用于最大池的最大空间值或者是一个激励函数的一个非线性elementwise,亦或是层的其他种类等等。
当卷积核尺寸和步长遵从转换规则,这个函数形式被表述为如下形式:
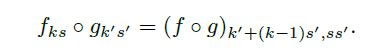
当一个普通深度的网络计算一个普通的非线性函数,一个网络只有这种形式的层计算非线性滤波,我们称之为深度滤波或全卷积网络。FCN理应可以计算任意尺寸的输入并产生相应(或许重采样)空间维度的输出。
一个实值损失函数有FCN定义了task。如果损失函数是一个最后一层的空间维度总和,
,它的梯度将是它的每层空间组成梯度总和。所以在全部图像上的基于l的随机梯度下降计算将和基于l'的梯度下降结果一样,将最后一层的所有接收域作为minibatch(分批处理)。
在这些接收域重叠很大的情况下,前反馈计算和反向传播计算整图的叠层都比独立的patch-by-patch有效的多。
我们接下来将解释怎么将分类网络转换到能产生粗输出图的全卷积网络。对于像素级预测,我们需要连接这些粗略的输出结果到像素。3.2节描述了一种技巧,快速扫描[13]因此被引入。我们通过将它解释为一个等价网络修正而获得了关于这个技巧的一些领悟。作为一个高效的替换,我们引入了去卷积层用于上采样见3.3节。在3.4节,我们考虑通过patchwise取样训练,便在4.3节证明我们的全图式训练更快且同样有效。
3.1 改编分类用于dense prediction
典型的识别网络,包括LeNet [23], AlexNet[22], 和一些后继者[34, 35],表面上采用的是固定尺寸的输入产生了非空间的输出。这些网络的全连接层有确定的位数并丢弃空间坐标。然而,这些全连接层也被看做是覆盖全部输入域的核卷积。需要将它们加入到可以采用任何尺寸输入并输出分类图的全卷积网络中。这种转换如图2所示。
![[译] 用于语义分割的全卷积网络FCN(UC Berkeley)_第3张图片](http://img.e-com-net.com/image/info10/ab92474420c8454e8cdbc338a8040216.jpg)
此外,当作为结果的图在特殊的输入patches上等同于原始网络的估计,计算是高度摊销的在那些patches的重叠域上。例如,当AlexNet花费了1.2ms(在标准的GPU上)推算一个227*227图像的分类得分,全卷积网络花费22ms从一张500*500的图像上产生一个10*10的输出网格,比朴素法快了5倍多。
这些卷积化模式的空间输出图可以作为一个很自然的选择对于dense问题,比如语义分割。每个输出单元ground truth可用,正推法和逆推法都是直截了当的,都利用了卷积的固有的计算效率(和可极大优化性)。对于AlexNet例子相应的逆推法的时间为单张图像时间2.4ms,全卷积的10*10输出图为37ms,结果是相对于顺推法速度加快了。
当我们将分类网络重新解释为任意输出尺寸的全卷积域输出图,输出维数也通过下采样显著的减少了。分类网络下采样使filter保持小规模同时计算要求合理。这使全卷积式网络的输出结果变得粗糙,通过输入尺寸因为一个和输出单元的接收域的像素步长等同的因素来降低它。
3.2 Shift-and stitch是滤波稀疏
dense prediction能从粗糙输出中通过从输入的平移版本中将输出拼接起来获得。如果输出是因为一个因子f降低采样,平移输入的x像素到左边,y像素到下面,一旦对于每个(x,y)满足0<=x,y<=f.处理f^2个输入,并将输出交错以便预测和它们接收域的中心像素一致。
尽管单纯地执行这种转换增加了f^2的这个因素的代价,有一个非常有名的技巧用来高效的产生完全相同的结果[13,32],这个在小波领域被称为多孔算法[27]。考虑一个层(卷积或者池化)中的输入步长s,和后面的滤波权重为f_ij的卷积层(忽略不相关的特征维数)。设置更低层的输入步长到l上采样它的输出影响因子为s。然而,将原始的滤波和上采样的输出卷积并没有产生和shift-and-stitch相同的结果,因为原始的滤波只看得到(已经上采样)输入的简化的部分。为了重现这种技巧,通过扩大来稀疏滤波,如下:
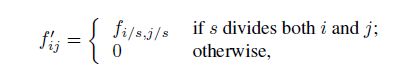
如果s能除以i和j,除非i和j都是0。重现该技巧的全网输出需要重复一层一层放大这个filter知道所有的下采样被移除。(在练习中,处理上采样输入的下采样版本可能会更高效。)
在网内减少二次采样是一种折衷的做法:filter能看到更细节的信息,但是接受域更小而且需要花费很长时间计算。Shift-and -stitch技巧是另外一种折衷做法:输出更加密集且没有减小filter的接受域范围,但是相对于原始的设计filter不能感受更精细的信息。
尽管我们已经利用这个技巧做了初步的实验,但是我们没有在我们的模型中使用它。正如在下一节中描述的,我们发现从上采样中学习更有效和高效,特别是接下来要描述的结合了跨层融合。
3.3 上采样是向后向卷积
另一种连接粗糙输出到dense像素的方法就是插值法。比如,简单的双线性插值计算每个输出y_ij来自只依赖输入和输出单元的相对位置的线性图最近的四个输入。
从某种意义上,伴随因子f的上采样是对步长为1/f的分数式输入的卷积操作。只要f是整数,一种自然的方法进行上采样就是向后卷积(有时称为去卷积)伴随输出步长为f。这样的操作实现是不重要的,因为它只是简单的调换了卷积的顺推法和逆推法。所以上采样在网内通过计算像素级别的损失的反向传播用于端到端的学习。
