谷歌人工智能深度解剖:从HAL的太空漫游到AlphaGo,AI的春天来了
谷歌人工智能深度解剖:从HAL的太空漫游到AlphaGo,AI的春天来了
人工智能驱动的年代到了—谷歌以AI为本,融入生活,化不可能为可能
早在1968年斯坦利库布里克作品《2001:太空漫游》里的HAL9000,到1977年《星球大战》里的R2-D2,到2001年《AI》里的David,到最近《星战:原力觉醒》的BB-8,数之不尽的电影机器人,有赖好莱坞梦想家前瞻性的创作将我们与人工智能的距离拉近。
从AlphaGo跟李世石围棋博弈技惊四座,到各款智能产品,包括Google Home、谷歌助理和云计算硬件等,谷歌正式确立了以人工智能优先的公司战略。AI业务涵盖了从硬件到软件、搜索算法、翻译、语音和图像识别、无人车技术以及医疗药品研究等方面。这些业务充分展示了谷歌不断在人工智能(Artificial Intelligence)里的机器学习(Machine Learning)以及自然语言处理(Natural Language Processing, NLP)上的精益求精。作为全球科技巨头,谷歌积累超过10年的经验,并不断在学术界招揽最优秀的团队。谷歌构建完善的智能生态圈,将AI渗透到每个产品中,抱着提升服务质量、改变人类生活习惯与效率的使命,将省却下来的时间去做更有意义的事。
AI终极目标为模仿大脑操作,GPU促进AI普及,但三大难题仍需解决
人工智能的最终目标就是要模仿人类大脑的思考和操作,但现在较成熟的监督学习(Supervised Learning)却不是走这个模式。本质上现在的深度学习(Deep Learning)与20年前的研究区别不大,不过现在的神经网络(Neural Networks)能够部署更多层数、使用更大量的数据集去训练模型和在原来的算法基础上作出更多的附加算法和改良。而GPU的使用也促进了算法的多样化和增加了找到最优化解决方案的概率。但最终无监督学习(Unsupervised Learning)才是人类大脑最自然的学习方式。
我们认为在过去5-10年里,人工智能得以商业化和普及,主要鉴于计算能力的快速增加:1)摩尔定律(Moore’s Law)的突破,让硬件价格加速下降;2)云计算的普及,以及3)GPU的使用让多维计算能力提升,都大大促进了AI的商业化。
机器学习目前存在的三大难题:
1、需要依靠大量数据与样本去训练和学习;
2、在特定的板块和领域里(domain and context specific)学习;
3、需要人工选择数据表达方式和学习算法以达到最优化学习。
谷歌市值给严重低估,探月业务的崛起将迎来新一个黄金十年
对于公司的盈利核心,是以人工智能驱动的搜索和广告业务。虽然广告业务依然占营收的90%,但随着Other Bets业务在3-5年内崛起,谷歌将迎来新一个黄金十年。现在市场上一直将Facebook与谷歌对标。谷歌2017年PE为19x,相对于FB的22x,我们认为谷歌给严重低估。谷歌广告业务里,移动占比的增加相对PC占比的减少属新常态过渡期。而2B云计算和YouTube的巨大增长潜力和在人工智能的发展上对比FB亦遥遥领先。探月业务的高速营收增长也证明了谷歌的创新能力有增不减。依靠人工智能的厚积薄发和探月业务将在3-5年内逐一崛起,谷歌长期可视为VC投资组合,哪怕只有一两个项目成功,未来市值也可获较大上翻。我们认为2017年23x PE较合理,目标价格为920美元,“买入”评级。
