时间序列(time series)数据使一种重要的结构化数据形式。
在多个时间点观察和测量到的任何事物都可以形成一段时间序列。很多时间序列是固定频率的,也就是说,数据点是根据某种规律定期出现的(比如每15秒、每5分钟、每月出现一次)。时间序列也可以是不定期的。
时间序列数据的意义取决于具体的应用场景,主要有以下几种:
- 时间戳(timestamp),特定的时刻。
- 固定时间(period),如2007年1月或2010年全年。
- 时间间隔(interval),由起始和结束时间戳表示。时期(period)可以被看作间隔(interval)的特例。
- 实验和过程时间,每个时间点都是相对于特定起始时间的一个度量。例如,从放入烤箱时起,每秒饼干的直径。
本章主要讲解前3 种时间序列。
pandas 提供了一组标准的时间序列处理工具和数据算法。因此,可以高效处理非常大的时间序列,轻松 的进行切片/切块、聚合、对定期、不定期的时间序列进行重采样等。
日期和时间数据类型及工具
python标准库包含用于日期(date)和时间(time)数据的数据类型,而且还有日历方面的功能。我们主要会用到datetime、time以及calendar模块。datetime.datetime(也可以简写为datetime)是用的最多的数据类型。
In[7]:from datetime import datetime
In[8]:now=datetime.now()
In[9]:now
Out[9]:datetime.datetime(2017, 9, 21, 11, 19, 53, 64222)
In[10]:now.year,now.month,now.day
Out[10]:(2017, 9, 21)
datetime以毫秒形式存储日期和时间。datetime.timedelta表示两个datetime对象之间的时间差。
In[11]:delta=datetime(2011,1,7)-datetime(2008,6,24,8,15)
In[12]:delta
Out[12]:datetime.timedelta(926, 56700)
In[13]:delta.days
Out[13]:926
In[14]:datetime.seconds
Out[14]:56700
可以给datetime对象加上(或减去)一个或多个timedelta,这样会产生一个新对象。
In[15]:from datetime import timedelta
In[16]:start=datetime(2011,1,7)
In[17]:start+timedelta(12)
Out[17]:datetime.datetime(2011, 1, 19, 0, 0)
In[18]:start-2*timedelta(12)
Out[18]:datetime.datetime(2010, 12, 14, 0, 0)
datatime模块中的数据类型参见表10-1。

字符串和datetime的相互转化
利用str和strftime方法(传入一个格式化字符串),datetime对象和pandas的Timestamp对象(稍后就会介绍)可以被格式化为字符串:
In[19]:stamp=datetime(2011,1,3)
In[20]:str(stmp)
Out[20]:'2011-01-03 00:00:00'
In[21]:stamp.strftime('%Y-%m-%d')
Out[21]:'2011-01-03'
表10-2列出了全部的格式化编码。datetime.strptime也可以用这些格式化编码将字符串转化为日期。
In[22]:value='2011-01-03'
In[23]:datetime.strptime(value,'%Y-%m-%d')
Out[23]:datetime.datetime(2011, 1, 3, 0, 0)
In[24]:datestrs=['7/6/2011','8/6/2011']
In[25]:[datetime.strptime(x,'%d/%m/%Y') for x in datestrs]
Out[25]:[datetime.datetime(2011, 6, 7, 0, 0), datetime.datetime(2011, 6, 8, 0, 0)]
datetime.strptime是通过已知格式进行日期解析的最佳方式。但是每次都要编写格式定义是很麻烦的事情,尤其是对一些常见的日期格式。在这种情况下,可以用dateutil这个第三方包中的parser.parse方法:
In[26]:from dateutil.parser import parse
In[27]:parse('2011-01-03')
Out[27]:datetime.datetime(2011, 1, 3, 0, 0)
dateutil可以解析几乎所有人类能够理解的日期表示形式:
In[28]:parse('Jan31,1997, 10:45 PM')
Out[28]:datetime.datetime(2017, 1, 31, 22, 45)
在国际通用格式中,日通常出现在月的前面,传入dayfirst=True即可解决这个问题:
In[29]:parse('6/12/2011',dayfirst=True)
Out[29]:datetime.datetime(2011, 12, 6, 0, 0)