需要注意的是去卷积滤波在这种层面上不需要被固定不变(比如双线性上采样)但是可以被学习。一堆反褶积层和激励函数甚至能学习一种非线性上采样。
在我们的实验中,我们发现在网内的上采样对于学习dense prediction是快速且有效的。我们最好的分割架构利用了这些层来学习上采样用以微调预测,见4.2节。
3.4 patchwise训练是一种损失采样
在随机优化中,梯度计算是由训练分布支配的。patchwise 训练和全卷积训练能被用来产生任意分布,尽管他们相对的计算效率依赖于重叠域和minibatch的大小。在每一个由所有的单元接受域组成的批次在图像的损失之下(或图像的集合)整张图像的全卷积训练等同于patchwise训练。当这种方式比patches的均匀取样更加高效的同时,它减少了可能的批次数量。然而在一张图片中随机选择patches可能更容易被重新找到。限制基于它的空间位置随机取样子集产生的损失(或者可以说应用输入和输出之间的DropConnect mask[39])排除来自梯度计算的patches。
如果保存下来的patches依然有重要的重叠,全卷积计算依然将加速训练。如果梯度在多重逆推法中被积累,batches能包含几张图的patches。
patcheswise训练中的采样能纠正分类失调[30,9,3]和减轻密集空间相关性的影响[31,17]。在全卷积训练中,分类平衡也能通过给损失赋权重实现,对损失采样能被用来标识空间相关。
我们研究了4.3节中的伴有采样的训练,没有发现对于dense prediction它有更快或是更好的收敛效果。全图式训练是有效且高效的。
4 分割架构
我们将ILSVRC分类应用到FCNs增大它们用于dense prediction结合网内上采样和像素级损失。我们通过微调为分割进行训练。接下来我们增加了跨层来融合粗的、语义的和局部的表征信息。这种跨层式架构能学习端到端来改善输出的语义和空间预测。
为此,我们训练和在PASCAL VOC 2011分割挑战赛[8]中验证。我们训练逐像素的多项式逻辑损失和验证标准度量的在集合中平均像素交集还有基于所有分类上的平均接收,包括背景。这个训练忽略了那些在groud truth中被遮盖的像素(模糊不清或者很难辨认)。
![[译] 用于语义分割的全卷积网络FCN(UC Berkeley)_第4张图片](http://img.e-com-net.com/image/info10/1602d9b9e9d9416682292f384a0ae246.jpg)
注:不是每个可能的patch被包含在这种方法中,因为最后一层单位的的接收域依赖一个固定的、步长大的网格。然而,对该图像进行向左或向下随机平移接近该步长个单位,从所有可能的patches 中随机选取或许可以修复这个问题。
【原文图】
![[译] 用于语义分割的全卷积网络FCN(UC Berkeley)_第5张图片](http://img.e-com-net.com/image/info10/bf4524d9a3584a2eb6bd06b937234f8a.jpg)
4.1 从分类到dense FCN
我们在第3节中以卷积证明分类架构的。我们认为拿下了ILSVRC12的AlexNet3架构[22]和VGG nets[34]、GoogLeNet4[35]一样在ILSVRC14上表现的格外好。我们选择VGG 16层的网络5,发现它和19层的网络在这个任务(分类)上相当。对于GoogLeNet,我们仅仅使用的最后的损失层,通过丢弃了最后的平均池化层提高了表现能力。我们通过丢弃最后的分类切去每层网络头,然后将全连接层转化成卷积层。我们附加了一个1*1的、通道维数为21的卷积来预测每个PASCAL分类(包括背景)的得分在每个粗糙的输出位置,后面紧跟一个去卷积层用来双线性上采样粗糙输出到像素密集输出如3.3.节中描述。表1将初步验证结果和每层的基础特性比较。我们发现最好的结果在以一个固定的学习速率得到(最少175个epochs)。
从分类到分割的微调对每层网络有一个合理的预测。甚至最坏的模型也能达到大约75%的良好表现。内设分割的VGG网络(FCN-VGG16)已经在val上平均IU 达到了56.0取得了最好的成绩,相比于52.6[17]。在额外数据上的训练将FCN-VGG16提高到59.4,将FCN-AlexNet提高到48.0。尽管相同的分类准确率,我们的用GoogLeNet并不能和VGG16的分割结果相比较。
![[译] 用于语义分割的全卷积网络FCN(UC Berkeley)_第6张图片](http://img.e-com-net.com/image/info10/e27faba2a99940f9a4be0975b8977ef5.jpg)
4.2 结合“是什么”和“在哪里”
我们定义了一个新的全卷积网用于结合了特征层级的分割并提高了输出的空间精度,见图3。
当全卷积分类能被微调用于分割如4.1节所示,甚至在标准度量上得分更高,它们的输出不是很粗糙(见图4)。最后预测层的32像素步长限制了上采样输入的细节的尺寸。
我们提出增加结合了最后预测层和有更细小步长的更低层的跨层信息[1],将一个线划拓扑结构转变成DAG(有向无环图),并且边界将从更底层向前跳跃到更高(图3)。因为它们只能获取更少的像素点,更精细的尺寸预测应该需要更少的层,所以从更浅的网中将它们输出是有道理的。结合了精细层和粗糙层让模型能做出遵从全局结构的局部预测。与Koenderick 和an Doorn [21]的jet类似,我们把这种非线性特征层称之为deep jet。
