FaceNet项目实践
一、论文的原理与复现
1. 论文复现
Database:LFW db(论文采用,rgb图算是较大的典型数据集)。
LFW数据库 总共有 13233 张 JPEG 格式图片,属于 5749 个不同人。每张图片尺寸都是 250x250;
数据库下载地址:http://vis-www.cs.umass.edu/lfw/lfw.tgz
人脸对齐:python src\align\align_dataset_mtcnn.py data/lfw data/lfw_160 --image_size 160 --margin 32 --random_order --gpu_memory_fraction 0.25
2. 三分triplet类聚类方法
不使用二分聚类判别,而使用三分聚类判别。
(一).直接学习图像到欧式空间的映射,其中两张图像所对应的特征的欧式空间的点,最后一层都进行特征归一化。
||f(x)|| = 1
归一化后的欧式距离对应这连个图像的相似度
(二). 用三元组进行knn聚类,称为triplet
a. 原理:三张图对应于两个身份: (a,b,c)=(A,A,B)
b. 保证 |ab| < (|ac|+|bc|)/2
c. triplet loss:三张图片输入的loss(之前都是double / single loss)
d. loss的计算过程
3. 样本的选择方法
假设有10000张样本,如果是遍历所有的pair,共10000×10000种情况,数量过于庞大,处理这种情况,考虑两种采用minibatch的方法:
|=======方案一
- 随机设置6000组embeddings(这个是自己做facenet时用的方法,事先生成随机pairs)
|=======方案二
- 假设每个人有20张图片,首先挑出一张图片作为a;
- 剩下的19张里选择一张hard positive,就是跟他最不相似的图片b;
- 同时在包括其他类的所有照片里,选择一张hard——negative,就是和这张图片最像的照片c。进行训练。
.
4. triplet方式的缺陷
新问题:为什么容易进入局部最优?
- 猜测:由于hard-positive和hard-negative都是选自和a同一类的照片,结果就变成了类间分类,Positive Pair的样本对训练没有积极作用。
解决方案:
- semi-hard网络结构,在选择hard-negative的时候,要求满足:
|positive——pair的平方和| < |negative——pair的平方和-threshold|
保证了hard-negative不跟自己太像,不至于每次都选到自己同类的照片)
怀疑:
- semi-hard是数学上的方法,但是边界阈值的设置需要靠经验吗?
- 另外限定hard-negtive样本的选择范围于与a不同类的样本范围内,可以改善局部最优吗?
辩驳:
- 训练后期,学习率调低,如果训练进入局部最优,在与a不同类的样本里找hard-negative(也就是c),如果c和a的相似度高(欧式距离较小),同时b和a欧式距离也很小(虽然b是同一类里和a最不像的样本,但在bp传播优化过程中,b和a的距离也保持在很小的水平),那么bp的反向传播对网络的改善就大打折扣,难以逃出局部最优。
- 优化:在与a不同类的样本里,结合semi-hard方法,更合适于逃离局部最优。(未实践)
5. 评价函数
- 评价一:
所有6000对pairs的二分结果正确率 - 评价二:
ROC,Facenet输出了【TP】和【TN】指标。
把一对含有同一个人的两张照片pair称为Positive Pair。
把一对来自两个人的两张照片pair称为Negative Pair。
TP: 把Positive Pair正确判定为Positive Pair;
TN: 把Negative Pair正确判定为Negative Pair;
