图片风格转换(附TensorFlow代码)
源论文:A NeuralAlgorithm of Artistic Style. 2015 NIPS
思路:采用ImageNet数据集预训练一个VGG19网络出来,得到网络结构如下图:

其中紫色框中的5个layer代表图像风格层,绿色框代表内容层。
· 对于输入的风格图片,通过前向传播计算出5个风格层的特征图,元素平铺然后求内积(例如28*28平铺为784*1,再求内积变成784*784),得到格拉姆矩阵(Gram matrix)。
· 对于输入的内容图片,通过前向传播计算内容层的特征图(tensor)。
训练开始之前,先通过随机的方式初始化一张合成图,然后进行迭代,每次迭代中都优化损失函数,使得合成图与5个格拉姆矩阵的差异性、与内容特征图的差异性最小。优化算法为Adam算法。具体而言,损失函数包括2部分:内容损失、风格损失。其中α和β用于控制内容与风格的权重,当内容权重为0时,得到的就是图片的纹理特征。

[内容损失]
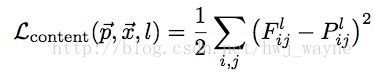

[风格损失]

单独某层损失函数:
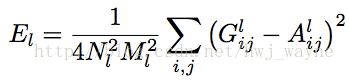
各层综合损失函数:
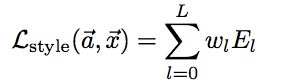
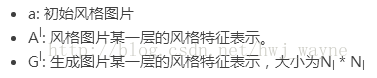
TensorFlow源码:
import numpy as np
import scipy.io
import tensorflow as tf
from PIL import Image
# 定义命令行参数
tf.app.flags.DEFINE_string('style_image', '', 'style image')
tf.app.flags.DEFINE_string('content_image','','content image')
tf.app.flags.DEFINE_integer('epochs',5000,'training epochs')
tf.app.flags.DEFINE_float('learning_rate',0.5,'learning rate')
FLAGS=tf.app.flags.FLAGS
# 声明超参数
STYLE_WEIGHT=0.5
CONTENT_WEIGHT=0.5
STYLE_LAYERS=['relu1_1','relu2_1','relu3_1','relu4_1','relu5_1']
CONTENT_LAYERS=['relu4_2']
_vgg_params=None
def vgg_params():
# 加载VGG19的权值
global _vgg_params
if _vgg_params is None:
_vgg_params=scipy.io.loadmat('imagenet-vgg-verydeep-19.mat')
return _vgg_params
def vgg19(input_image):
layers=(
'conv1_1','relu1_1','conv1_2','relu1_2','pool1',
'conv2_1','relu2_1','conv2_2','relu2_2','pool2',
'conv3_1','relu3_1','conv3_2','relu3_2','conv3_3','relu3_3','conv3_4','relu3_4','pool3',
'conv4_1','relu4_1','conv4_2','relu4_2','conv4_3','relu4_3','conv4_4','relu4_4','pool4',
'conv5_1','relu5_1','conv5_2','relu5_2','conv5_3','relu5_3','conv5_4','relu5_4','pool5'
)
weights=vgg_params()['layers'][0]
net=input_image
network={}
for i,name in enumerate(layers):
layer_type=name[:4]
if layer_type=='conv':
kernels,bias=weights[i][0][0][0][0]
# matconvert weights:[width,height,in_channels,out_channels]
# tensorflow weights:[height,width,in_channels,out_channels]
kernels=np.transpose(kernels,(1,0,2,3))
conv=tf.nn.conv2d(net,tf.constant(kernels),strides=(1,1,1,1),padding='SAME',name=name)
net=tf.nn.bias_add(conv,bias.reshape(-1))
net=tf.nn.relu(net)
elif layer_type=='pool':
net=tf.nn.max_pool(net,ksize=(1,2,2,1),strides=(1,2,2,1),padding='SAME')
network[name]=net
return network
def content_loss(target_features,content_features):
# 使用特征图之差的平方和作为内容差距,越小则合成图与原图的内容越接近
_,height,width,channel=map(lambda i:i.value,content_features.get_shape())
content_size=height*width*channel
return tf.nn.l2_loss(target_features-content_features)/content_size
def style_loss(target_features,style_features):
# 使用Gram matrix之差的平方和作为风格差距,越小则合成图像越具有风格图的纹理特征
_, height, width, channel = map(lambda i: i.value, style_features.get_shape())
size=height*width*channel
#targer gram 是特征图矩阵的内积
target_features=tf.reshape(target_features,(-1,channel))
target_gram=tf.matmul(tf.transpose(target_features),target_features)/size
style_features=tf.reshape(style_features,(-1,channel))
style_gram=tf.matmul(tf.transpose(style_features),style_features)/size
return tf.nn.l2_loss(target_gram-style_gram)/size
def loss_function(content_image,style_image,target_image):
style_features=vgg19([style_image])
content_features=vgg19([content_image])
target_features=vgg19([target_image])
loss=0.0
for layer in CONTENT_LAYERS:
loss += CONTENT_WEIGHT*content_loss(target_features[layer],content_features[layer])
for layer in STYLE_LAYERS:
loss += STYLE_WEIGHT*style_loss(target_features[layer],style_features[layer])
return loss
def stylize(style_image,content_image,learning_rate=0.1,epochs=500):
# 目标合成图,初始化为随机白噪声图
target=tf.Variable(tf.random_normal(content_image.shape),dtype=tf.float32)
style_input=tf.constant(style_image,dtype=tf.float32)
content_input=tf.constant(content_image,dtype=tf.float32)
cost=loss_function(content_input,style_input,target)
# 使用adam算法作为优化算法,最小化代价函数
train_op=tf.train.AdamOptimizer(learning_rate).minimize(cost)
with tf.Session() as sess:
tf.initialize_all_variables().run()
for i in range(epochs):
_,loss,target_image=sess.run([train_op,cost,target])
print ("iter:%d, loss:%.9f" % (i,loss))
if (i+1)%100==0:
# 每100次迭代保存一次图片
image = np.clip(target_image+128,0,255).astype(np.uint8)
Image.fromarray(image).save("neural_%d.jpg" % (i+1))
if __name__=='__main__':
# 图片在读入时,像素值被处理为0中心,可加速收敛
style=Image.open(FLAGS.style_image)
style=np.array(style).astype(np.float32)-128.0
content=Image.open(FLAGS.content_image)
content=np.array(content).astype(np.float32)-128.0
stylize(style,content,FLAGS.learning_rate,FLAGS.epochs)