pandas通常是用于处理成组日期的,不管这些日期是DataFrame的轴索引还是列。to_datetime方法可以解析多种不同的日期表示形式。对标准日期格式(如ISO8601)的解析非常快。
In[30]:datestrs
Out[31]:['7/6/2011','8/6/2011']
In[32]:pd.to_datetime(datestrs)
Out[32]:DatetimeIndex(['2011-07-06', '2011-08-06'], dtype='datetime64[ns]', freq=None)
它还可以处理缺失值(None、空字符串等)
In[33]:idx=pd.to_datetime(datestrs+[None])
In[34]:idx
Out[34]:DatetimeIndex(['2011-07-06', '2011-08-06', 'NaT'], dtype='datetime64[ns]', freq=None)
In[35]:idx[2]
Out[35];NaT
In[36]:pd.isnull(idx)
Out[36]:array([False, False, True], dtype=bool)
NaT(Not a Time)是pandas中时间戳的NA值。


datetime对象还有一些特定的当前环境(位于不同国家或使用不同语言的系统)的格式化选项。例如,德语或法语系统所使用的月份简写就与英语系统所用的不同。

时间序列基础
pandas最基本的时间序列类型就是以时间戳(通常以python字符串或datetime对象表示)为索引的Serties:
In[37]:from datetime import datetime
from pandas import Series
import numpy as np
In[38]:dates=[datetime(2012,1,2),datetime(2012,1,5),datetime(2012,1,7),datetime(2012,1,8),datetime(2012,1,10),datetime(2012,1,12)]
In[39]:ts=Series(np.random.randn(6),index=dates)
In[40]:ts
Out[40]:
2012-01-02 0.849856
2012-01-05 -0.906907
2012-01-07 -0.546352
2012-01-08 2.540495
2012-01-10 -0.848640
2012-01-12 -0.251311
dtype: float64
这些datetime对象实际上是被放在一个DatetimeIndex中的。现在变量ts就成为一个TimeSeriesl了:
In[41]:type(ts)
Out[41]:pandas.core.series.Series
In[42]:ts.index
Out[42]:
DatetimeIndex(['2012-01-02', '2012-01-05', '2012-01-07', '2012-01-08',
'2012-01-10', '2012-01-12'],
dtype='datetime64[ns]', freq=None)
索引、选取、子集构造
由于TimeSeries 是Series的一个子集,所以在索引以及数据选取方面它们的行为是一样的:
In[43]:stamp=ts.index[2]
In[44]:ts[stamp]
Out[44]:-0.54635175819596538
对于较长的时间序列,只需传入“年”或“年月”即可轻松选取数据的切片;
In[45]:longer_ts=Series(np.random.randn(1000),index=pd.date_range('1/1/2000',periods=1000))
In[46]:longer_ts
Out[46]:
2000-01-01 0.590881
2000-01-02 1.399762
2000-01-03 0.063494
2000-01-04 0.393014
2000-01-05 0.394271
2000-01-06 -0.204916
2000-01-07 -0.387580
2000-01-08 2.007172
2000-01-09 -0.632114
2000-01-10 1.450395
2000-01-11 1.117056
2000-01-12 -0.869849
2000-01-13 -0.934312
2000-01-14 0.793892
2000-01-15 1.343878
2000-01-16 -0.185210
2000-01-17 0.642998
2000-01-18 -1.364391
2000-01-19 -1.699167
2000-01-20 -1.561579
2000-01-21 -2.057630
2000-01-22 -0.116533
2000-01-23 1.113738
2000-01-24 -1.414665
2000-01-25 0.035497
2000-01-26 0.530272
2000-01-27 -0.489301
2000-01-28 1.039988
2000-01-29 -1.065946
2000-01-30 0.645302
...