谷歌的灵魂和骨干:人工智能技术
谷歌的人工智能业务涵盖了从硬件到软件、搜索算法、语音和图像识别、翻译、无人车技术到医疗药品研究等,是公司的灵魂和骨干。这里我们梳理一遍谷歌AI的各个业务。
1. Google Brain神经网络项目
2011年创建的项目Google Brain是很多我们熟悉的项目的摇篮,包括TensorFlow、Word Enbeddings、Smart Reply、Deepdream、Inception和Sequence-to-sequence等。深度学习对谷歌来说至关重要,在训练电脑进行图像和视频识别方面是一个非常高效的工具,能让计算机具备与人类相当的人脸判断、物体识别能力、以及自然语言分析方面的能力。相对于2014年初的寥寥几个,目前已经有超过600个谷歌的产品在使用Google Brain的技术,包括在2015年11月推出的Gmail智能回复(Smart Reply)。
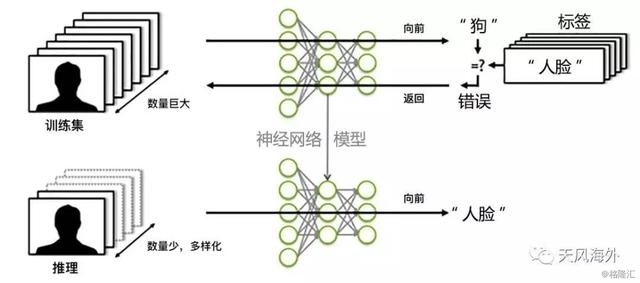
2. 第二代机器学习开源平台:TensorFlow
2015年11月谷歌宣布在Apache 2.0开源协议下开源TensorFlow。TensorFlow的运作原理是将结构张量(Tensor)所代表的数据传输至人工智能神经网中进行分析和处理,其性能比第一代人工智能系统DistBelief快达5倍,采用算法图表(computation graph)的数据流编程模式,使用Tensor统一来表示向量、矩阵、三维及以上张量。相比较大部分机器学习操作的对象都是以向量、矩阵的形式存在,很少使用高维度张量。2016年4月,谷歌旗下开发出AlphaGo围棋机器人的DeepMind公司宣布他们日后所有的研究项目都将使用TensorFlow平台。
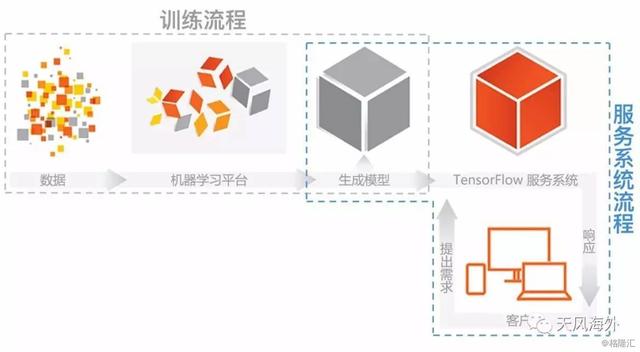
图2:谷歌TensorFlow的监督机器学习(supervised learning)训练与测试运行流程
3. 谷歌的最新搜索算法:RankBrain
2015年10月被加入谷歌搜索算法的自动化人工智能搜索系统RankBrain上线短短数月就已经成为整个算法第三重要的组成部分。RankBrain系统帮助谷歌处理搜索结果和提供相关信息,每天能够处理谷歌搜索里15%的以前无法处理的搜索请求。RankBrain通过人工智能系统将搜索请求中的多字查询,即长难句和自然语言等,转化为计算机可以理解的数学向量(vector),有效提升搜索算法理解自然语言、补全搜索语句、处理词汇关联方面的能力。
4. 谷歌无人车和谷歌司机
谷歌在2014年底提出了无方向盘、无刹车的无人车原型概念,设计为完全无人驾驶模式,主要部件包括一套由64个激光单元组成的LIDAR(Light Detection and Ranging)传感计算系统为无人车的导航和地图扫描系统提供支持,该系统价格在7.5-8.5万美元之间。无人车配备Google Chauffeur人工智能控制系统,当摄像头和LIDAR传感系统将车身周围环境扫描并输入电脑后,电脑系统根据物体的形状、大小、运动形式等特点判断物体的类别,他们通过这个方法来判定交通信号、其他车辆、自行车手和人行道上的行人等。谷歌无人驾驶项目技术负责人Dmitri Dolgov最近公开表示,谷歌做的并不单纯是无人车业务,而是制造超级司机。Dolgov认为驾驶是一项社会活动,这意味着无人车不仅需要探测并识别出路面的行人和物体,还要理解对方的行为,并作出交互反应。

