自然语言处理从小白到大白系列(5)多个角度彻底理解最大熵模型
文章目录
- 1.最大熵模型初探
- 1.1 模型引入
- 1.2 特征函数
- 2.最大熵模型和逻辑回归的瓜葛
- 3.最大熵模型和条件随机场的绯闻
- 4.最大熵模型和同母异父兄弟极大似然估计
- 5.最大熵马尔科夫模型
- 5.1 隐马尔科夫模型的局限:条件独立假设
- 5.2 标注偏置问题
最大熵模型可能刚开始接触的同学都觉得这个模型还行吧,不算啥,一般般。不就是让熵最大嘛,我取个均匀分布熵不就最大了嘛。这个模型有啥好讲的,嘿,您可太小瞧它了,我学习这个模型的感觉就像是什么呢?就像是在上课,上一秒还在讲1+1=2,我弯腰一捡笔,老师一黑板公式已经黑压压的写满了。哈哈恍如隔世,废话不多说哟,最近又重新学习了一下这个模型,感觉收获不小,特来和大家分享一下。
如果你还不了解信息熵的概念,或者对熵、条件熵、交叉熵、互信息等概念不熟悉,这里有我专门为本文准备的传送门: 一文说清楚你头疼不已的熵们:信息熵、联合熵、条件熵、互信息、交叉熵、相对熵(KL散度)。
正式开始!
1.最大熵模型初探
1.1 模型引入
最大熵模型有最基本的原则:
- 承认已知事物(现有知识)
- 对未知事物不做任何假设,没有偏袒
听起来是不是很公平的样子,先来一个小例子

上面的这个应该没有疑问,我们假设x,y的分布都是均匀分布,不就是最大熵模型了吗?
而最大熵模型难就难在如何建立一个包含已有知识的无偏模型。

看到这里我们依然还是很容易理解的,除去“学习”被标记为定语这样的一个事实,我们其他的情况依然是均匀分布的,这也是符合最大熵原理的。
但是这个新知识太简单了,比如复杂一点的知识呢?

是不是就开始蒙蔽了?没关系,我们的最大熵就是用来解决这个问题的。
把已有约束(现有知识都可以看做是某种约束)都列举出来:

整理一下,可以写作:
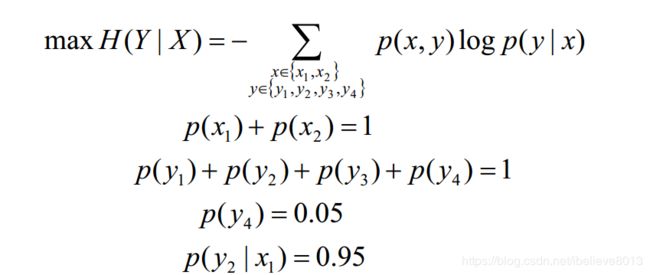
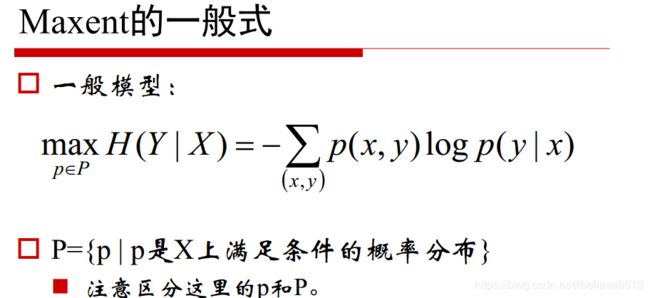
因此我们可以知道:最大熵模型就是要在给定已有知识X的情况下,求熵最大时的后验分布呀!这里冒出来个后验分布,你听了不要感觉哇不得了,又开始听不懂了,后验分布其实就是 p ( y ∣ x ) p(y|x) p(y∣x)嘛。
1.2 特征函数
特征函数这个概念很多地方见过有木有?像条件随机场里面就讲到过, 如果还不了解这个概念的话可以看看我前面的条件随机场的博客。
简而言之就是看看x,y是否符合某一条特征关系,如果符合取1,不符合取0,这个函数也没干别的事,就干这事情去了。