2002-08-28 -1.794458
2002-08-29 -0.131113
2002-08-30 0.035095
2002-08-31 0.820795
2002-09-01 -0.007682
2002-09-02 -1.776380
2002-09-03 1.117728
2002-09-04 -0.681044
2002-09-05 -0.481970
2002-09-06 -0.013774
2002-09-07 0.303825
2002-09-08 0.126293
2002-09-09 -2.020826
2002-09-10 1.482175
2002-09-11 2.112688
2002-09-12 0.799717
2002-09-13 -0.152915
2002-09-14 -0.948012
2002-09-15 -0.002202
2002-09-16 1.018252
2002-09-17 0.876235
2002-09-18 1.122031
2002-09-19 -0.576721
2002-09-20 1.006303
2002-09-21 0.542889
2002-09-22 -1.192439
2002-09-23 0.250576
2002-09-24 -0.820256
2002-09-25 -0.295898
2002-09-26 -0.285487
Freq: D, Length: 1000, dtype: float64
In[47]:longer_ts['2001']
Out[47]:
2001-01-01 -2.113412
2001-01-02 -0.285088
2001-01-03 -0.295320
2001-01-04 -1.085161
2001-01-05 1.196209
2001-01-06 -0.588492
2001-01-07 -0.530637
2001-01-08 0.722721
2001-01-09 -0.077063
2001-01-10 -1.608190
2001-01-11 0.041290
2001-01-12 -1.246099
2001-01-13 0.918121
2001-01-14 0.322362
2001-01-15 1.108135
2001-01-16 1.025266
2001-01-17 0.607296
2001-01-18 2.026020
2001-01-19 0.923550
2001-01-20 1.336078
2001-01-21 -1.348104
2001-01-22 0.955571
2001-01-23 -0.080459
2001-01-24 0.358844
2001-01-25 -0.831299
2001-01-26 1.176252
2001-01-27 -0.373632
2001-01-28 -0.350282
2001-01-29 -1.250022
2001-01-30 -1.133462
...
2001-12-02 0.592748
2001-12-03 0.423768
2001-12-04 0.056043
2001-12-05 1.219448
2001-12-06 0.235945
2001-12-07 -0.385610
2001-12-08 1.652106
2001-12-09 0.903130
2001-12-10 -0.077634
2001-12-11 -1.846283
2001-12-12 2.018553
2001-12-13 0.754911
2001-12-14 -0.725142
2001-12-15 -0.285952
2001-12-16 0.314354
2001-12-17 0.798268
2001-12-18 0.002805
2001-12-19 1.015459
2001-12-20 -2.422554
2001-12-21 0.041050
2001-12-22 -1.337714
2001-12-23 0.244394
2001-12-24 -0.685081
2001-12-25 -1.267419
2001-12-26 -0.093063
2001-12-27 0.126119
2001-12-28 -0.302917
2001-12-29 -0.008550
2001-12-30 0.976075
2001-12-31 1.118983
Freq: D, Length: 365, dtype: float64
In[48]:longer_ts['2001-05']
Out[48]:
2001-05-01 1.260700
2001-05-02 0.546221
2001-05-03 0.203031
2001-05-04 -0.927684
2001-05-05 -0.384820
2001-05-06 0.544058
2001-05-07 -0.354518
2001-05-08 -1.132067
2001-05-09 -0.710839
2001-05-10 -0.254558
2001-05-11 -0.631291
2001-05-12 0.118105
2001-05-13 0.041881
2001-05-14 -0.641639
2001-05-15 -0.768678
2001-05-16 1.683219
2001-05-17 0.186971
2001-05-18 -1.376887
2001-05-19 1.847433
2001-05-20 -0.436165
2001-05-21 0.740447
2001-05-22 -1.965044
2001-05-23 0.571263
2001-05-24 -0.671063
2001-05-25 -0.768376