图3:LiDAR扫描车身周围环境示意图
5. 机器学习和机器视觉的结合:图像识别
2013年,谷歌宣布将计算机视觉或机器视觉(Computer Vision或Machine Vision)跟机器学习技术加入其图片搜索功能中,用户只需要输入查询的物品名称就能获得相应的照片搜索结果。图片识别技术基于第一代深度学习系统DistBelief构架,核心技术是重新设计的卷积神经网络和分布式学习,其神经网络架构相较于其他团队的神经网络减少了超过10倍的参数设置,从而减少了训练过程中的过度拟合(overfitting),并降低对内存资源的占用。这项计算机视觉技术能够广泛运用于其产品中,包括图片搜索、YouTube、无人车路况识别等,只要是需要用到识别图片中有什么物体以及物体在什么位置,都能够使用这项技术。
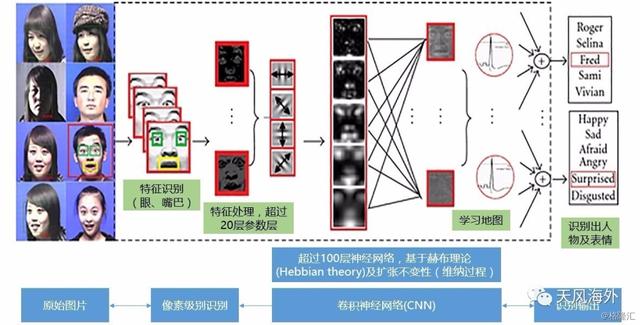
图4:谷歌图片识别原理图
6. 自然语言理解开源平台:SyntaxNet
2016年5月,谷歌开源了其基于机器学习平台TensorFlow的自然语言理解(Natural Language Understanding, NLU)平台SyntaxNet,并发布了针对英语的训练解析(English Parser)程序Parsey McParseface。SyntaxNet使用深度神经网络来解决语言歧义的问题在输入需要分析的语句后,SyntaxNet从左至右对每个单词进行处理,逐步添加分析语词之间的依存关系,每处理一处,就会产生新的可能语义依存关系。谷歌使用神经网络对每一个歧义点的语义依存关系的逻辑合理程度进行打分。Parsey McParseface对句子中单词依存关系的分析准确度达到了94%,超越了此前所有的语言分析工具,而经过专门训练的语言学家的语言分析准确度约为96-97%,如把测试集改为随机性与复杂性都更高的网络上捕捉的语言时(例如社交媒体和搜索查询),Parsey McParseface也能够达到大约90%的准确度。
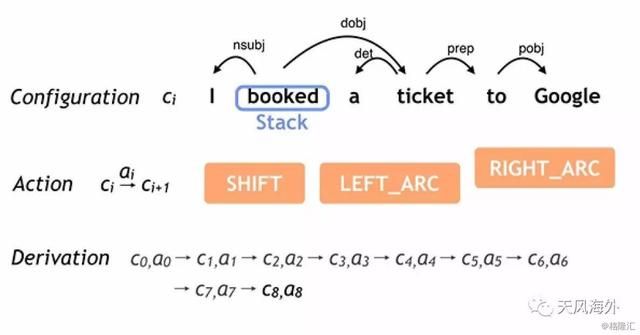
图5:SyntaxNet神经网络语义判断决策流程图
7. 自然语句理解和机器翻译:Gmail / Inbox智能回复
2015年11月推出的Gmail / Inbox智能回复就是使用深度学习(deep learning)的技术去编写邮件回复。Gmail通过机器学习技术识别需要用户进行回复的邮件,并提供三个合适的候选回复答案,用户只需要点击选项便能轻松回复邮件。智能回复系统使用的是一对递归神经网络(RNN),其中一个用来将邮件文本转化为机器代码(encoding network),一个用于推测可能回复选项(prediction network)。第一个网络将邮件文本单词进行单个处理,生成一个数字向量(a list of numbers),这个向量抓住语句核心意义,忽略修辞手法;第二个神经网络从“想法向量”开始,按每个词生成一个语法正确的智能回复。谷歌在2016年2月的财报电话会议上还提到,已经有10%的用户在使用Inbox的智能回复功能。
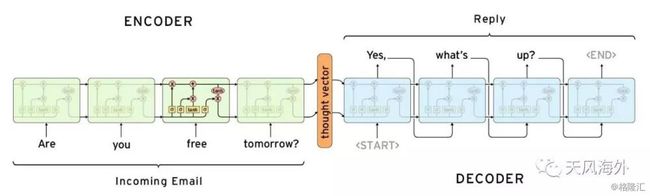
图6:谷歌Gmail智能回复神经网络
8. Allo智能回复背后的AI
在Allo中,应用程序也能通过对用户的对话记录来生成智能回复选项。Allo团队使用了一个类似“编码-解码”两步模型的方法,首先使用一个递归神经网络将对话语句一个词一个词进行编码生成对应口令(token)。然后口令进入长短期记忆神经网络(Long-short term memory, LSTM)生成一个连续向量,这个连续向量会进一步通过softmax模型生成一个离散语义结构(discretized semantic class)。Allo团队下一步就是使用第二个递归神经网络来从可选择单词组中挑出最合适的回复。这个递归神经网络也是让离散语义结构进入长短期记忆神经网络(LSTM)中,不过这次长短期记忆神经网络(LSTM)会生成完整的回复消息,生成方法也是一次一个口令,然后解码成为自然语义单词。同时,Allo的智能回复会随着用户的使用时间增加而更加反映用户的说话习惯,并且智能回复不只对英语有效,而是对所有语言都能使用。
图7:谷歌语音识别神经网络的输出示意图
9. 谷歌翻译:机器翻译系统与图像识别
谷歌在10年前发布了谷歌翻译,背后的核心算法是基于短语的机器翻译技术(Phrase-Based Machine Translation, PBMT)。谷歌此次使用的神经机器翻译系统(NMT),将整个句子视作翻译的基本输入单元。随着NMT的不断改进,研究人员又加入了外部对准模型(External Alignment Model)来标记罕见词。2015年7月,谷歌宣布其谷歌翻译应用程序在手机上已经支持超过27种语言的摄像头即时翻译。
10. DeepMind之Deep Q-Network (DQN):模仿人脑海马体的经验回放
DeepMind在2015年2月于《自然》上发表了一篇《人类控制水平的深度强化学习》的论文,描述了其开发的深度神经网络Deep Q-Network (DQN)将深度神经网络(Deep Neural Networks)与强化学习(Reinforcement Learning)相结合的深度强化学习系统(Deep Reinforcement Learning System)。Q-Network是脱离模型(model-free)的强化学习方法,常被用来对有限马尔科夫决策过程(Markov decision process)进行最优动作选择决策。
谷歌设计的这个神经网络能够完成雅达利(Atari)游戏机2600上一共49个游戏,从滚屏射击游戏River Raid,拳击游戏Boxing到3D赛车游戏Enduro等。DQN在所有游戏过程都可以使用同一套神经网络模型和参数设置,研究人员仅仅向神经网络提供了屏幕像素、具体游戏动作以及游戏分数,不包含任何关于游戏规则的先验知识。所以,DeepMind在深度强化学习方面的探索是在向通用型领域延伸的,同时也解决了AI的一大问题,就是板块和领域的局限性。人工智能的一大难题就是局限于在特定的板块和领域里学习。DeepMind这个板块和领域中性的学习算法能够帮助不同的研究团队处理大规模的复杂数据,在气候环境、物理、医药和基因学研究领域推动新的发现,甚至能够反过来辅助科学家更好了解人类大脑的学习机制。

图9:DeepMind开发的3D迷宫游戏Labyrinth界面
11. DeepMind推出文本转语音系统WaveNet
DeepMind也推出了一项在计算机语音合成领域的最新研究WaveNet。这是一个文本转语音(Text-to-Speech,TTS)系统,利用神经网络系统对原始音频波形(Raw SoundWave)建模的技术。DeepMind表示WaveNet生成的音频质量将计算机输出音频与人类自然语音差距缩小50%,超过了此前所有的文本转语音系统。WaveNet利用真实的人类声音剪辑和相应的语言、语音特征来训练其卷积神经网络(CNN),让其能够辨别这两方面(语言和语音)的音频模式。用户使用时,对WaveNet系统输入新的文本信息,也即相对应的新的语音特征,WaveNet系统会重新生成整个原始音频波形来描述这个新的文本信息。
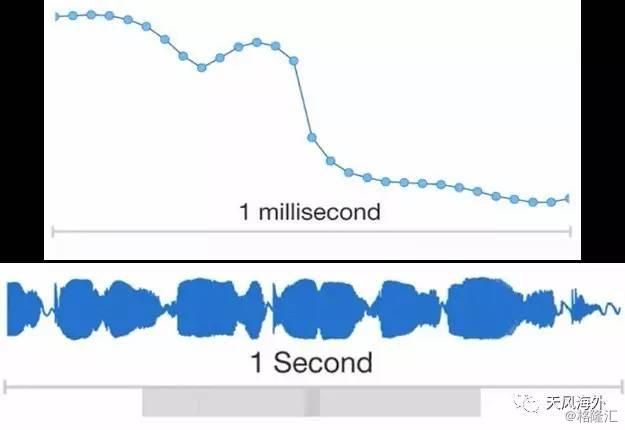
图10:WaveNet每秒要处理16000个样本
12. DeepMind运用图像识别技术的医疗探索
英国伦敦莫菲尔德眼科医院每周都会进行超过3000例的眼科光学相干断层扫描(Optical Coherence Tomography, OCT)。医院向DeepMind提供100万份病人的眼部扫描图像数据,以及常规诊疗措施。DeepMind将根据这些数据用人工智能机器学习系统进行训练。DeepMind相信通过有针对性的“视网膜特征识别”训练机器学习系统,能够应用在老年性视网膜黄斑病变(age-related macular degeneration, AMD)和糖尿病相关眼疾的识别诊断上,及早发现病变特征来为医生争取更多的治疗时间。
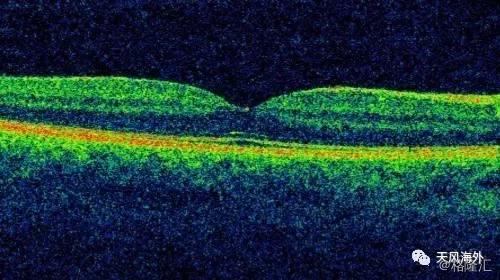
图11:视网膜扫描图像
13. 大规模机器学习应用于药物发现
2015年2月,谷歌和斯坦福大学联名提交了一篇讨论“针对药物研发的大规模多任务网络”的论文。谷歌与斯坦福大学实验室合作探讨何如使用多重来源的数据,提高在选择哪种化合物能有效治疗疾病时的准确率。更进一步,谷歌测量了来自多种疾病治疗过程中不同数量和种类的生物数据,来提高虚拟药物筛选的预测精度。研究人员使用Jeff Dean和吴恩达等人在2012年发表的大规模分布式深度神经网络(Large Scale Distributed Deep Networks)训练系统,训练集数据总量达到了以前训练量的18倍,他们总共使用了3780万个数据点,挖掘了超过200个生物实验过程,这数据集的巨大容量,让研究人员能够仔细探究模型对不同变量和输入数据的敏感性。整个论文的实验过程花费了超过5000万个CPU小时数。
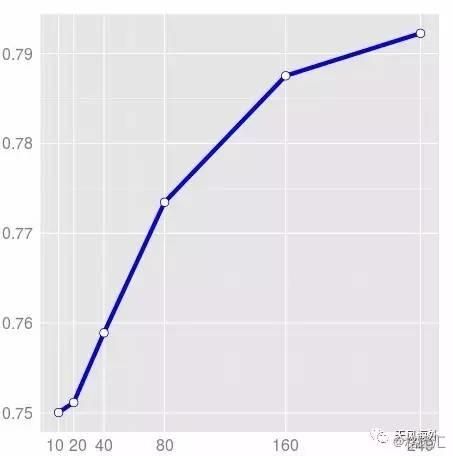
图12:实验数据的增加将虚拟药物筛选的
平均预测准确度提高至79%以上
14. 融合了计数机视觉的YouTube视频缩略图
2015年10月,谷歌宣布启动一项利用深度神经网络在图片视频分类识别方面的计算机视觉技术,为YouTube带来更好的缩略题展示。在选择视频缩略图时,程式的“质量评估模型”(quality model)对图片进行打分,谷歌现在就为这个模型加入了深度神经网络的技术。
研究人员选择用户自行上传的缩略图作为参考依据,设置了一些评价标准,包括构图良好、视觉重点明确、主题清晰等。研究人员在训练这个神经网络的时候定义了图片的“二元分类”(binary classification)标准,就是好图和坏图,类似GoogLeNet在ILSVRC挑战赛中进行物品分类设计时的思路。在使用了这个新的深度神经网络缩略图选择系统之后,研究人员进行了人工比较,他们表示65%的新缩略图要较旧缩略图更受用户欢迎。

图13:YouTube视频缩略图选择流程展示
15. 机器学习计算能力的终极解决方案:量子计算
2013年5月,谷歌宣布其与美国太空总署(NASA’s Ames Research Center)以及大学空间研究联合会(Universities Space Research Association, USRA)联合建立的量子人工智能实验室正式成立。实验室位于NASA的加州硅谷埃姆斯研究中心内(Moffett Federal Airfield),放置了谷歌从量子计算机制造商D-Wave Systems处购得的一台D-Wave 2量子计算机。谷歌的目标是借用量子计算机的强大计算能力,充分发掘人工智能与机器学习领域的技术,搭建更好的学习模型进行天气预测、疾病治疗、搜索算法改进、语音识别等方面的研究。量子计算机能够更有效的解决这样的问题,即跳过局部最优解直接寻找到最优解决方法。谷歌已经利用量子机器学习开发了一些算法,例如用户手机低电量时的识别系统,或者是对高度污染的训练数据的分辨处理。而且谷歌寻找算法的原则是不单纯利用量子计算机,而是结合常规计算方法,开发两相结合的算法。对于NASA来说,量子计算机发挥的作用要超过人们的想象。他们希望量子计算能够应用到星系大气层模拟、航空航天应用、太空探索等领域。
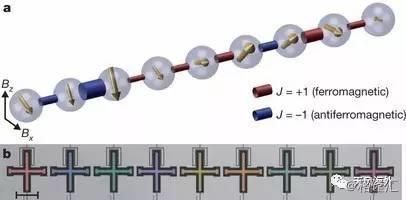
图14:谷歌量子计算机9个量子位排列示意图
16. 自行研发的AI硬件:张量处理单元TPU
目前谷歌的云平台已经具备了云端机器学习、计算机视觉API以及语言翻译API等,这样所有使用谷歌云计算平台的用户都能使用到谷歌内部一直在使用的机器学习系统。
为了支持其云平台的运行,谷歌设计了一款为人工智能运算定制的硬件设备,张量处理单元(Tensor Processing Unit, TPU)芯片。该芯片是在一颗ASIC芯片上建立的专门为机器学习和TensorFlow量身打造的集成芯片。该芯片在谷歌云平台数据中心已经使用超过一年,而且发现TPU能让机器学习每瓦特性能提高一个数量级,相当于摩尔定律中芯片效能往前推进了七年或者三代。自2016年以来,TPU运用在人工智能搜索算法RankBrain、搜索结果相关性的提高、街景Street View地图导航准确度提高等方面。在最终以4:1击败围棋世界冠军李世石的AlphaGo身上,谷歌也使用了TPU芯片。这是谷歌第一次为AI研发专门硬件。谷歌同时表示,这款芯片目前不会开放给其他公司使用,而是专门为TensorFlow所准备。

图15:谷歌TPU尺寸示意图
原网站:http://www.toutiao.com/i6373240023713579522/