我们首先将输出步长分为一半,通过一个16像素步长层预测。我们增加了一个1*1的卷积层在pool4的顶部来产生附加的类别预测。我们将输出和预测融合在conv7(fc7的卷积化)的顶部以步长32计算,通过增加一个2×的上采样层和预测求和(见图3)。我们初始化这个2×上采样到双线性插值,但是允许参数能被学习,如3.3节所描述、最后,步长为16的预测被上采样回图像,我们把这种网结构称为FCN-16s。FCN-16s用来学习端到端,能被最后的参数初始化。这种新的、在pool4上生效的参数是初始化为0 的,所以这种网结构是以未变性的预测开始的。这种学习速率是以100倍的下降的。
学习这种跨层网络能在3.0平均IU的有效集合上提高到62.4。图4展示了在精细结构输出上的提高。我们将这种融合学习和仅仅从pool4层上学习进行比较,结果表现糟糕,而且仅仅降低了学习速率而没有增加跨层,导致了没有提高输出质量的没有显著提高表现。
我们继续融合pool3和一个融合了pool4和conv7的2×上采样预测,建立了FCN-8s的网络结构。在平均IU上我们获得了一个较小的附加提升到62.7,然后发现了一个在平滑度和输出细节上的轻微提高。这时我们的融合提高已经得到了一个衰减回馈,既在强调了大规模正确的IU度量的层面上,也在提升显著度上得到反映,如图4所示,所以即使是更低层我们也不需要继续融合。
![[译] 用于语义分割的全卷积网络FCN(UC Berkeley)_第7张图片](http://img.e-com-net.com/image/info10/310e07767c014680bf517625f8ca1a68.jpg)
其他方式精炼化 减少池层的步长是最直接的一种得到精细预测的方法。然而这么做对我们的基于VGG16的网络带来问题。设置pool5的步长到1,要求我们的卷积fc6核大小为14*14来维持它的接收域大小。另外它们的计算代价,通过如此大的滤波器学习非常困难。我们尝试用更小的滤波器重建pool5之上的层,但是并没有得到有可比性的结果;一个可能的解释是ILSVRC在更上层的初始化时非常重要的。
另一种获得精细预测的方法就是利用3.2节中描述的shift-and-stitch技巧。在有限的实验中,我们发现从这种方法的提升速率比融合层的方法花费的代价更高。
4.3 实验框架
优化 我们利用momentum训练了GSD。我们利用了一个minibatch大小的20张图片,然后固定学习速率为10-3,10-4,和5-5用于FCN-AlexNet, FCN-VGG16,和FCN-GoogLeNet,通过各自的线性搜索选择。我们利用了0.9的momentum,权值衰减在5-4或是2-4,而且对于偏差的学习速率加倍了,尽管我们发现训练对单独的学习速率敏感。我们零初始化类的得分层,随机初始化既不能产生更好的表现也没有更快的收敛。Dropout被包含在用于原始分类的网络中。
微调 我们通过反向传播微调整个网络的所有层。经过表2的比较,微调单独的输出分类表现只有全微调的70%。考虑到学习基础分类网络所需的时间,从scratch中训练不是可行的。(注意VGG网络的训练是阶段性的,当我们从全16层初始化后)。对于粗糙的FCN-32s,在单GPU上,微调要花费三天的时间,而且大约每隔一天就要更新到FCN-16s和FCN-8s版本。
更多的训练数据 PASCAL VOC 2011分割训练设置1112张图片的标签。Hariharan等人[16]为一个更大的8498的PASCAL训练图片集合收集标签,被用于训练先前的先进系统,SDS[17]。训练数据将FCV-VGG16得分提高了3.4个百分点到59.4。
patch取样 正如3.4节中解释的,我们的全图有效地训练每张图片batches到常规的、大的、重叠的patches网格。相反的,先前工作随机样本patches在一整个数据集[30,3,9,31,11],可能导致更高的方差batches,可能加速收敛[24]。我们通过空间采样之前方式描述的损失研究这种折中,以1-p的概率做出独立选择来忽略每个最后层单元。为了避免改变有效的批次尺寸,我们同时以因子1/p增加每批次图像的数量。注意的是因为卷积的效率,在足够大的p值下,这种拒绝采样的形式依旧比patchwose训练要快(比如,根据3.1节的数量,最起码p>0.2)图5展示了这种收敛的采样的效果。我们发现采样在收敛速率上没有很显著的效果相对于全图式训练,但是由于每个每个批次都需要大量的图像,很明显的需要花费更多的时间。
分类平衡 全卷积训练能通过按权重或对损失采样平衡类别。尽管我们的标签有轻微的不平衡(大约3/4是背景),我们发现类别平衡不是必要的。
dense prediction 分数是通过网内的去卷积层上采样到输出维度。最后层去卷积滤波被固定为双线性插值,当中间采样层是被初始化为双线性上采样,然后学习。
扩大 我们尝试通过随机反射扩大训练数据,"jettering"图像通过将它们在每个方向上转化成32像素(最粗糙预测的尺寸)。这并没有明显的改善。
实现 所有的模型都是在单NVIDIA Tesla K40c上用Caffe[20]训练和学习。我们的模型和代码都是公开可用的,网址为http://fcn.berkeleyvision.org。
![[译] 用于语义分割的全卷积网络FCN(UC Berkeley)_第8张图片](http://img.e-com-net.com/image/info10/de196a5b84eb48048d6ea3954fc3a1a7.jpg)