2001-05-26 0.606890
2001-05-27 -0.637426
2001-05-28 -1.981986
2001-05-29 0.234378
2001-05-30 -1.004578
2001-05-31 -0.743983
Freq: D, dtype: float64
带有重复索引的时间序列
在某些应用场景中,可能会存在多个观测数据落在同一个时间点上的情况。
In[49]:dates=pd.DatetimeIndex(['1/1/2000','1/2/2000','1/2/2000','1/2/2000','1/3/2000'])
In[50]:dup_ts=Series(np.arange(5),index=dates)
In[51]:dup_ts
Out[51]:
2000-01-01 0
2000-01-02 1
2000-01-02 2
2000-01-02 3
2000-01-03 4
dtype: int32
对这个时间序列进行索引,要么产生标量值,要么产生切片,具体要看所选的时间点是否重复:
In[52]:dup_ts['1/3/2000'] # 不重复
Out[52]:4
In[53]:dup_ts['1/2/2000'] #重复
Out[53]:
2000-01-02 1
2000-01-02 2
2000-01-02 3
dtype: int32
假设你想要对具有非唯一时间戳的数据进行聚合。一个办法就是使用groupby,并传入level=0(索引的唯一一层!):
In[54]:grouped=dup_ts.groupby(level=0)
In[55]:groupby.mean()
Out[55]:
2000-01-01 0
2000-01-02 2
2000-01-03 4
dtype: int32
In[56]:grouped.count()
Out[56]:
2000-01-01 1
2000-01-02 3
2000-01-03 1
dtype: int64
日期的范围、频率、以及移动
pandas 中的时间序列一般被认为是不规则的,也就是说,它们没有固定的频率。但它以某种相对固定的频率进行分析时,比如每日、每月、每15分钟等(这样自然会在时间序列中引入缺失值)。
pandas 有一套标准时间序列频率以及用于重采样、频率推断、生成固定频率日期范围的工具。
例如,我们可以将之前那个时间序列转化为一个具有固定频率(每日)的是按序列,只需调用resample即可:
In[57]:ts
Out[57]:
2012-01-02 0.145269
2012-01-05 1.061321
2012-01-07 0.341192
2012-01-08 0.910146
2012-01-10 -0.366761
2012-01-12 0.202229
dtype: float64
In[58]:ts.resample('D')
## Out[58]:???
DatetimeIndexResampler [freq=, axis=0, closed=left, label=left, convention=start, base=0]
生成日期范围
pandas.date_range可用于生成指定长度的DatatimeIndex:
In[59]:index=pd.date_range('4/1/2012','6/1/2012')
In[60]:index
Out[60]:
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20',
'2012-04-21', '2012-04-22', '2012-04-23', '2012-04-24',
'2012-04-25', '2012-04-26', '2012-04-27', '2012-04-28',
'2012-04-29', '2012-04-30', '2012-05-01', '2012-05-02',
'2012-05-03', '2012-05-04', '2012-05-05', '2012-05-06',
'2012-05-07', '2012-05-08', '2012-05-09', '2012-05-10',
'2012-05-11', '2012-05-12', '2012-05-13', '2012-05-14',
'2012-05-15', '2012-05-16', '2012-05-17', '2012-05-18',
'2012-05-19', '2012-05-20', '2012-05-21', '2012-05-22',
'2012-05-23', '2012-05-24', '2012-05-25', '2012-05-26',
'2012-05-27', '2012-05-28', '2012-05-29', '2012-05-30',
'2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')
默认情况下,date_range会产生按天计算的时间点。如果只传入起始或结束日期,那就还得传入一个表示一段时间的数字:
In[61]:pd.date_range(star='4/1/2012',periods=20)
Out[61]:
DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
'2012-04-05', '2012-04-06', '2012-04-07', '2012-04-08',
'2012-04-09', '2012-04-10', '2012-04-11', '2012-04-12',
'2012-04-13', '2012-04-14', '2012-04-15', '2012-04-16',