FP: 把Negative Pair正确判定为PositivePair;
FN: 把Positive Pair正确判定为Negative Pair;
6. 复现主要思路记录:
前期进行常见的crop((w,h)=(160,160))预处理,没有进行flip、randomskip或rotate,主要是考虑先跑通了再考虑是否有必要通过映射变换增加样本数量。
LFW复现结果:
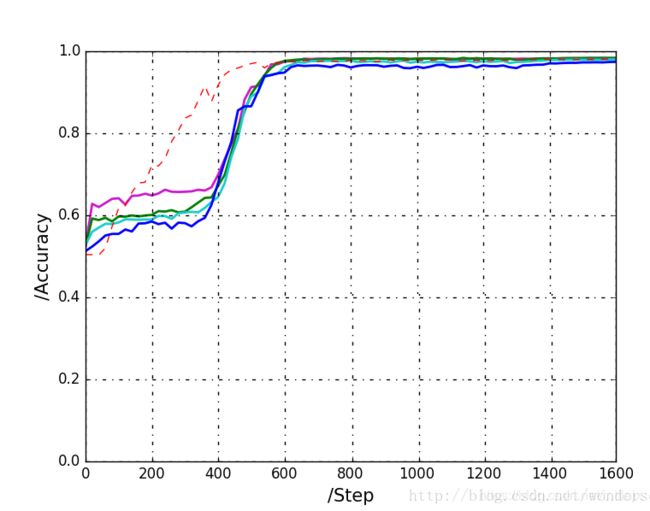
以LFW为训练集、以LFW为测试集。loss收敛相当快,训练速度和作者说的差不多。作者硬件1070ti,我的是1080ti,迭代15000次,准确率到0.98,一个多小时(一个epoch取1000次batch。每个batch耗时0.2到0.3秒左右,耗时最长的环节,就是在评价编码器环节:每个epoch后,对LFW随机生成的6000对pair进行一一检验,以triplet方式衡量编码器的好坏,这部分平均耗时10秒以上)
对网络的小改进:
pair.txt虽然是事先随机的抽取,不过所有pair被固化了,可能无法代表部分判别项。于是,我把pair.txt文件删了,写了新脚本,保证每次pair都是随机生成的10000对,same和notsame维持在1比2的比例附近。随机的pair的生成,虽然增加了图像IO队列的流动成本,但是事实证实了网络收敛地更快。仅迭代1200次,evaluate的结果就达到了0.98。
插曲:
调试时疑惑不解scipy读取的图像数据,plt.show和cv2.imshow,结果不同。scipy.misc.imread按照RGB格式,opencv按照BGR格式读取。可以说是很逗了。
7.拓展:对其他数据集的复现
Yale_B(单通道,pgm格式,考虑了多种光照效果,参杂bad样本,其他说明略)数据库,相对于LFW,它的单类样本数更多,分类数较少。以Yale_B为例,观察facenet对中小型人脸数据库的检测精度。同时,通过学姐的帮助,对各数据集进行有效的降维,加快训练效率。
插曲:
facenet为了节省样本读取的时间,采用pipline方式从图片路径IO输入输出的方式。tf这种方式对png/jpg是支持的,对pgm不支持,考虑到重写输入输出结构需要改动大量代码,所以采用了更简单的办法:写个脚本pgm转jpg搞定。其他修改的细枝末节不赘述。
输出最终结果:
多次测试,同样迭代千次级别,二分准确率达到0.98。在中小型数据上,facenet也表现出强劲的二分检测能力。涉及师姐的成果,所以图片抹掉了部分重要信息。
python src\validate_on_lfw.py ../data/lfw_160 models/20180408-102900
----------------------------------------------------------------------------------------------
二. 用来做计算人脸之间的相似度
.准备工作:
2-1.下载FaceNet官方代码
下载地址:https://github.com/davidsandberg/facenet.git
2-2.下载训练好的FaceNet模型文件
下载地址:https://github.com/davidsandberg/facenet

解压,并将其模型存放在和compare.py代码相同的路径下。
2-3.下载两张待测试的图片。(图片大小无要求,格式为jpg/png)
同样,将图片存放在和compare.py代码相同的路径下。
2-4.运行compare.py代码
1)cd到compare.Py所在路径
2)分别输入:python compare.py 20170511-185253 001.jpg 002.jpg
python compare.py 20170511-185253 001.jpg 003.jpg(注意图片格式)
3) 完成