![[译] 用于语义分割的全卷积网络FCN(UC Berkeley)_第9张图片](http://img.e-com-net.com/image/info10/c35e7762a3d04428ae7d1c3d445409f3.jpg)
5 结果
我们训练FCN在语义分割和场景解析,研究了PASCAL VOC, NYUDv2和 SIFT Flow。尽管这些任务在以前主要是用在物体和区域上,我们都一律将它们视为像素预测。我们在这些数据集中都进行测试用来评估我们的FCN跨层式架构,然后对于NYUDv2将它扩展成一个多模型的输出,对于SIFT Flow则扩展成多任务的语义和集合标签。
度量 我们从常见的语义分割和场景解析评估中提出四种度量,它们在像素准确率和在联合的区域交叉上是不同的。令n_ij为类别i的被预测为类别j的像素数量,有n_ij个不同的类别,令
为类别i的像素总的数量。我们将计算:
![[译] 用于语义分割的全卷积网络FCN(UC Berkeley)_第10张图片](http://img.e-com-net.com/image/info10/03b2355118754c63ad79c8e61cc40460.jpg)
PASCAL VOC 表3给出了我们的FCN-8s的在PASCAL VOC2011和2012测试集上的表现,然后将它和之前的先进方法SDS[17]和著名的R-CNN[12]进行比较。我们在平均IU上取得了最好的结果相对提升了20%。推理时间被降低了114×(只有卷积网,没有proposals和微调)或者286×(全部都有)。
![[译] 用于语义分割的全卷积网络FCN(UC Berkeley)_第11张图片](http://img.e-com-net.com/image/info10/f4cc97ffd4fd460dadbcd746b46acefe.jpg)
NVUDv2[33] 是一种通过利用Microsoft Kinect收集到的RGB-D数据集,含有已经被合并进Gupt等人[14]的40类别的语义分割任务的pixelwise标签。我们报告结果基于标准分离的795张图片和654张测试图片。(注意:所有的模型选择将展示在PASCAL 2011 val上)。表4给出了我们模型在一些变化上的表现。首先我们在RGB图片上训练我们的未经修改的粗糙模型(FCN-32s)。为了添加深度信息,我们训练模型升级到能采用4通道RGB-Ds的输入(早期融合)。这提供了一点便利,也许是由于模型一直要传播有意义的梯度的困难。紧随Gupta等人[15]的成功,我们尝试3维的HHA编码深度,只在这个信息上(即深度)训练网络,和RGB与HHA的“后期融合”一样来自这两个网络中的预测将在最后一层进行总结,结果的双流网络将进行端到端的学习。最后我们将这种后期融合网络升级到16步长的版本。
![[译] 用于语义分割的全卷积网络FCN(UC Berkeley)_第12张图片](http://img.e-com-net.com/image/info10/7b125359cd324e22ae08c183a9ae0ce3.jpg)
SIFT Flow 是一个带有33语义范畴(“桥”、“山”、“太阳”)的像素标签的2688张图片的数据集和3个几何分类(“水平”、“垂直”和“sky")一样。一个FCN能自然学习共同代表权,即能同时预测标签的两种类别。我们学习FCN-16s的一种双向版本结合语义和几何预测层和损失。这种学习模型在这两种任务上作为独立的训练模型表现很好,同时它的学习和推理基本上和每个独立的模型一样快。表5的结果显示,计算在标准分离的2488张训练图片和200张测试图片上计算,在这两个任务上都表现的极好。
![[译] 用于语义分割的全卷积网络FCN(UC Berkeley)_第13张图片](http://img.e-com-net.com/image/info10/1fe3df93c1c94ef6926f3a6353868115.jpg)
6 结论
全卷积网络是模型非常重要的部分,是现代化分类网络中一个特殊的例子。认识到这个,将这些分类网络扩展到分割并通过多分辨率的层结合显著提高先进的技术,同时简化和加速学习和推理。
鸣谢 这项工作有以下部分支持DARPA's MSEE和SMISC项目,NSF awards IIS-1427425, IIS-1212798, IIS-1116411, 还有NSF GRFP,Toyota, 还有 Berkeley Vision和Learning Center。我们非常感谢NVIDIA捐赠的GPU。我们感谢Bharath Hariharan 和Saurabh Gupta的建议和数据集工具;我们感谢Sergio Guadarrama 重构了Caffe里的GoogLeNet;我们感谢Jitendra Malik的有帮助性评论;感谢Wei Liu指出了我们SIFT Flow平均IU计算上的一个问题和频率权重平均IU公式的错误。
附录A IU上界
在这篇论文中,我们已经在平均IU分割度量上取到了很好的效果,即使是粗糙的语义预测。为了更好的理解这种度量还有关于这种方法的限制,我们在计算不同的规模上预测的表现的大致上界。我们通过下采样ground truth图像,然后再次对它们进行上采样,来模拟可以获得最好的结果,其伴随着特定的下采样因子。下表给出了不同下采样因子在PASCAL2011 val的一个子集上的平均IU。