'2012-04-17', '2012-04-18', '2012-04-19', '2012-04-20'],
dtype='datetime64[ns]', freq='D')
In[62]:pd.date_range(end='6/1/2012',periods=20)
Out[62]:
DatetimeIndex(['2012-05-13', '2012-05-14', '2012-05-15', '2012-05-16',
'2012-05-17', '2012-05-18', '2012-05-19', '2012-05-20',
'2012-05-21', '2012-05-22', '2012-05-23', '2012-05-24',
'2012-05-25', '2012-05-26', '2012-05-27', '2012-05-28',
'2012-05-29', '2012-05-30', '2012-05-31', '2012-06-01'],
dtype='datetime64[ns]', freq='D')
起始和结束日期定义了日期索引的严格边界。例如,如果你想要生成一个由每月最后一个工作日组成的日期索引,可以传入“BM”频率(表示business end of month),这样就只会包含时间间隔内(或刚好在边界上的)符合频率要求的日期:
In[63]:pd.date_tange('1/1/2000','12/1/2000',freq='BM')
Out[63]:
DatetimeIndex(['2000-01-31', '2000-02-29', '2000-03-31', '2000-04-28',
'2000-05-31', '2000-06-30', '2000-07-31', '2000-08-31',
'2000-09-29', '2000-10-31', '2000-11-30'],
dtype='datetime64[ns]', freq='BM')
date_range默认会保留起始和结束时间戳的时间信息(如果有的话):
In[64]:pd.date_range('1/1/2000','12/1/2000',periods=5)
Out[64]:
DatetimeIndex(['2000-01-01 12:56:31', '2000-01-02 12:56:31',
'2000-01-03 12:56:31', '2000-01-04 12:56:31',
'2000-01-05 12:56:31'],
dtype='datetime64[ns]', freq='D')
有时,虽然起始和结束日期带有时间信息,但你希望产生一组被规范化(normalize)到午夜的时间戳。normalize选项即可实现该功能:
In[65]:pd.date_range('5/2/2012 12:56:31',periods=5,normalize=True)
Out[55]:
DatetimeIndex(['2012-05-02', '2012-05-03', '2012-05-04', '2012-05-05',
'2012-05-06'],
dtype='datetime64[ns]', freq='D')
频率和日期偏移量
pandas中的频率是由一个基础频率(base frequency)和一个乘数组成的。基础频率通常以一个字符串别名表示,比如“M”表示月,“H”表示小时。
对于每一个基础频率,都有一个被称为日期偏移量(data offset)的对象那个与之对应。
例如,按小时计算的频率可以用Hour类表示:
In[66]:from pandas.tseries.offsets import Hour,Minute
In[67]:four_hours=Hour(4)
In[68];four_hours
Out[68]:<4 * Hours>
一般来说,无须显示创建这样的对象,只需使用诸如“H”或“4H”这样的字符串别名即可。在基础频率前面放上一个整数即可创建倍数:
In[69]:pd.date_range('1/1/2000','1/3/2000 23:59',freq='4h')
Out[69]:
DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 04:00:00',
'2000-01-01 08:00:00', '2000-01-01 12:00:00',
'2000-01-01 16:00:00', '2000-01-01 20:00:00',
'2000-01-02 00:00:00', '2000-01-02 04:00:00',
'2000-01-02 08:00:00', '2000-01-02 12:00:00',
'2000-01-02 16:00:00', '2000-01-02 20:00:00',
'2000-01-03 00:00:00', '2000-01-03 04:00:00',
'2000-01-03 08:00:00', '2000-01-03 12:00:00',
'2000-01-03 16:00:00', '2000-01-03 20:00:00'],
dtype='datetime64[ns]', freq='4H')
大部分偏移量对象都可通过加法进行连接:
In[70]:Hour(2)+Minute(30)
Out[70]:<150 * Minutes>
同理,也可以传入频率字符串(如“2h30min”),这种字符串可以被高效地解析为等效的表达式:
In[71]:pd.date_range('1/1/2000',periods=10,freq='1h30min')
Out[71]:
DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 01:30:00',