那么我们考虑哦,一堆样本里面,先定义好一个特征函数,那么在样本中对每一条样本(x,y),一定知道 f ( x , y ) f(x,y) f(x,y)的值对不对,然后我们有样本,是可以统计出经验分布 P ~ ( x , y ) \tilde P(x,y) P~(x,y)的,也可以统计出边缘分布 P ~ ( x ) \tilde P(x) P~(x)的。
然后最大熵模型最最最最最关键的步骤来了!
特征函数 f ( x , y ) f(x,y) f(x,y)关于经验分布 P ~ ( x , y ) \tilde P(x,y) P~(x,y)的期望是可以计算的:
E P ~ ( f ) = Σ x , y P ~ ( x , y ) f ( x , y ) E_{\tilde P}(f) = \Sigma{x,y}\tilde P(x,y) f(x,y) EP~(f)=Σx,yP~(x,y)f(x,y)
特征函数关于模型 P ( Y ∣ X ) P(Y|X) P(Y∣X)与经验分布 P ~ ( x ) \tilde P(x) P~(x)的期望表示出来:
E P ( f ) = Σ x , y P ( y ∣ x ) P ~ ( x ) f ( x , y ) E_{P}(f) = \Sigma{x,y} P(y|x)\tilde P(x) f(x,y) EP(f)=Σx,yP(y∣x)P~(x)f(x,y)
对比一下上下两个公式,简直不能再像,我们希望建立的模型尽可能表达我们的样本中的知识,当然也就是希望这两个期望能相等,这就是我们最大熵模型中的核心约束!
E P ~ ( f ) = E P ( f ) E_{\tilde P}(f) =E_{P}(f) EP~(f)=EP(f)
也就是
Σ x , y P ~ ( x , y ) f ( x , y ) = Σ x , y P ( y ∣ x ) P ~ ( x ) f ( x , y ) \Sigma{x,y}\tilde P(x,y) f(x,y) = \Sigma{x,y} P(y|x)\tilde P(x) f(x,y) Σx,yP~(x,y)f(x,y)=Σx,yP(y∣x)P~(x)f(x,y)
有了这个约束,我们又有条件熵,现在要找条件熵最大的时候的模型,不就是一个带约束的最优化问题吗?直接拉格朗日乘子法就可以解了。


对条件概率求偏导,并另其等于0,得到模型:

进一步地,归一化因子求出来:

现在模型得到了,关键就是里面的参数如何求解的问题了,即 λ \lambda λ的求解问题,这个可以用梯度下降,也可以用IIS(改进的迭代尺度法)来求解,和crf ,LR 差不多,后面会单独开一篇文章,来讨论模型的常见最优化方法。
2.最大熵模型和逻辑回归的瓜葛
我们经常听大佬说可以从最大熵模型的角度看待逻辑回归。也就是逻辑回归是一种基于最大熵模型的分类模型。这是什么意思呢?
通俗地说(一般说通俗地说的时候,就是作者自己都不会专业的表达),就是从这个角度看逻辑回归,我们是在寻找一条既满足已知知识(所有样本),又没有任何偏袒的分界面!
有数学恐惧症的看到这里就可以关闭网页,洗洗睡觉了。因为下面从公式的角度来探讨一下。
我们看看最大熵模型:
P ( y ∣ x ) = e Σ i λ i f i ( x , y ) Σ y e Σ i λ i f i ( x , y ) P(y|x)=\frac{e^{\Sigma_i\lambda_i f_i(x,y)}}{\Sigma _ye^{\Sigma_i \lambda_i f_i(x,y)}} P(y∣x)=ΣyeΣiλifi(x,y)eΣiλifi(x,y)
我们换种表达方式,入乡随俗,用LR的方式来写这个式子:
P ( y ∣ x ) = e θ T f ( x , y ) Σ y e θ T f ( x , y ) P(y|x)=\frac{e^{\theta^T f(x,y)}}{\Sigma _ye^{\theta^T f(x,y)}} P(y∣x)=ΣyeθTf(x,y)eθTf(x,y)
然后你说,这也不像LR啊,想骗我,我知道LR怎么写的:
P ( y = 1 ∣ x ) = e θ T x 1 + e θ T x P(y=1|x)=\frac{e^{\theta^T x}}{1+e^{\theta^T x}} P(y=1∣x)=1+eθTxeθTx
P ( y = 0 ∣ x ) = 1 1 + e θ T x P(y=0|x)=\frac{1}{1+e^{\theta^Tx}} P(y=0∣x)=1+eθTx1
现在我们就要从最大熵,推到LR。
我们知道对于一个二分类的LR模型来说,y有两个label: { y 0 , y 1 } \{y_0, y_1\} {y0,y1},现在对于最大熵模型,我们构造这样的一个特征函数:
- 当 y = y 1 y=y_1 y=y1时, f ( x , y ) = x f(x,y) = x f(x,y)=x,
- 当 y = y 0 y=y_0 y=y0时, f ( x , y ) = 0 f(x,y) = 0 f(x,y)=0,
啥意思呢,就是我们仅在 y = y 1 y=y_1 y=y1时提取出全x的特征,然后在 y = y 0 y=y_0 y=y0时,直接返回0向量。初看这个的时候,说实话我也是无法理解的。什么叫在 y = y 1 y=y_1 y=y1时提取出全x的特征,然后在 y = y 0 y=y_0 y=y0时返回空???难道说我们就只利用label是 y 1 y_1 y1的样本?那另一半的样本扔了?错啦!不是这样理解的。
这里的意思是对于一个待预测的样本,我们其实不知道它的label是什么,但是我们可以在计算的时候计算 P ( y = y 1 ) P(y=y_1) P(y=y1)的概率,而这个时候,特征函数提取出 x x x向量作为特征;
在计算 P ( y = y 0 ) P(y=y_0) P(y=y0)的时候,就不用提取任何特征了,因为特征在上一步已经被提取完全了;
OK,基于上面的阐述,我们可以由最大熵模型 P ( y ∣ x ) = e θ T f ( x , y ) Σ y e θ T f ( x , y ) P(y|x)=\frac{e^{\theta^T f(x,y)}}{\Sigma _ye^{\theta^T f(x,y)}} P(y∣x)=ΣyeθTf(x,y)eθTf(x,y)
推导:
- y = y 1 y=y_1 y=y1时:
P ( y = y 1 ∣ x ) = e θ T x e θ T x + e θ T 0 P(y=y_1|x)=\frac{e^{\theta^T x}}{e^{\theta^T x}+e^{\theta^T 0}} P(y=y1∣x)=eθTx+eθT0eθTx
P ( y = y 1 ∣ x ) = e θ T x e θ T x + 1 P(y=y_1|x)=\frac{e^{\theta^T x}}{e^{\theta^T x}+1} P(y=y1∣x)=eθTx+1eθTx - y = y 0 y=y_0 y=y0时:
P ( y = y 0 ∣ x ) = e θ T 0 e θ T x + e θ T 0 P(y=y_0|x)=\frac{e^{\theta^T 0}}{e^{\theta^T x}+e^{\theta^T 0}} P(y=y0∣x)=eθTx+eθT0eθT0
P ( y = y 0 ∣ x ) = 1 e θ T x + 1 P(y=y_0|x)=\frac{1}{e^{\theta^T x}+1} P(y=y0∣x)=eθTx+11
这不就完美得到了逻辑回归模型了吗?关键就在于理解那个特征函数,而那个特征函数,是最简单的一个特征函数,相当于本质就是特征 x x x。好的,我们知道,LR,CRF,MaxEnt他们的形式都好像,那crf和最大熵有没有关系呢?
3.最大熵模型和条件随机场的绯闻
没有绯闻的模型算不得名模~因为我们觉得最大熵模型和条件随机场的形式很像,而且都有个特征函数的东东,那他们之间肯定有瓜葛呀!
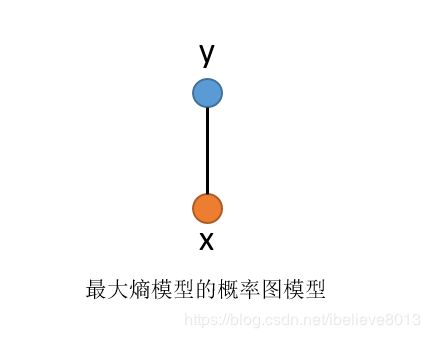
其实是这样的,最大熵模型可以从概率图的模型来解释,(这话不是我说的,因为我说的你肯定不信)。
我们可以理解为:最大熵模型p(y|x)就类似于概率图模型中,势函数为指数函数的马尔科夫网络:(出自百面机器学习p124)
而条件随机场我们太了解了:(线性链条件随机场)
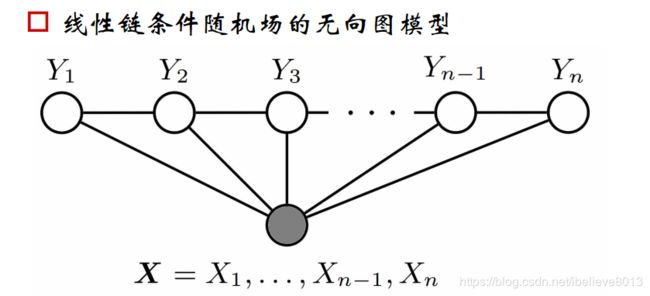
因此,我们可否理解为,crf是最大熵模型的序列模型形式?我认为是可以的。
4.最大熵模型和同母异父兄弟极大似然估计
为什么说他们是孪生兄弟呢?是有道理的,最大熵模型是信息论的角度,极大似然估计是机器学习的角度。我们看看推导:

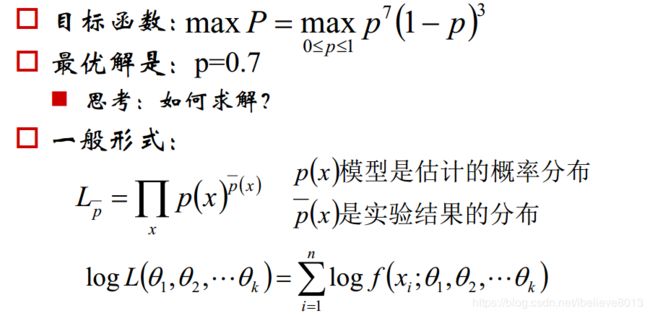

我们看看,第一项,不就是我们的条件熵吗?我们最大熵模型不就是在优化条件熵吗,这样看,他们是不是殊途同归呢?

5.最大熵马尔科夫模型
都讲到了这里了,不得不提一下最大熵马尔科夫模型了,我们先说说这个模型为什么存在,再说说它最大的问题(标注偏置问题)
5.1 隐马尔科夫模型的局限:条件独立假设
条件独立假设是隐马模型的优势,也是它的缺点,简单来讲,它假设了隐状态仅和前一个状态有关,而更重要的是,观测序列的各个状态仅仅依赖于对应的隐状态,这给计算带来了方便,却限制了模型的表达能力。
我们知道,在实际的序列标注问题中,隐状态标注不仅仅和单个观测状态有关,还和观测序列的上下文,长度等息息相关。
例如词性标注问题中, 一个词被标注为动词还是名词, 不仅与它本身以及它前一个词的标注有关, 还依赖于上下文中的其他词, 于是引出了最大熵马尔可夫模型(Maximum Entropy Markov Model,MEMM)
最大熵马尔可夫模型在建模时, 去除了隐马尔可夫模型中观测状态相互独立的假设, 考虑了整个观测序列, 因此获得了更强的表达能力。 同时, 隐马尔可夫模型是一种对隐状态序列和观测状态序列的联合概率P(x,y)进行建模的生成式模型, 而最大熵马尔可夫模型是直接对标注的后验概率P(y|x)进行建模的判别式模型。
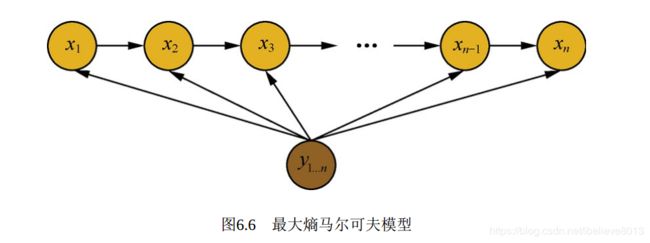
最大熵马尔可夫模型建模如下
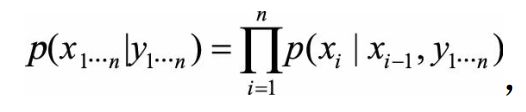
其中 P ( x i ∣ x i − 1 , y 1... n ) P(x_i|x_{i-1},y_{1...n}) P(xi∣xi−1,y1...n)会在局部进行归一化, 即枚举xi的全部取值进行求和之后计算概率, 计算公式为
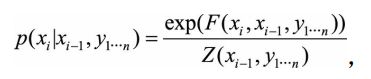
其中Z为归一化因子
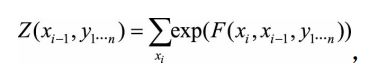
5.2 标注偏置问题
但是为什么会产生标注偏置的问题?什么叫标注偏置的问题?这里引用一下《百面机器学习》的原文:
最大熵马尔可夫模型存在标注偏置问题, 如图6.7所示。 可以发现, 状态1倾向于转移到状态2, 状态2倾向于转移到状态2本身。 但是实际计算得到的最大概率路径是1->1->1->1, 状态1并没有转移到状态2, 如图6.8所示。 这是因为, 从状态2转移出去可能的状态包括1、 2、 3、 4、 5, 概率在可能的状态上分散了, 而状态1转移出去的可能状态仅仅为状态1和2, 概率更加集中。 由于局部归一化的影响, 隐状态会倾向于转移到那些后续状态可能更少的状态上, 以提高整体的后验概率。这就是标注偏置问题。
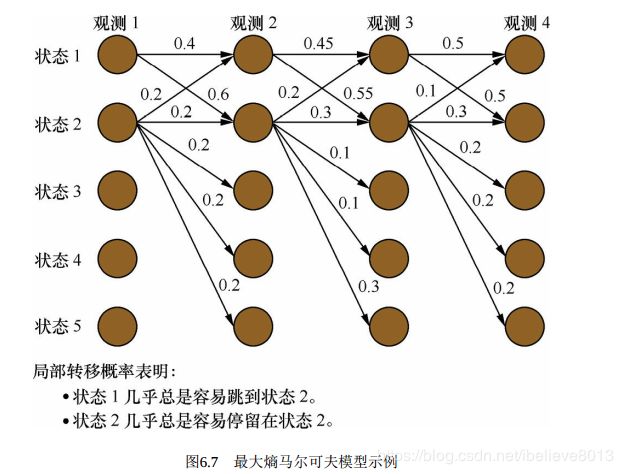
我来解读一下呢,就是说在计算最大概率路径的时候,后续状态更少的那些状态就更讨喜,因为他们每个状态的转移概率就更大呀,这当然就不公平咯。所以解决的办法是全局的归一化!就是终极的武器:CRF。
好了,差不多总结了最大熵模型,如果有不清楚的欢迎留言,我会及时更正~最后推荐大家看看李航博士的《统计学习方法第二版》,真的是深入浅出,越看越经典。
代码部分待更新~