pixel-perfect预测很显然在取得最最好效果上不是必须的,而且,相反的,平均IU不是一个好的精细准确度的测量标准。
附录B 更多的结果
我们将我们的FCN用于语义分割进行了更进一步的评估。
PASCAL-Context[29]提供了PASCAL VOC 2011的全部场景注释。有超过400中不同的类别,我们遵循了[29]定义的被引用最频繁的59种类任务。我们分别训练和评估了训练集和val集。在表6中,我们将联合对象和Convolutional
Feature Masking[4]的stuff variation进行比较,后者是之前这项任务中最好的方法。FCN-8s在平均IU上得分为37.8,相对提高了20%。
![[译] 用于语义分割的全卷积网络FCN(UC Berkeley)_第14张图片](http://img.e-com-net.com/image/info10/06d9d28188204f21a6e33fcdf702a337.jpg)
变更记录
论文的arXiv版本保持着最新的修正和其他的相关材料,接下来给出一份简短的变更历史。
v2 添加了附录A和附录B。修正了PASCAL的有效数量(之前一些val图像被包含在训练中),SIFT Flow平均IU(用的不是很规范的度量),还有频率权重平均IU公式的一个错误。添加了模型和更新时间数字来反映改进的实现的链接(公开可用的)。
参考文献
[1] C. M. Bishop. Pattern recognition and machine learning,page 229. Springer-Verlag New York, 2006. 6
[2] J. Carreira, R. Caseiro, J. Batista, and C. Sminchisescu. Semantic segmentation with second-order pooling. In ECCV,2012. 9
[3] D. C. Ciresan, A. Giusti, L. M. Gambardella, and J. Schmidhuber.Deep neural networks segment neuronal membranes in electron microscopy images. In NIPS, pages 2852–2860,2012. 1, 2, 4, 7
[4] J. Dai, K. He, and J. Sun. Convolutional feature masking for joint object and stuff segmentation. arXiv preprint arXiv:1412.1283, 2014. 9
[5] J. Donahue, Y. Jia, O. Vinyals, J. Hoffman, N. Zhang,E. Tzeng, and T. Darrell. DeCAF: A deep convolutional activation feature for generic visual recognition. In ICML, 2014.1, 2
[6] D. Eigen, D. Krishnan, and R. Fergus. Restoring an image taken through a window covered with dirt or rain. In Computer Vision (ICCV), 2013 IEEE International Conference on, pages 633–640. IEEE, 2013. 2
[7] D. Eigen, C. Puhrsch, and R. Fergus. Depth map prediction from a single image using a multi-scale deep network. arXiv preprint arXiv:1406.2283, 2014. 2
[8] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The PASCAL Visual Object Classes Challenge 2011 (VOC2011) Results. http://www.pascalnetwork.org/challenges/VOC/voc2011/workshop/index.html.4
[9] C. Farabet, C. Couprie, L. Najman, and Y. LeCun. Learning hierarchical features for scene labeling. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2013. 1, 2, 4,7, 8
[10] P. Fischer, A. Dosovitskiy, and T. Brox. Descriptor matching with convolutional neural networks: a comparison to SIFT.CoRR, abs/1405.5769, 2014. 1
[11] Y. Ganin and V. Lempitsky. N4-fields: Neural network nearest neighbor fields for image transforms. In ACCV, 2014. 1,2, 7
[12] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Computer Vision and Pattern Recognition,2014. 1, 2, 7
[13] A. Giusti, D. C. Cires¸an, J. Masci, L. M. Gambardella, and J. Schmidhuber. Fast image scanning with deep max-pooling convolutional neural networks. In ICIP, 2013. 3, 4
[14] S. Gupta, P. Arbelaez, and J. Malik. Perceptual organization and recognition of indoor scenes from RGB-D images. In CVPR, 2013. 8
[15] S. Gupta, R. Girshick, P. Arbelaez, and J. Malik. Learning rich features from RGB-D images for object detection and segmentation. In ECCV. Springer, 2014. 1, 2, 8
[16] B. Hariharan, P. Arbelaez, L. Bourdev, S. Maji, and J. Malik.Semantic contours from inverse detectors. In International Conference on Computer Vision (ICCV), 2011. 7
[17] B. Hariharan, P. Arbel´aez, R. Girshick, and J. Malik. Simultaneous detection and segmentation. In European Conference on Computer Vision (ECCV), 2014. 1, 2, 4, 5, 7, 8
[18] B. Hariharan, P. Arbel´aez, R. Girshick, and J. Malik. Hypercolumns for object segmentation and fine-grained localization.In Computer Vision and Pattern Recognition, 2015.2
[19] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, 2014. 1, 2
[20] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick,S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. arXiv preprint
arXiv:1408.5093, 2014. 7
[21] J. J. Koenderink and A. J. van Doorn. Representation of local geometry in the visual system. Biological cybernetics,55(6):367–375, 1987. 6
[22] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012. 1, 2, 3, 5
[23] Y. LeCun, B. Boser, J. Denker, D. Henderson, R. E. Howard,W. Hubbard, and L. D. Jackel. Backpropagation applied to hand-written zip code recognition. In Neural Computation,1989. 2, 3
[24] Y. A. LeCun, L. Bottou, G. B. Orr, and K.-R. M¨uller. Efficient backprop. In Neural networks: Tricks of the trade,pages 9–48. Springer, 1998. 7
[25] C. Liu, J. Yuen, and A. Torralba. Sift flow: Dense correspondence across scenes and its applications. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 33(5):978–994, 2011.8
[26] J. Long, N. Zhang, and T. Darrell. Do convnets learn correspondence?In NIPS, 2014. 1
[27] S. Mallat. A wavelet tour of signal processing. Academic press, 2nd edition, 1999. 4
[28] O. Matan, C. J. Burges, Y. LeCun, and J. S. Denker. Multidigit recognition using a space displacement neural network.In NIPS, pages 488–495. Citeseer, 1991. 2
[29] R. Mottaghi, X. Chen, X. Liu, N.-G. Cho, S.-W. Lee, S. Fidler,R. Urtasun, and A. Yuille. The role of context for object detection and semantic segmentation in the wild. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages 891–898. IEEE, 2014. 9
[30] F. Ning, D. Delhomme, Y. LeCun, F. Piano, L. Bottou, and P. E. Barbano. Toward automatic phenotyping of developing embryos from videos. Image Processing, IEEE Transactions on, 14(9):1360–1371, 2005. 1, 2, 4, 7
[31] P. H. Pinheiro and R. Collobert. Recurrent convolutional neural networks for scene labeling. In ICML, 2014. 1, 2,4, 7, 8
[32] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. In ICLR, 2014.1, 2, 4
[33] N. Silberman, D. Hoiem, P. Kohli, and R. Fergus. Indoor segmentation and support inference from rgbd images. In ECCV, 2012. 8
[34] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR,abs/1409.1556, 2014. 1, 2, 3, 5
[35] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A.Rabinovich. Going deeper with convolutions. CoRR, abs/1409.4842,2014. 1, 2, 3, 5
[36] J. Tighe and S. Lazebnik. Superparsing: scalable nonparametric image parsing with superpixels. In ECCV, pages 352–365. Springer, 2010. 8
[37] J. Tighe and S. Lazebnik. Finding things: Image parsing with regions and per-exemplar detectors. In CVPR, 2013. 8
[38] J. Tompson, A. Jain, Y. LeCun, and C. Bregler. Joint training of a convolutional network and a graphical model for human pose estimation. CoRR, abs/1406.2984, 2014. 2
[39] L. Wan, M. Zeiler, S. Zhang, Y. L. Cun, and R. Fergus. Regularization of neural networks using dropconnect. In Proceedings of the 30th International Conference on Machine Learning (ICML-13), pages 1058–1066, 2013. 4
[40] R. Wolf and J. C. Platt. Postal address block location using a convolutional locator network. Advances in Neural Information Processing Systems, pages 745–745, 1994. 2
[41] M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. In Computer Vision–ECCV 2014,pages 818–833. Springer, 2014. 2
[42] N. Zhang, J. Donahue, R. Girshick, and T. Darrell. Partbased r-cnns for fine-grained category detection. In Computer Vision–ECCV 2014, pages 834–849. Springer, 2014.1
(注:感谢您的阅读,希望本文对您有所帮助。如果觉得不错欢迎分享转载,但请先点击 这里 获取授权。本文由 版权印 提供保护,禁止任何形式的未授权违规转载,谢谢!)