'2000-01-01 03:00:00', '2000-01-01 04:30:00',
'2000-01-01 06:00:00', '2000-01-01 07:30:00',
'2000-01-01 09:00:00', '2000-01-01 10:30:00',
'2000-01-01 12:00:00', '2000-01-01 13:30:00'],
dtype='datetime64[ns]', freq='90T')
有些频率所描述的时间点并不是均匀分隔的。例如,“M”(日历月末)和“BM”(每月最后一个工作日)就取决于每月的天数,还要考虑月末是不是周末。
由于没有更好的术语,将这些成为锚点偏移量(anchored offset)
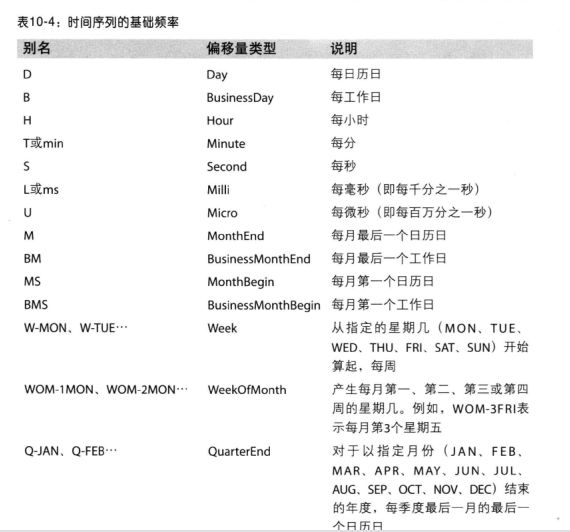
表10-4列出了pandas中的频率代码和日期偏移量表。

WOM日期
WOM(Week Of Month)是一种非常实用的频率类,它以WOM开头。它使你能够获得诸如“每个月第3个星期五”之类的日期。
In[72]:rng=pd.date_range('1/1/2012','9/1/2012',freq='WOM-3FRI')
In[73]:rng
Out[73]:
[Timestamp('2012-01-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-02-17 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-03-16 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-04-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-05-18 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-06-15 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-07-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2012-08-17 00:00:00', freq='WOM-3FRI')]
美国的股票期权交易人会意识到这些日子就是标准的月度到期日。
移动(超前和滞后)数据
移动(shifting)指的是沿着时间轴将数据前移或后移。Series和DataFrame都有一个shift方法用于执行单纯的前移和后移操作,保持索引不变:
In[74]:ts=Series(np.random.randn(4),index=pd.date_range('1/1/2000',periods=4,freq='M'))
In[75]:ts
Out[75]:
2000-01-31 0.299618
2000-02-29 0.626409
2000-03-31 -0.272730
2000-04-30 -0.932787
Freq: M, dtype: float64
In[76]:ts.shift(2)
Out[76]:
2000-01-31 NaN
2000-02-29 NaN
2000-03-31 0.299618
2000-04-30 0.626409
Freq: M, dtype: float64
In[77]:ts.shift(-2)
Out[77]:
2000-01-31 -0.272730
2000-02-29 -0.932787
2000-03-31 NaN
2000-04-30 NaN
Freq: M, dtype: float64
shift通常用于计算一个时间序列或多个时间序列(如DataFrame的列)中的百分比变化。可以这样表达:
In[78]:ts/ts.shift(1)-1
Out[78]:
2000-01-31 NaN
2000-02-29 1.090689
2000-03-31 -1.435387
2000-04-30 2.420184
Freq: M, dtype: float64
由于单纯的移位操作不会修改索引,所以部分数据会被丢弃。因此,如果频率已知,则可以将其传递给shift以便实现对时间戳进行位移而不是对数据进行简单位移:
In[79]:ts.shift(2,freq='M')
Out[79]:
2000-03-31 0.299618
2000-04-30 0.626409
2000-05-31 -0.272730
2000-06-30 -0.932787
Freq: M, dtype: float64
In[80]:ts.shift(3,freq='D')
Out[80]:
2000-02-03 0.299618
2000-03-03 0.626409
2000-04-03 -0.272730
2000-05-03 -0.932787
dtype: float64
In[81]:ts.shift(1,freq='3D')
Out[81]:2000-02-03 0.299618
2000-03-03 0.626409
2000-04-03 -0.272730
2000-05-03 -0.932787
dtype: float64
In[82]:ts.shift(1,freq='90T')
Out[82]:
2000-01-31 01:30:00 0.299618
2000-02-29 01:30:00 0.626409
2000-03-31 01:30:00 -0.272730
2000-04-30 01:30:00 -0.932787
Freq: M, dtype: float64
通过偏移量对日期进行位移
pandas 的日期偏移量还可以用在datetime或Timestamp对象上: